 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Autoencoders for P-wave Detection on Strong Motion Earthquake Spectrograms
Jan 09, 2026Accurate P-wave detection is critical for earthquake early warning, yet strong-motion records pose challenges due to high noise levels, limited labeled data, and complex waveform characteristics. This study reframes P-wave arrival detection as a self-supervised anomaly detection task to evaluate how architectural variations regulate the trade-off between reconstruction fidelity and anomaly discrimination. Through a comprehensive grid search of 492 Variational Autoencoder configurations, we show that while skip connections minimize reconstruction error (Mean Absolute Error approximately 0.0012), they induce "overgeneralization", allowing the model to reconstruct noise and masking the detection signal. In contrast, attention mechanisms prioritize global context over local detail and yield the highest detection performance with an area-under-the-curve of 0.875. The attention-based Variational Autoencoder achieves an area-under-the-curve of 0.91 in the 0 to 40-kilometer near-source range, demonstrating high suitability for immediate early warning applications. These findings establish that architectural constraints favoring global context over pixel-perfect reconstruction are essential for robust, self-supervised P-wave detection.
How to Augment for Atmospheric Turbulence Effects on Thermal Adapted Object Detection Models?
May 10, 2024Atmospheric turbulence poses a significant challenge to the performance of object detection models. Turbulence causes distortions, blurring, and noise in images by bending and scattering light rays due to variations in the refractive index of air. This results in non-rigid geometric distortions and temporal fluctuations in the electromagnetic radiation received by optical systems. This paper explores the effectiveness of turbulence image augmentation techniques in improving the accuracy and robustness of thermal-adapted and deep learning-based object detection models under atmospheric turbulence. Three distinct approximation-based turbulence simulators (geometric, Zernike-based, and P2S) are employed to generate turbulent training and test datasets. The performance of three state-of-the-art deep learning-based object detection models: RTMDet-x, DINO-4scale, and YOLOv8-x, is employed on these turbulent datasets with and without turbulence augmentation during training. The results demonstrate that utilizing turbulence-specific augmentations during model training can significantly improve detection accuracy and robustness against distorted turbulent images. Turbulence augmentation enhances performance even for a non-turbulent test set.
FuseFormer: A Transformer for Visual and Thermal Image Fusion
Feb 01, 2024
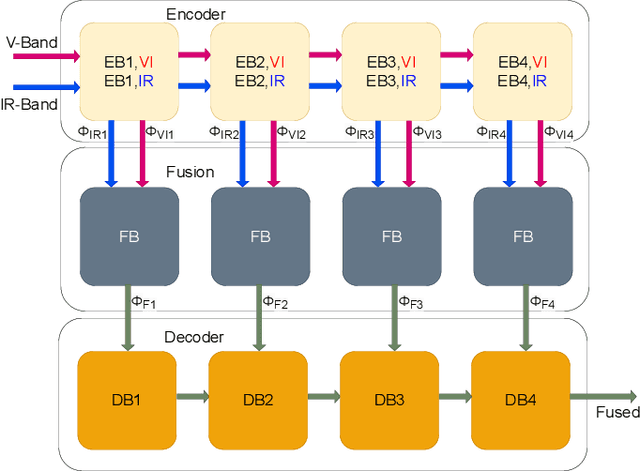
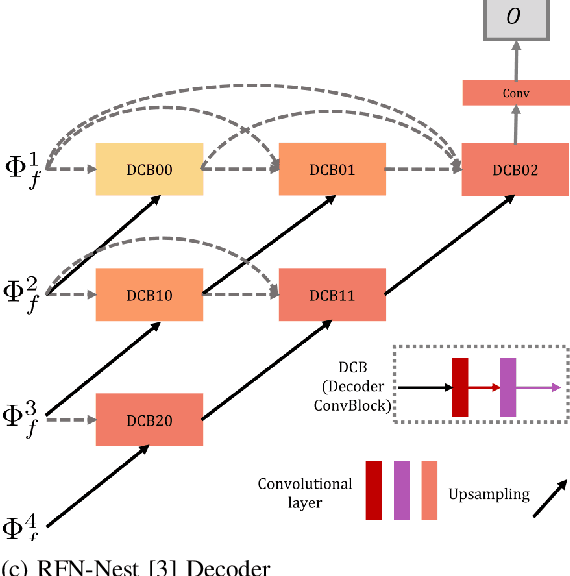
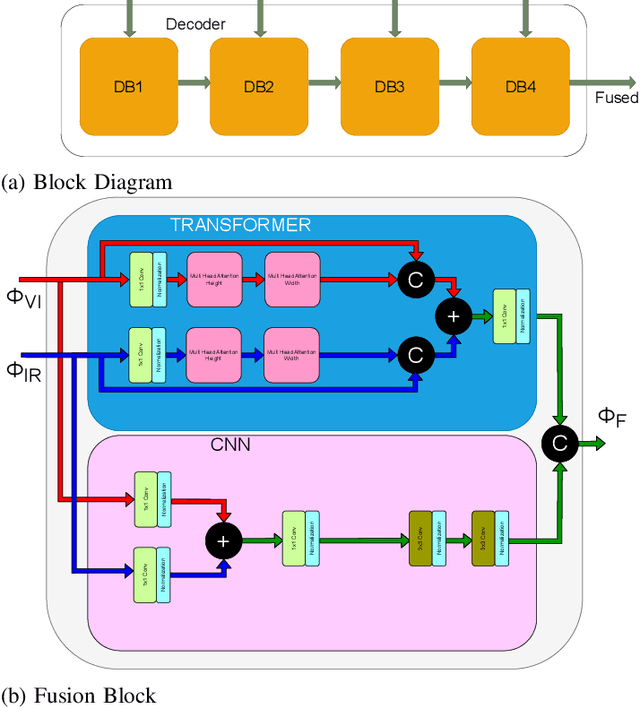
Image fusion is the process of combining images from different sensors into a single image that incorporates all relevant information. The majority of state-of-the-art image fusion techniques use deep learning methods to extract meaningful features; however, they primarily integrate local features without considering the image's broader context. To overcome this limitation, Transformer-based models have emerged as a promising solution, aiming to capture general context dependencies through attention mechanisms. Since there is no ground truth for image fusion, the loss functions are structured based on evaluation metrics, such as the structural similarity index measure (SSIM). By doing so, we create a bias towards the SSIM and, therefore, the input visual band image. The objective of this study is to propose a novel methodology for image fusion that mitigates the limitations associated with using evaluation metrics as loss functions. Our approach integrates a transformer-based multi-scale fusion strategy, which adeptly addresses both local and global context information. This integration not only refines the individual components of the image fusion process but also significantly enhances the overall efficacy of the method. Our proposed method follows a two-stage training approach, where an auto-encoder is initially trained to extract deep features at multiple scales at the first stage. For the second stage, we integrate our fusion block and change the loss function as mentioned. The multi-scale features are fused using a combination of Convolutional Neural Networks (CNNs) and Transformers. The CNNs are utilized to capture local features, while the Transformer handles the integration of general context features.
Sequence Models for Drone vs Bird Classification
Jul 21, 2022
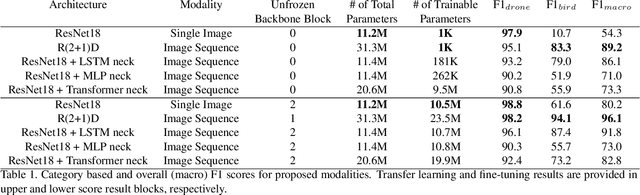
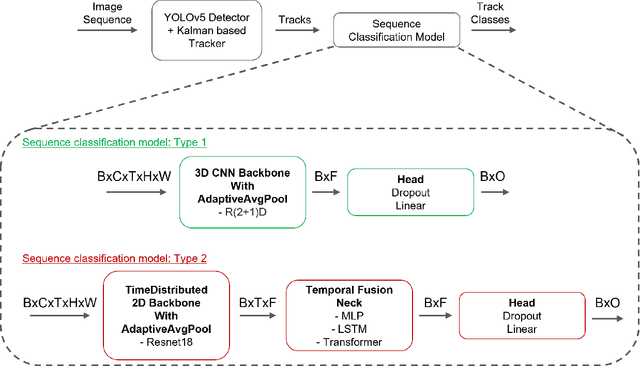

Drone detection has become an essential task in object detection as drone costs have decreased and drone technology has improved. It is, however, difficult to detect distant drones when there is weak contrast, long range, and low visibility. In this work, we propose several sequence classification architectures to reduce the detected false-positive ratio of drone tracks. Moreover, we propose a new drone vs. bird sequence classification dataset to train and evaluate the proposed architectures. 3D CNN, LSTM, and Transformer based sequence classification architectures have been trained on the proposed dataset to show the effectiveness of the proposed idea. As experiments show, using sequence information, bird classification and overall F1 scores can be increased by up to 73% and 35%, respectively. Among all sequence classification models, R(2+1)D-based fully convolutional model yields the best transfer learning and fine-tuning results.
Augmentation of Atmospheric Turbulence Effects on Thermal Adapted Object Detection Models
Apr 19, 2022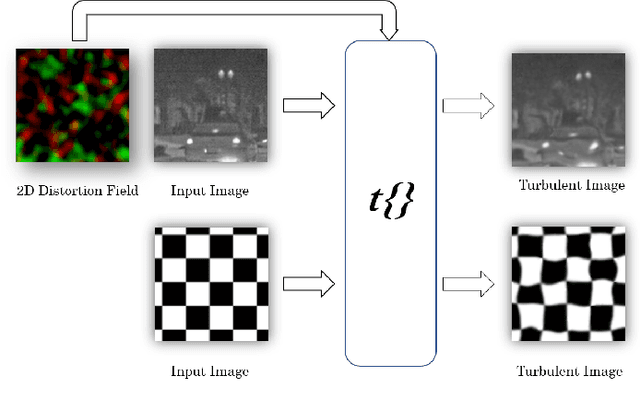
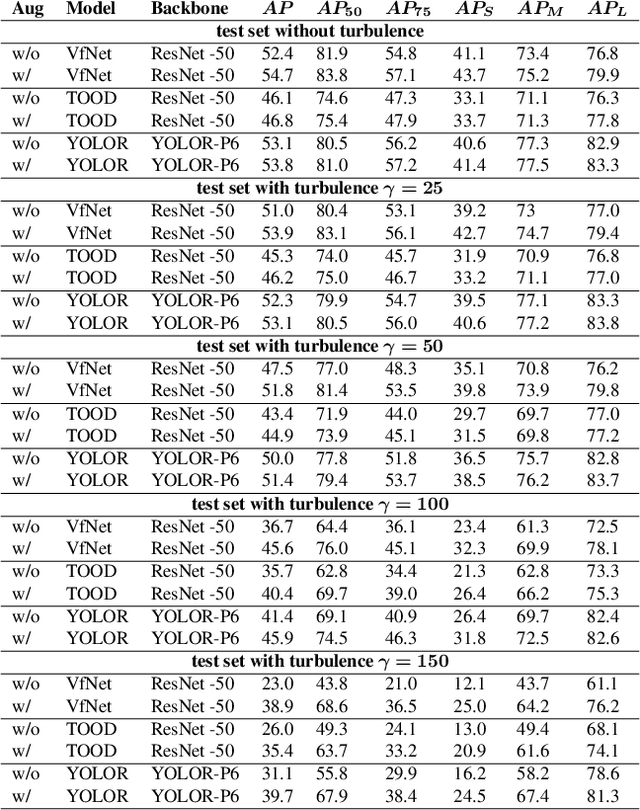


Atmospheric turbulence has a degrading effect on the image quality of long-range observation systems. As a result of various elements such as temperature, wind velocity, humidity, etc., turbulence is characterized by random fluctuations in the refractive index of the atmosphere. It is a phenomenon that may occur in various imaging spectra such as the visible or the infrared bands. In this paper, we analyze the effects of atmospheric turbulence on object detection performance in thermal imagery. We use a geometric turbulence model to simulate turbulence effects on a medium-scale thermal image set, namely "FLIR ADAS v2". We apply thermal domain adaptation to state-of-the-art object detectors and propose a data augmentation strategy to increase the performance of object detectors which utilizes turbulent images in different severity levels as training data. Our results show that the proposed data augmentation strategy yields an increase in performance for both turbulent and non-turbulent thermal test images.
A Survey on Infrared Image and Video Sets
Mar 16, 2022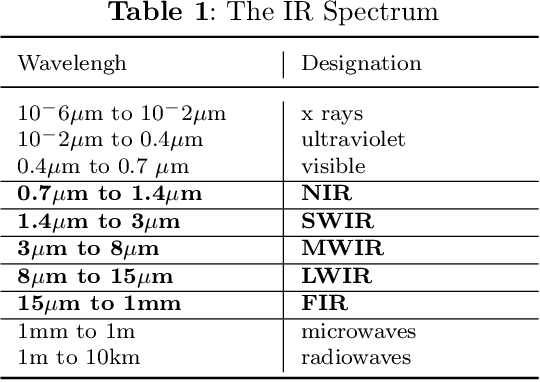
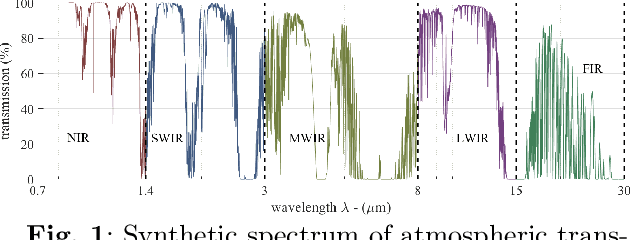
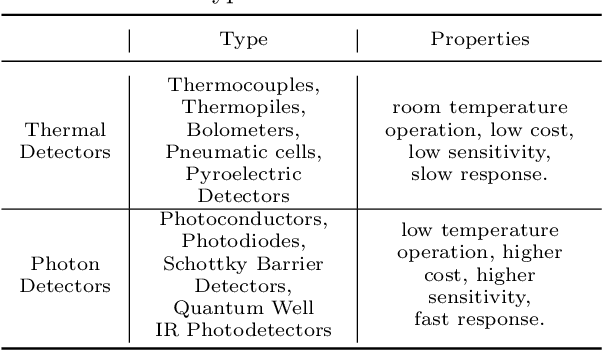
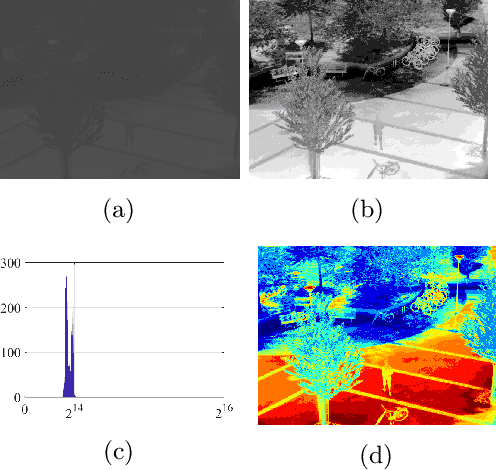
In this survey, we compile a list of publicly available infrared image and video sets for artificial intelligence and computer vision researchers. We mainly focus on IR image and video sets which are collected and labelled for computer vision applications such as object detection, object segmentation, classification, and motion detection. We categorize 92 different publicly available or private sets according to their sensor types, image resolution, and scale. We describe each and every set in detail regarding their collection purpose, operation environment, optical system properties, and area of application. We also cover a general overview of fundamental concepts that relate to IR imagery, such as IR radiation, IR detectors, IR optics and application fields. We analyse the statistical significance of the entire corpus from different perspectives. We believe that this survey will be a guideline for computer vision and artificial intelligence researchers that are interested in working with the spectra beyond the visible domain.
Filter design for small target detection on infrared imagery using normalized-cross-correlation layer
Jun 15, 2020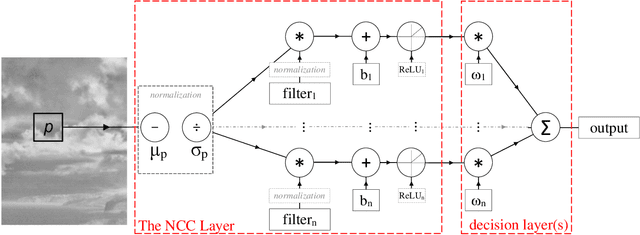
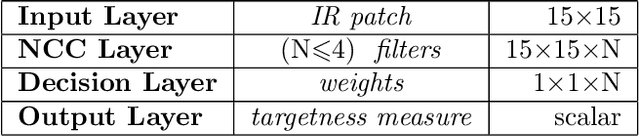

In this paper, we introduce a machine learning approach to the problem of infrared small target detection filter design. For this purpose, similarly to a convolutional layer of a neural network, the normalized-cross-correlational (NCC) layer, which we utilize for designing a target detection/recognition filter bank, is proposed. By employing the NCC layer in a neural network structure, we introduce a framework, in which supervised training is used to calculate the optimal filter shape and the optimum number of filters required for a specific target detection/recognition task on infrared images. We also propose the mean-absolute-deviation NCC (MAD-NCC) layer, an efficient implementation of the proposed NCC layer, designed especially for FPGA systems, in which square root operations are avoided for real-time computation. As a case study we work on dim-target detection on mid-wave infrared imagery and obtain the filters that can discriminate a dim target from various types of background clutter, specific to our operational concept.
A Hybrid Framework for Matching Printing Design Files to Product Photos
Jun 09, 2020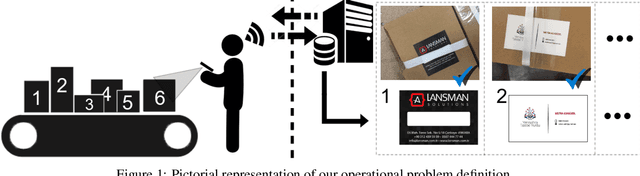


We propose a real-time image matching framework, which is hybrid in the sense that it uses both hand-crafted features and deep features obtained from a well-tuned deep convolutional network. The matching problem, which we concentrate on, is specific to a certain application, that is, printing design to product photo matching. Printing designs are any kind of template image files, created using a design tool, thus are perfect image signals. However, photographs of a printed product suffer many unwanted effects, such as uncontrolled shooting angle, uncontrolled illumination, occlusions, printing deficiencies in color, camera noise, optic blur, et cetera. For this purpose, we create an image set that includes printing design and corresponding product photo pairs with collaboration of an actual printing facility. Using this image set, we benchmark various hand-crafted and deep features for matching performance and propose a framework in which deep learning is utilized with highest contribution, but without disabling real-time operation using an ordinary desktop computer.
A Survey on Deep Learning-based Architectures for Semantic Segmentation on 2D images
Dec 21, 2019


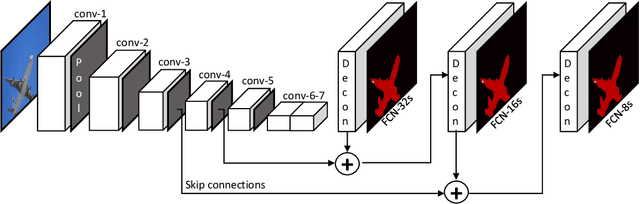
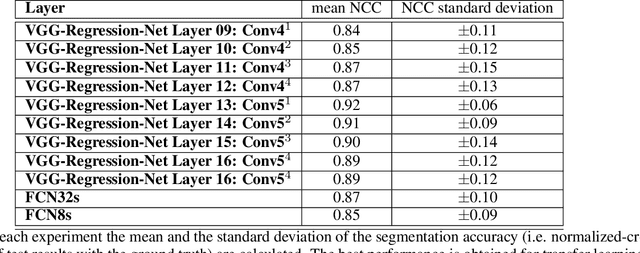
Semantic segmentation is the pixel-wise labelling of an image. Since the problem is defined at the pixel level, determining image class labels only is not acceptable, but localising them at the original image pixel resolution is necessary. Boosted by the extraordinary ability of convolutional neural networks (CNN) in creating semantic, high level and hierarchical image features; excessive numbers of deep learning-based 2D semantic segmentation approaches have been proposed within the last decade. In this survey, we mainly focus on the recent scientific developments in semantic segmentation, specifically on deep learning-based methods using 2D images. We started with an analysis of the public image sets and leaderboards for 2D semantic segmantation, with an overview of the techniques employed in performance evaluation. In examining the evolution of the field, we chronologically categorised the approaches into three main periods, namely pre-and early deep learning era, the fully convolutional era, and the post-FCN era. We technically analysed the solutions put forward in terms of solving the fundamental problems of the field, such as fine-grained localisation and scale invariance. Before drawing our conclusions, we present a table of methods from all mentioned eras, with a brief summary of each approach that explains their contribution to the field. We conclude the survey by discussing the current challenges of the field and to what extent they have been solved.
Defining Image Memorability using the Visual Memory Schema
Mar 05, 2019

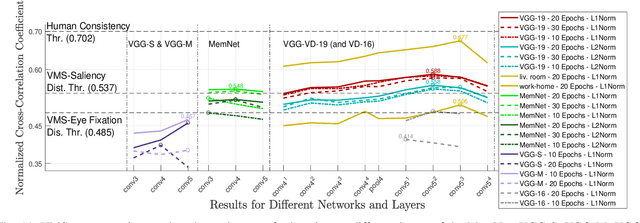

Memorability of an image is a characteristic determined by the human observers' ability to remember images they have seen. Yet recent work on image memorability defines it as an intrinsic property that can be obtained independent of the observer. {The current study aims to enhance our understanding and prediction of image memorability, improving upon existing approaches by incorporating the properties of cumulative human annotations.} We propose a new concept called the Visual Memory Schema (VMS) referring to an organisation of image components human observers share when encoding and recognising images. The concept of VMS is operationalised by asking human observers to define memorable regions of images they were asked to remember during an episodic memory test. We then statistically assess the consistency of VMSs across observers for either correctly or incorrectly recognised images. The associations of the VMSs with eye fixations and saliency are analysed separately as well. Lastly, we adapt various deep learning architectures for the reconstruction and prediction of memorable regions in images and analyse the results when using transfer learning at the outputs of different convolutional network layers.