 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuseFormer: A Transformer for Visual and Thermal Image Fusion
Paper and Code

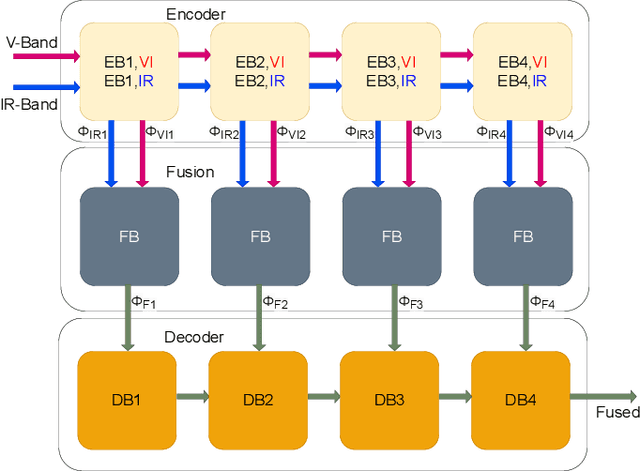
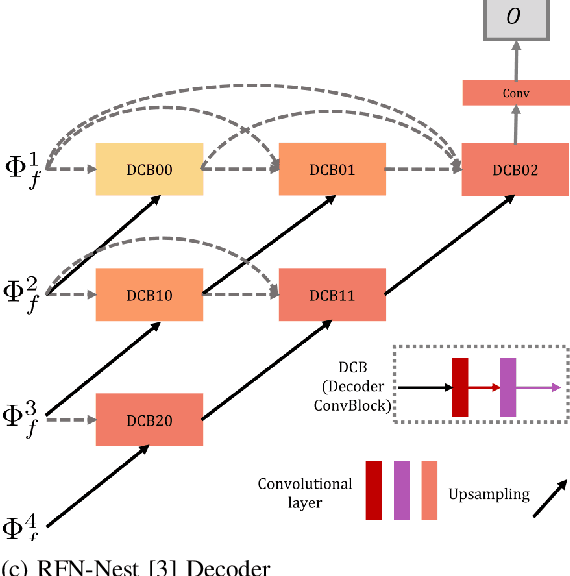
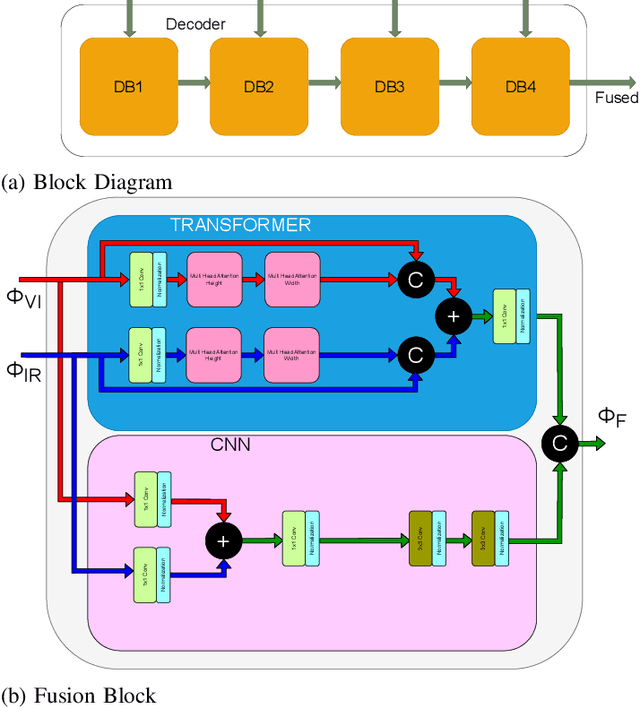
Image fusion is the process of combining images from different sensors into a single image that incorporates all relevant information. The majority of state-of-the-art image fusion techniques use deep learning methods to extract meaningful features; however, they primarily integrate local features without considering the image's broader context. To overcome this limitation, Transformer-based models have emerged as a promising solution, aiming to capture general context dependencies through attention mechanisms. Since there is no ground truth for image fusion, the loss functions are structured based on evaluation metrics, such as the structural similarity index measure (SSIM). By doing so, we create a bias towards the SSIM and, therefore, the input visual band image. The objective of this study is to propose a novel methodology for image fusion that mitigates the limitations associated with using evaluation metrics as loss functions. Our approach integrates a transformer-based multi-scale fusion strategy, which adeptly addresses both local and global context information. This integration not only refines the individual components of the image fusion process but also significantly enhances the overall efficacy of the method. Our proposed method follows a two-stage training approach, where an auto-encoder is initially trained to extract deep features at multiple scales at the first stage. For the second stage, we integrate our fusion block and change the loss function as mentioned. The multi-scale features are fused using a combination of Convolutional Neural Networks (CNNs) and Transformers. The CNNs are utilized to capture local features, while the Transformer handles the integration of general context features.