 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Memorable Images Based on Human Visual Memory Schemas
May 06, 2020


This research study proposes using Generative Adversarial Networks (GAN) that incorporate a two-dimensional measure of human memorability to generate memorable or non-memorable images of scenes. The memorability of the generated images is evaluated by modelling Visual Memory Schemas (VMS), which correspond to mental representations that human observers use to encode an image into memory. The VMS model is based upon the results of memory experiments conducted on human observers, and provides a 2D map of memorability. We impose a memorability constraint upon the latent space of a GAN by employing a VMS map prediction model as an auxiliary loss. We assess the difference in memorability between images generated to be memorable or non-memorable through an independent computational measure of memorability, and additionally assess the effect of memorability on the realness of the generated images.
Defining Image Memorability using the Visual Memory Schema
Mar 05, 2019

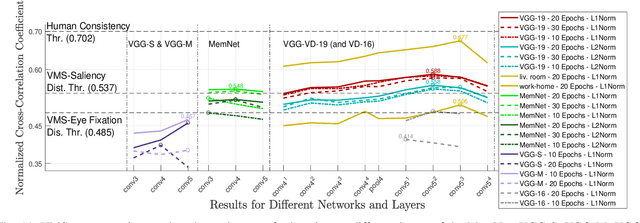

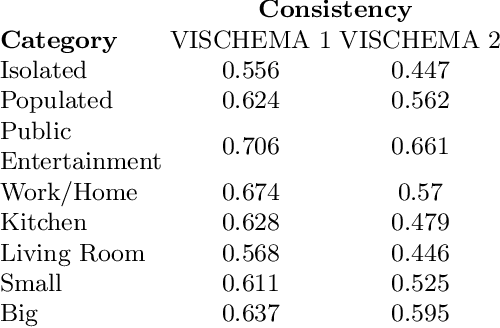
Memorability of an image is a characteristic determined by the human observers' ability to remember images they have seen. Yet recent work on image memorability defines it as an intrinsic property that can be obtained independent of the observer. {The current study aims to enhance our understanding and prediction of image memorability, improving upon existing approaches by incorporating the properties of cumulative human annotations.} We propose a new concept called the Visual Memory Schema (VMS) referring to an organisation of image components human observers share when encoding and recognising images. The concept of VMS is operationalised by asking human observers to define memorable regions of images they were asked to remember during an episodic memory test. We then statistically assess the consistency of VMSs across observers for either correctly or incorrectly recognised images. The associations of the VMSs with eye fixations and saliency are analysed separately as well. Lastly, we adapt various deep learning architectures for the reconstruction and prediction of memorable regions in images and analyse the results when using transfer learning at the outputs of different convolutional network layers.