 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Sequence Models for Predicting Average Shear Wave Velocity from Strong Motion Records
Mar 07, 2025This study explores the use of deep learning for predicting the time averaged shear wave velocity in the top 30 m of the subsurface ($V_{s30}$) at strong motion recording stations in T\"urkiye. $V_{s30}$ is a key parameter in site characterization and, as a result for seismic hazard assessment. However, it is often unavailable due to the lack of direct measurements and is therefore estimated using empirical correlations. Such correlations however are commonly inadequate in capturing complex, site-specific variability and this motivates the need for data-driven approaches. In this study, we employ a hybrid deep learning model combining convolutional neural networks (CNNs) and long short-term memory (LSTM) networks to capture both spatial and temporal dependencies in strong motion records. Furthermore, we explore how using different parts of the signal influence our deep learning model. Our results suggest that the hybrid approach effectively learns complex, nonlinear relationships within seismic signals. We observed that an improved P-wave arrival time model increased the prediction accuracy of $V_{s30}$. We believe the study provides valuable insights into improving $V_{s30}$ predictions using a CNN-LSTM framework, demonstrating its potential for improving site characterization for seismic studies. Our codes are available via this repo: https://github.com/brsylmz23/CNNLSTM_DeepEQ
Deep Learning-based Average Shear Wave Velocity Prediction using Accelerometer Records
Aug 27, 2024



Assessing seismic hazards and thereby designing earthquake-resilient structures or evaluating structural damage that has been incurred after an earthquake are important objectives in earthquake engineering. Both tasks require critical evaluation of strong ground motion records, and the knowledge of site conditions at the earthquake stations plays a major role in achieving the aforementioned objectives. Site conditions are generally represented by the time-averaged shear wave velocity in the upper 30 meters of the geological materials (Vs30). Several strong motion stations lack Vs30 measurements resulting in potentially inaccurate assessment of seismic hazards and evaluation of ground motion records. In this study, we present a deep learning-based approach for predicting Vs30 at strong motion station locations using three-channel earthquake records. For this purpose, Convolutional Neural Networks (CNNs) with dilated and causal convolutional layers are used to extract deep features from accelerometer records collected from over 700 stations located in Turkey. In order to overcome the limited availability of labeled data, we propose a two-phase training approach. In the first phase, a CNN is trained to estimate the epicenters, for which ground truth is available for all records. After the CNN is trained, the pre-trained encoder is fine-tuned based on the Vs30 ground truth. The performance of the proposed method is compared with machine learning models that utilize hand-crafted features. The results demonstrate that the deep convolutional encoder based Vs30 prediction model outperforms the machine learning models that rely on hand-crafted features.
Infrared Domain Adaptation with Zero-Shot Quantization
Aug 25, 2024Quantization is one of the most popular techniques for reducing computation time and shrinking model size. However, ensuring the accuracy of quantized models typically involves calibration using training data, which may be inaccessible due to privacy concerns. In such cases, zero-shot quantization, a technique that relies on pretrained models and statistical information without the need for specific training data, becomes valuable. Exploring zero-shot quantization in the infrared domain is important due to the prevalence of infrared imaging in sensitive fields like medical and security applications. In this work, we demonstrate how to apply zero-shot quantization to an object detection model retrained with thermal imagery. We use batch normalization statistics of the model to distill data for calibration. RGB image-trained models and thermal image-trained models are compared in the context of zero-shot quantization. Our investigation focuses on the contributions of mean and standard deviation statistics to zero-shot quantization performance. Additionally, we compare zero-shot quantization with post-training quantization on a thermal dataset. We demonstrated that zero-shot quantization successfully generates data that represents the training dataset for the quantization of object detection models. Our results indicate that our zero-shot quantization framework is effective in the absence of training data and is well-suited for the infrared domain.
Deep Learning-based Epicenter Localization using Single-Station Strong Motion Records
May 28, 2024This paper explores the application of deep learning (DL) techniques to strong motion records for single-station epicenter localization. Often underutilized in seismology-related studies, strong motion records offer a potential wealth of information about seismic events. We investigate whether DL-based methods can effectively leverage this data for accurate epicenter localization. Our study introduces AFAD-1218, a collection comprising more than 36,000 strong motion records sourced from Turkey. To utilize the strong motion records represented in either the time or the frequency domain, we propose two neural network architectures: deep residual network and temporal convolutional networks. Through extensive experimentation, we demonstrate the efficacy of DL approaches in extracting meaningful insights from these records, showcasing their potential for enhancing seismic event analysis and localization accuracy. Notably, our findings highlight significant reductions in prediction error achieved through the exclusion of low signal-to-noise ratio records, both in nationwide experiments and regional transfer-learning scenarios. Overall, this research underscores the promise of DL techniques in harnessing strong motion records for improved seismic event characterization and localization.
Near-Infrared and Low-Rank Adaptation of Vision Transformers in Remote Sensing
May 28, 2024



Plant health can be monitored dynamically using multispectral sensors that measure Near-Infrared reflectance (NIR). Despite this potential, obtaining and annotating high-resolution NIR images poses a significant challenge for training deep neural networks. Typically, large networks pre-trained on the RGB domain are utilized to fine-tune infrared images. This practice introduces a domain shift issue because of the differing visual traits between RGB and NIR images.As an alternative to fine-tuning, a method called low-rank adaptation (LoRA) enables more efficient training by optimizing rank-decomposition matrices while keeping the original network weights frozen. However, existing parameter-efficient adaptation strategies for remote sensing images focus on RGB images and overlook domain shift issues in the NIR domain. Therefore, this study investigates the potential benefits of using vision transformer (ViT) backbones pre-trained in the RGB domain, with low-rank adaptation for downstream tasks in the NIR domain. Extensive experiments demonstrate that employing LoRA with pre-trained ViT backbones yields the best performance for downstream tasks applied to NIR images.
Enhancing Visual Question Answering through Question-Driven Image Captions as Prompts
Apr 12, 2024Visual question answering (VQA) is known as an AI-complete task as it requires understanding, reasoning, and inferring about the vision and the language content. Over the past few years, numerous neural architectures have been suggested for the VQA problem. However, achieving success in zero-shot VQA remains a challenge due to its requirement for advanced generalization and reasoning skills. This study explores the impact of incorporating image captioning as an intermediary process within the VQA pipeline. Specifically, we explore the efficacy of utilizing image captions instead of images and leveraging large language models (LLMs) to establish a zero-shot setting. Since image captioning is the most crucial step in this process, we compare the impact of state-of-the-art image captioning models on VQA performance across various question types in terms of structure and semantics. We propose a straightforward and efficient question-driven image captioning approach within this pipeline to transfer contextual information into the question-answering (QA) model. This method involves extracting keywords from the question, generating a caption for each image-question pair using the keywords, and incorporating the question-driven caption into the LLM prompt. We evaluate the efficacy of using general-purpose and question-driven image captions in the VQA pipeline. Our study highlights the potential of employing image captions and harnessing the capabilities of LLMs to achieve competitive performance on GQA under the zero-shot setting. Our code is available at \url{https://github.com/ovguyo/captions-in-VQA}.
Exploring Challenges in Deep Learning of Single-Station Ground Motion Records
Mar 12, 2024



Contemporary deep learning models have demonstrated promising results across various applications within seismology and earthquake engineering. These models rely primarily on utilizing ground motion records for tasks such as earthquake event classification, localization, earthquake early warning systems, and structural health monitoring. However, the extent to which these models effectively learn from these complex time-series signals has not been thoroughly analyzed. In this study, our objective is to evaluate the degree to which auxiliary information, such as seismic phase arrival times or seismic station distribution within a network, dominates the process of deep learning from ground motion records, potentially hindering its effectiveness. We perform a hyperparameter search on two deep learning models to assess their effectiveness in deep learning from ground motion records while also examining the impact of auxiliary information on model performance. Experimental results reveal a strong reliance on the highly correlated P and S phase arrival information. Our observations highlight a potential gap in the field, indicating an absence of robust methodologies for deep learning of single-station ground motion recordings independent of any auxiliary information.
Local Masking Meets Progressive Freezing: Crafting Efficient Vision Transformers for Self-Supervised Learning
Dec 02, 2023In this paper, we present an innovative approach to self-supervised learning for Vision Transformers (ViTs), integrating local masked image modeling with progressive layer freezing. This method focuses on enhancing the efficiency and speed of initial layer training in ViTs. By systematically freezing specific layers at strategic points during training, we reduce computational demands while maintaining or improving learning capabilities. Our approach employs a novel multi-scale reconstruction process that fosters efficient learning in initial layers and enhances semantic comprehension across scales. The results demonstrate a substantial reduction in training time (~12.5\%) with a minimal impact on model accuracy (decrease in top-1 accuracy by 0.6\%). Our method achieves top-1 and top-5 accuracies of 82.6\% and 96.2\%, respectively, underscoring its potential in scenarios where computational resources and time are critical. This work marks an advancement in the field of self-supervised learning for computer vision. The implementation of our approach is available at our project's GitHub repository: github.com/utkutpcgl/ViTFreeze.
EANet: Enhanced Attribute-based RGBT Tracker Network
Jul 04, 2023Tracking objects can be a difficult task in computer vision, especially when faced with challenges such as occlusion, changes in lighting, and motion blur. Recent advances in deep learning have shown promise in challenging these conditions. However, most deep learning-based object trackers only use visible band (RGB) images. Thermal infrared electromagnetic waves (TIR) can provide additional information about an object, including its temperature, when faced with challenging conditions. We propose a deep learning-based image tracking approach that fuses RGB and thermal images (RGBT). The proposed model consists of two main components: a feature extractor and a tracker. The feature extractor encodes deep features from both the RGB and the TIR images. The tracker then uses these features to track the object using an enhanced attribute-based architecture. We propose a fusion of attribute-specific feature selection with an aggregation module. The proposed methods are evaluated on the RGBT234 \cite{LiCLiang2018} and LasHeR \cite{LiLasher2021} datasets, which are the most widely used RGBT object-tracking datasets in the literature. The results show that the proposed system outperforms state-of-the-art RGBT object trackers on these datasets, with a relatively smaller number of parameters.
Detecting Driver Drowsiness as an Anomaly Using LSTM Autoencoders
Sep 12, 2022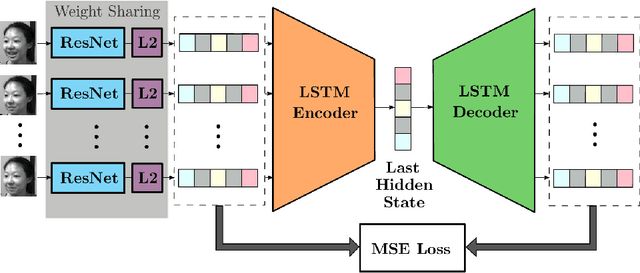
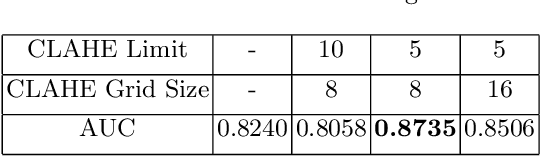
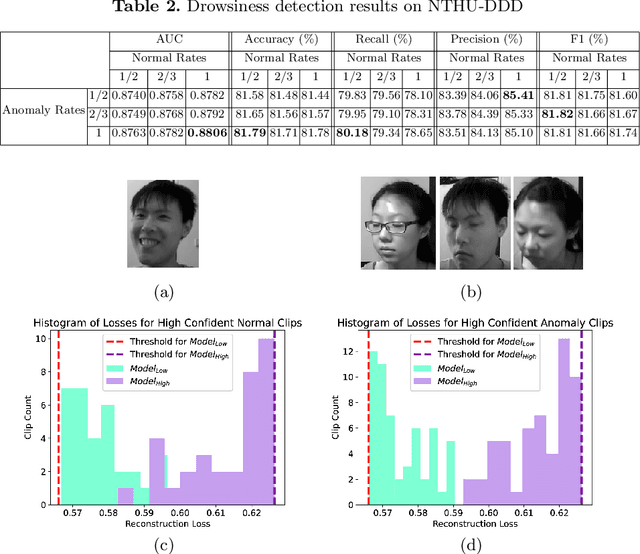

In this paper, an LSTM autoencoder-based architecture is utilized for drowsiness detection with ResNet-34 as feature extractor. The problem is considered as anomaly detection for a single subject; therefore, only the normal driving representations are learned and it is expected that drowsiness representations, yielding higher reconstruction losses, are to be distinguished according to the knowledge of the network. In our study, the confidence levels of normal and anomaly clips are investigated through the methodology of label assignment such that training performance of LSTM autoencoder and interpretation of anomalies encountered during testing are analyzed under varying confidence rates. Our method is experimented on NTHU-DDD and benchmarked with a state-of-the-art anomaly detection method for driver drowsiness. Results show that the proposed model achieves detection rate of 0.8740 area under curve (AUC) and is able to provide significant improvements on certain scenarios.