 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElimination of Non-Novel Segments at Multi-Scale for Few-Shot Segmentation
Nov 04, 2022



Few-shot segmentation aims to devise a generalizing model that segments query images from unseen classes during training with the guidance of a few support images whose class tally with the class of the query. There exist two domain-specific problems mentioned in the previous works, namely spatial inconsistency and bias towards seen classes. Taking the former problem into account, our method compares the support feature map with the query feature map at multi scales to become scale-agnostic. As a solution to the latter problem, a supervised model, called as base learner, is trained on available classes to accurately identify pixels belonging to seen classes. Hence, subsequent meta learner has a chance to discard areas belonging to seen classes with the help of an ensemble learning model that coordinates meta learner with the base learner. We simultaneously address these two vital problems for the first time and achieve state-of-the-art performances on both PASCAL-5i and COCO-20i datasets.
Detecting Driver Drowsiness as an Anomaly Using LSTM Autoencoders
Sep 12, 2022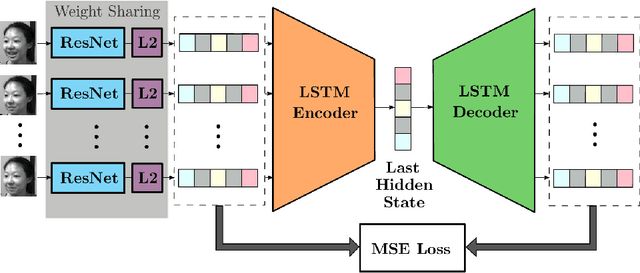
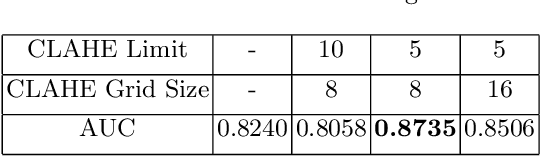
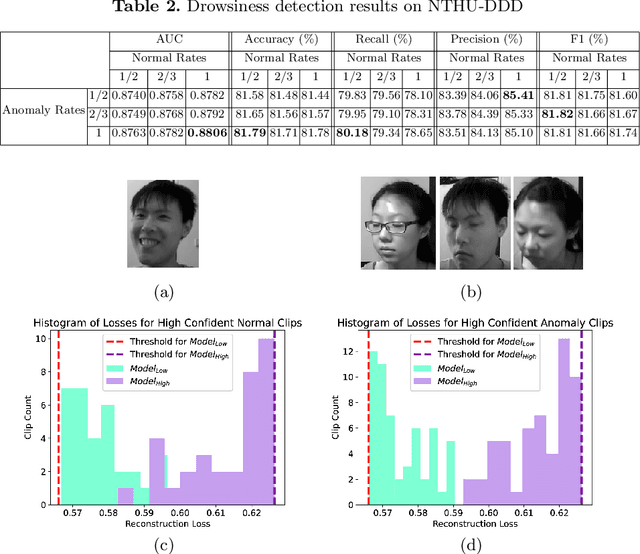

In this paper, an LSTM autoencoder-based architecture is utilized for drowsiness detection with ResNet-34 as feature extractor. The problem is considered as anomaly detection for a single subject; therefore, only the normal driving representations are learned and it is expected that drowsiness representations, yielding higher reconstruction losses, are to be distinguished according to the knowledge of the network. In our study, the confidence levels of normal and anomaly clips are investigated through the methodology of label assignment such that training performance of LSTM autoencoder and interpretation of anomalies encountered during testing are analyzed under varying confidence rates. Our method is experimented on NTHU-DDD and benchmarked with a state-of-the-art anomaly detection method for driver drowsiness. Results show that the proposed model achieves detection rate of 0.8740 area under curve (AUC) and is able to provide significant improvements on certain scenarios.
Label Noise Types and Their Effects on Deep Learning
Mar 23, 2020
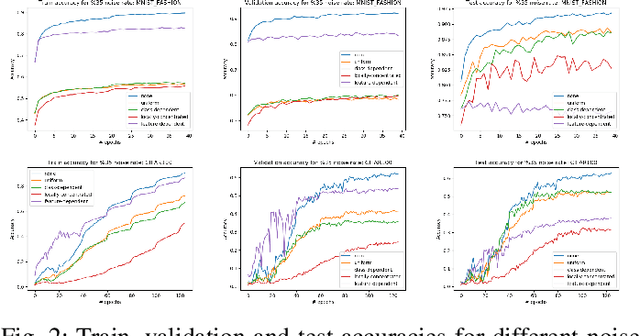
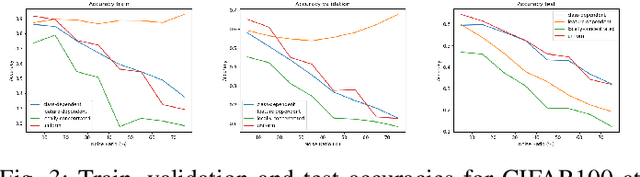
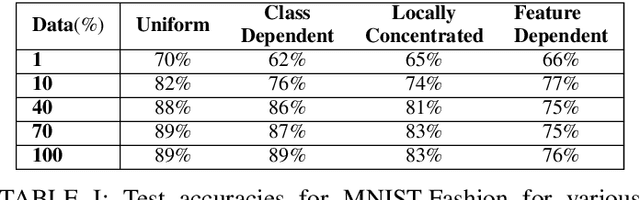
The recent success of deep learning is mostly due to the availability of big datasets with clean annotations. However, gathering a cleanly annotated dataset is not always feasible due to practical challenges. As a result, label noise is a common problem in datasets, and numerous methods to train deep neural networks in the presence of noisy labels are proposed in the literature. These methods commonly use benchmark datasets with synthetic label noise on the training set. However, there are multiple types of label noise, and each of them has its own characteristic impact on learning. Since each work generates a different kind of label noise, it is problematic to test and compare those algorithms in the literature fairly. In this work, we provide a detailed analysis of the effects of different kinds of label noise on learning. Moreover, we propose a generic framework to generate feature-dependent label noise, which we show to be the most challenging case for learning. Our proposed method aims to emphasize similarities among data instances by sparsely distributing them in the feature domain. By this approach, samples that are more likely to be mislabeled are detected from their softmax probabilities, and their labels are flipped to the corresponding class. The proposed method can be applied to any clean dataset to synthesize feature-dependent noisy labels. For the ease of other researchers to test their algorithms with noisy labels, we share corrupted labels for the most commonly used benchmark datasets. Our code and generated noisy synthetic labels are available online.