 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Anomaly Detection in In-Vehicle Networks
Sep 11, 2024

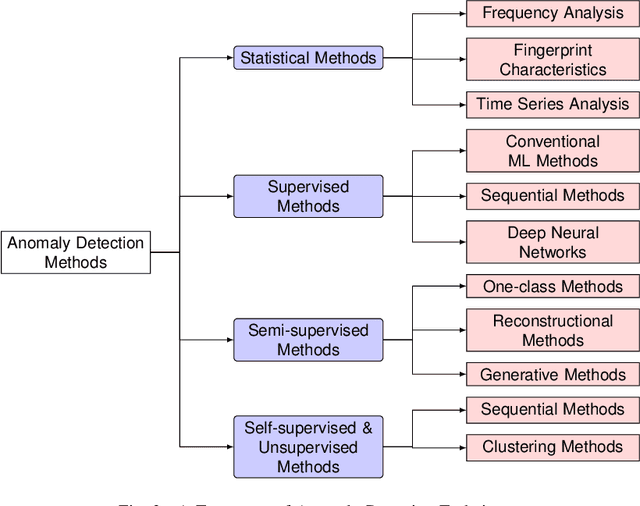

Modern vehicles are equipped with Electronic Control Units (ECU) that are used for controlling important vehicle functions including safety-critical operations. ECUs exchange information via in-vehicle communication buses, of which the Controller Area Network (CAN bus) is by far the most widespread representative. Problems that may occur in the vehicle's physical parts or malicious attacks may cause anomalies in the CAN traffic, impairing the correct vehicle operation. Therefore, the detection of such anomalies is vital for vehicle safety. This paper reviews the research on anomaly detection for in-vehicle networks, more specifically for the CAN bus. Our main focus is the evaluation of methods used for CAN bus anomaly detection together with the datasets used in such analysis. To provide the reader with a more comprehensive understanding of the subject, we first give a brief review of related studies on time series-based anomaly detection. Then, we conduct an extensive survey of recent deep learning-based techniques as well as conventional techniques for CAN bus anomaly detection. Our comprehensive analysis delves into anomaly detection algorithms employed in in-vehicle networks, specifically focusing on their learning paradigms, inherent strengths, and weaknesses, as well as their efficacy when applied to CAN bus datasets. Lastly, we highlight challenges and open research problems in CAN bus anomaly detection.
Enhancing Visual Question Answering through Question-Driven Image Captions as Prompts
Apr 12, 2024Visual question answering (VQA) is known as an AI-complete task as it requires understanding, reasoning, and inferring about the vision and the language content. Over the past few years, numerous neural architectures have been suggested for the VQA problem. However, achieving success in zero-shot VQA remains a challenge due to its requirement for advanced generalization and reasoning skills. This study explores the impact of incorporating image captioning as an intermediary process within the VQA pipeline. Specifically, we explore the efficacy of utilizing image captions instead of images and leveraging large language models (LLMs) to establish a zero-shot setting. Since image captioning is the most crucial step in this process, we compare the impact of state-of-the-art image captioning models on VQA performance across various question types in terms of structure and semantics. We propose a straightforward and efficient question-driven image captioning approach within this pipeline to transfer contextual information into the question-answering (QA) model. This method involves extracting keywords from the question, generating a caption for each image-question pair using the keywords, and incorporating the question-driven caption into the LLM prompt. We evaluate the efficacy of using general-purpose and question-driven image captions in the VQA pipeline. Our study highlights the potential of employing image captions and harnessing the capabilities of LLMs to achieve competitive performance on GQA under the zero-shot setting. Our code is available at \url{https://github.com/ovguyo/captions-in-VQA}.