 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Alignment of Data-Quality Metrics, Human Judgment and Land-Cover Segmentation Performance for Earth Observation
Jun 23, 2026Volume and quality of datasets are crucial for deep learning model training, yet they are often constrained by availability and data acquisition costs. Synthetic data augmentation can extend existing datasets with realistic images, and the quality of these images is generally assessed through fidelity metrics such as FID, KID, IS, LPIPS and SSIM that measure structural or distributional similarity. However, such metrics, including the widely used FID, focus on visual fidelity without reflecting downstream utility, and can diverge from human perception under perturbations that are imperceptible to human observers. In this work, we systematically evaluate Earth observation datasets alongside synthetic counterparts generated by deep generative models, comparing automatic metrics against human perception and downstream tasks. Our results reveal a stark misalignment: semantics-preserving perturbations such as rotation drastically alter metric scores while leaving human recognition unaffected, and synthetic samples that score poorly on automatic metrics achieve comparable or higher perceived realism, and can improve downstream performance when combined with real data. By benchmarking semantic segmentation models trained on mixed real-synthetic datasets, we demonstrate that quality metrics rooted in ImageNet-pretrained feature spaces are unreliable indicators for geospatial data. Our findings underscore that automatic quality evaluation of synthetic datasets should be grounded in downstream task performance and human evaluation.
BELDE: Building a Large-scale Earth-observation Land-cover Dataset for Europe
Jun 18, 2026Earth observation imagery plays a critical role in environmental monitoring, urban planning, disaster assessment, and climate analysis. While multi-spectral sensors are increasingly available, true-color (RGB) imagery remains widely used due to the power, cost, and deployment constraints of many satellite and aerial platforms. However, existing land-cover segmentation datasets are often limited in geographic coverage, scale, or public accessibility. To bridge this gap, we introduce BELDE (Building a Large-scale Earth-observation Land-cover Dataset for Europe), a publicly available dataset tailored for RGB-based remote sensing semantic segmentation. Constructed from Sentinel-2 true-color images and ESA WorldCover data annotations, BELDE contains 1,088,385 curated image-segmentation map pairs spanning Europe with 7 land-cover classes at 10 m spatial resolution, making it one of the largest publicly available RGB land-cover segmentation datasets for Earth observation. To facilitate cross-region generalization studies, we additionally introduce BELDE-K (16,607 pairs) covering the Republic of Korea and BELDE-CA-NV (88,155 pairs) covering California and Nevada in the United States. We establish baseline results using multiple semantic segmentation architectures and evaluate both in-domain and cross-domain performance. Models trained on BELDE achieve an F1 score of 83.0% on the European test set, while performance decreases to 66.4% on BELDE-CA-NV and 58.3% on BELDE-K, highlighting the challenges posed by out-of-distribution geographic domain shift. By providing a continental-scale RGB segmentation and evaluation benchmark, BELDE supports the development of robust and transferable Earth observation models. The dataset and benchmark resources will be publicly released.
LALE: Lightweight-Transformer Architecture for Land-Cover Estimation
Jun 01, 2026Semantic segmentation of remote sensing imagery requires models that capture both global context and local detail under tight computational budgets. Prior work typically optimizes for one of these axes: attention for global context, convolution for local detail, or compactness for efficiency. While hybrid approaches aim to capture both, they require architectural changes and encoder backbones with computational overhead, limiting efficiency and performance. We present LALE (Lightweight-transformer Architecture for Land-cover Estimation), an end-to-end remote sensing image segmentation architecture, that bifurcates its encoder by resolution: lightweight ConvMixer stages handle high-resolution local features, while transformer stages handle low-resolution global context, confining the quadratic cost of self-attention to deep, downsampled feature maps. An all-MLP multi-scale decoder, together with RMSNorm and StarReLU throughout, further reduces compute and parameter count. On the large-scale ARAS400k remote-sensing segmentation benchmark, LALE establishes a strong efficiency-performance trade-off against CNN, transformer, and hybrid baselines. Our smallest variant, (just 1.6M parameters), reaches within 2.6 F1 points of the best baseline (UPerNet) while using 4.5x fewer parameters, 7x less storage, 17x fewer GMACs, and delivering 1.8x higher throughput.
Grounding Synthetic Data Generation With Vision and Language Models
Mar 10, 2026Deep learning models benefit from increasing data diversity and volume, motivating synthetic data augmentation to improve existing datasets. However, existing evaluation metrics for synthetic data typically calculate latent feature similarity, which is difficult to interpret and does not always correlate with the contribution to downstream tasks. We propose a vision-language grounded framework for interpretable synthetic data augmentation and evaluation in remote sensing. Our approach combines generative models, semantic segmentation and image captioning with vision and language models. Based on this framework, we introduce ARAS400k: A large-scale Remote sensing dataset Augmented with Synthetic data for segmentation and captioning, containing 100k real images and 300k synthetic images, each paired with segmentation maps and descriptions. ARAS400k enables the automated evaluation of synthetic data by analyzing semantic composition, minimizing caption redundancy, and verifying cross-modal consistency between visual structures and language descriptions. Experimental results indicate that while models trained exclusively on synthetic data reach competitive performance levels, those trained with augmented data (a combination of real and synthetic images) consistently outperform real-data baselines. Consequently, this work establishes a scalable benchmark for remote sensing tasks, specifically in semantic segmentation and image captioning. The dataset is available at zenodo.org/records/18890661 and the code base at github.com/caglarmert/ARAS400k.
Exploring Challenges in Deep Learning of Single-Station Ground Motion Records
Mar 12, 2024



Contemporary deep learning models have demonstrated promising results across various applications within seismology and earthquake engineering. These models rely primarily on utilizing ground motion records for tasks such as earthquake event classification, localization, earthquake early warning systems, and structural health monitoring. However, the extent to which these models effectively learn from these complex time-series signals has not been thoroughly analyzed. In this study, our objective is to evaluate the degree to which auxiliary information, such as seismic phase arrival times or seismic station distribution within a network, dominates the process of deep learning from ground motion records, potentially hindering its effectiveness. We perform a hyperparameter search on two deep learning models to assess their effectiveness in deep learning from ground motion records while also examining the impact of auxiliary information on model performance. Experimental results reveal a strong reliance on the highly correlated P and S phase arrival information. Our observations highlight a potential gap in the field, indicating an absence of robust methodologies for deep learning of single-station ground motion recordings independent of any auxiliary information.
Ulcerative Colitis Mayo Endoscopic Scoring Classification with Active Learning and Generative Data Augmentation
Nov 10, 2023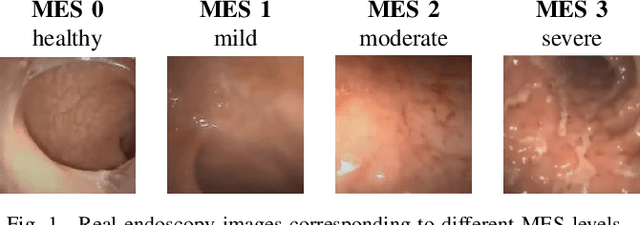
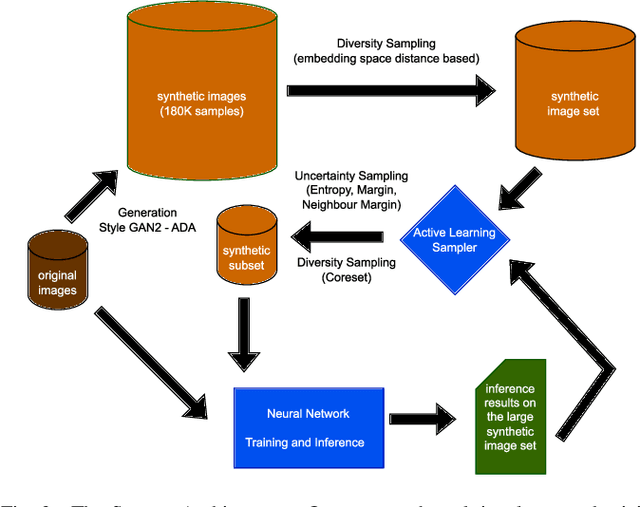
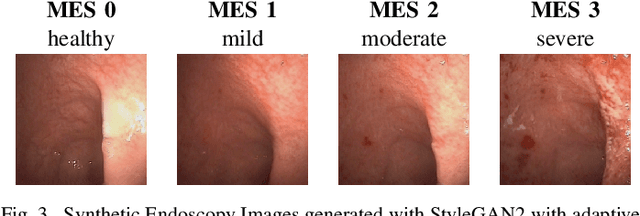
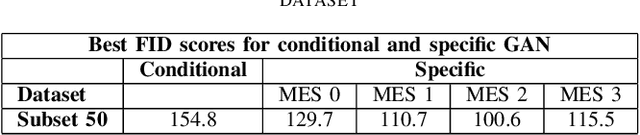
Endoscopic imaging is commonly used to diagnose Ulcerative Colitis (UC) and classify its severity. It has been shown that deep learning based methods are effective in automated analysis of these images and can potentially be used to aid medical doctors. Unleashing the full potential of these methods depends on the availability of large amount of labeled images; however, obtaining and labeling these images are quite challenging. In this paper, we propose a active learning based generative augmentation method. The method involves generating a large number of synthetic samples by training using a small dataset consisting of real endoscopic images. The resulting data pool is narrowed down by using active learning methods to select the most informative samples, which are then used to train a classifier. We demonstrate the effectiveness of our method through experiments on a publicly available endoscopic image dataset. The results show that using synthesized samples in conjunction with active learning leads to improved classification performance compared to using only the original labeled examples and the baseline classification performance of 68.1% increases to 74.5% in terms of Quadratic Weighted Kappa (QWK) Score. Another observation is that, attaining equivalent performance using only real data necessitated three times higher number of images.