 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSome theoretical improvements on the tightness of PAC-Bayes risk certificates for neural networks
Oct 09, 2025This paper presents four theoretical contributions that improve the usability of risk certificates for neural networks based on PAC-Bayes bounds. First, two bounds on the KL divergence between Bernoulli distributions enable the derivation of the tightest explicit bounds on the true risk of classifiers across different ranges of empirical risk. The paper next focuses on the formalization of an efficient methodology based on implicit differentiation that enables the introduction of the optimization of PAC-Bayesian risk certificates inside the loss/objective function used to fit the network/model. The last contribution is a method to optimize bounds on non-differentiable objectives such as the 0-1 loss. These theoretical contributions are complemented with an empirical evaluation on the MNIST and CIFAR-10 datasets. In fact, this paper presents the first non-vacuous generalization bounds on CIFAR-10 for neural networks.
The Relevance Feature and Vector Machine for health applications
Feb 11, 2024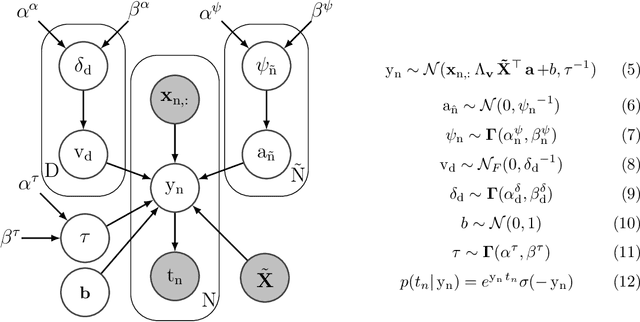
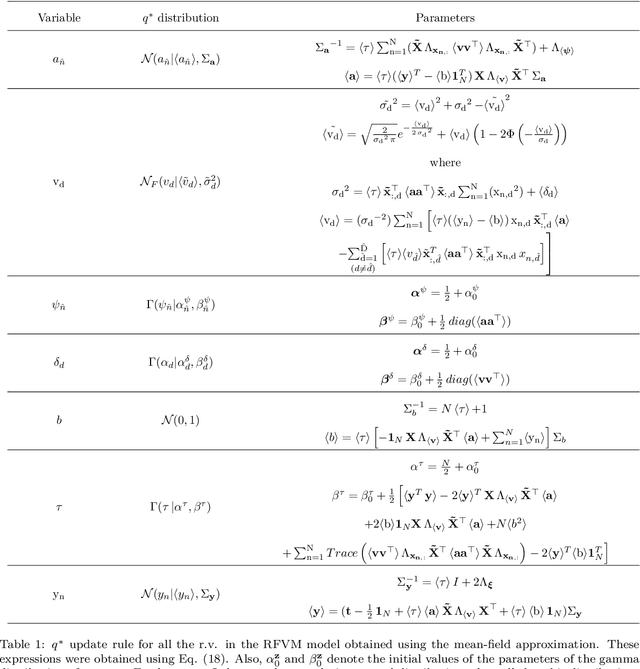
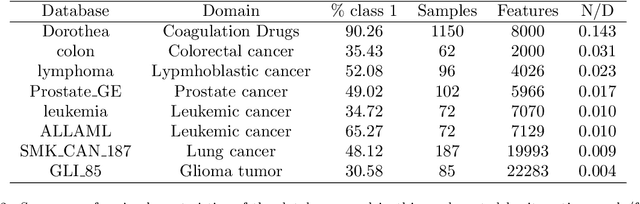
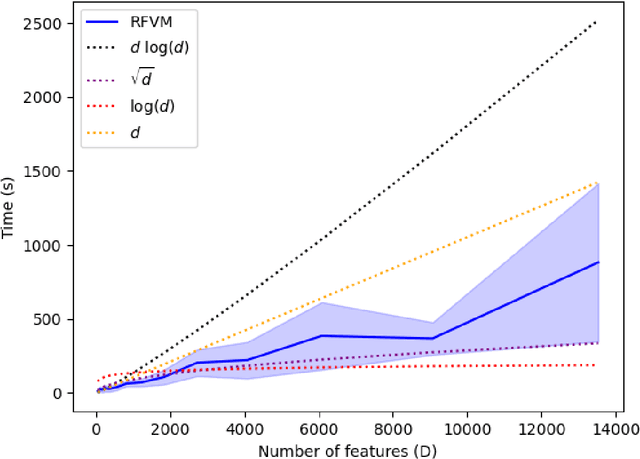
This paper presents the Relevance Feature and Vector Machine (RFVM), a novel model that addresses the challenges of the fat-data problem when dealing with clinical prospective studies. The fat-data problem refers to the limitations of Machine Learning (ML) algorithms when working with databases in which the number of features is much larger than the number of samples (a common scenario in certain medical fields). To overcome such limitations, the RFVM incorporates different characteristics: (1) A Bayesian formulation which enables the model to infer its parameters without overfitting thanks to the Bayesian model averaging. (2) A joint optimisation that overcomes the limitations arising from the fat-data characteristic by simultaneously including the variables that define the primal space (features) and those that define the dual space (observations). (3) An integrated prunning that removes the irrelevant features and samples during the training iterative optimization. Also, this last point turns out crucial when performing medical prospective studies, enabling researchers to exclude unnecessary medical tests, reducing costs and inconvenience for patients, and identifying the critical patients/subjects that characterize the disorder and, subsequently, optimize the patient recruitment process that leads to a balanced cohort. The model capabilities are tested against state-of-the-art models in several medical datasets with fat-data problems. These experimental works show that RFVM is capable of achieving competitive classification accuracies while providing the most compact subset of data (in both terms of features and samples). Moreover, the selected features (medical tests) seem to be aligned with the existing medical literature.
Bayesian learning of feature spaces for multitasks problems
Sep 07, 2022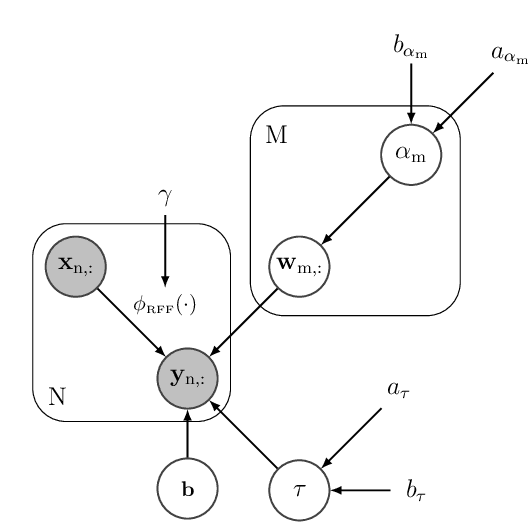


This paper presents a Bayesian framework to construct non-linear, parsimonious, shallow models for multitask regression. The proposed framework relies on the fact that Random Fourier Features (RFFs) enables the approximation of an RBF kernel by an extreme learning machine whose hidden layer is formed by RFFs. The main idea is to combine both dual views of a same model under a single Bayesian formulation that extends the Sparse Bayesian Extreme Learning Machines to multitask problems. From the kernel methods point of view, the proposed formulation facilitates the introduction of prior domain knowledge through the RBF kernel parameter. From the extreme learning machines perspective, the new formulation helps control overfitting and enables a parsimonious overall model (the models that serve each task share a same set of RFFs selected within the joint Bayesian optimisation). The experimental results show that combining advantages from kernel methods and extreme learning machines within the same framework can lead to significant improvements in the performance achieved by each of these two paradigms independently.
State-Space Dynamics Distance for Clustering Sequential Data
Apr 09, 2010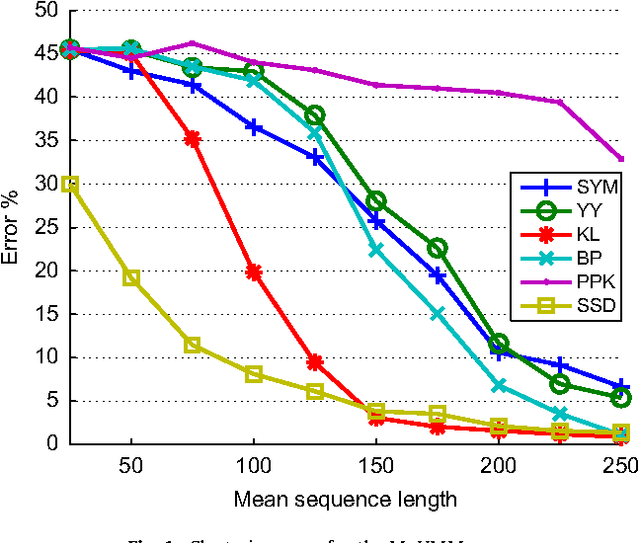
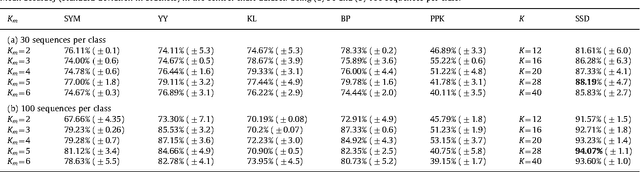
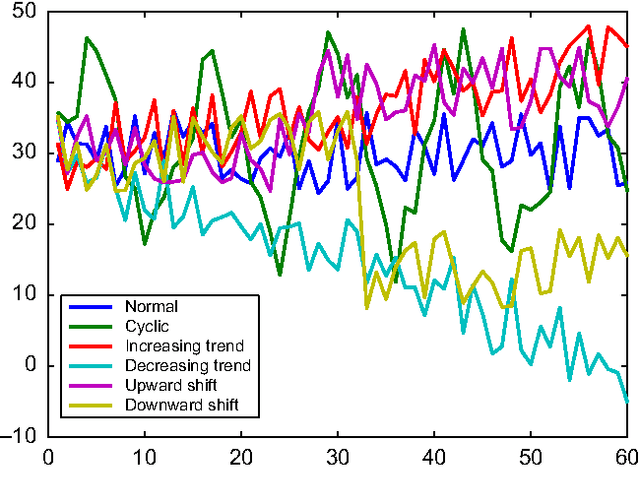
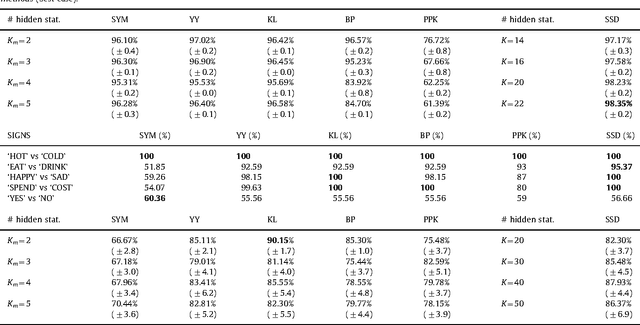
This paper proposes a novel similarity measure for clustering sequential data. We first construct a common state-space by training a single probabilistic model with all the sequences in order to get a unified representation for the dataset. Then, distances are obtained attending to the transition matrices induced by each sequence in that state-space. This approach solves some of the usual overfitting and scalability issues of the existing semi-parametric techniques, that rely on training a model for each sequence. Empirical studies on both synthetic and real-world datasets illustrate the advantages of the proposed similarity measure for clustering sequences.