 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic Net Regularization and Gabor Dictionary for Classification of Heart Sound Signals using Deep Learning
Apr 14, 2026In this article, we propose the optimization of the resolution of time-frequency atoms and the regularization of fitting models to obtain better representations of heart sound signals. This is done by evaluating the classification performance of deep learning (DL) networks in discriminating five heart valvular conditions based on a new class of time-frequency feature matrices derived from the fitting models. We inspect several combinations of resolution and regularization, and the optimal one is that provides the highest performance. To this end, a fitting model is obtained based on a heart sound signal and an overcomplete dictionary of Gabor atoms using elastic net regularization of linear models. We consider two different DL architectures, the first mainly consisting of a 1D convolutional neural network (CNN) layer and a long short-term memory (LSTM) layer, while the second is composed of 1D and 2D CNN layers followed by an LSTM layer. The networks are trained with two algorithms, namely stochastic gradient descent with momentum (SGDM) and adaptive moment (ADAM). Extensive experimentation has been conducted using a database containing heart sound signals of five heart valvular conditions. The best classification accuracy of $98.95\%$ is achieved with the second architecture when trained with ADAM and feature matrices derived from optimal models obtained with a Gabor dictionary consisting of atoms with high-time low-frequency resolution and imposing sparsity on the models.
Automatic Detection of Depression in Speech Using Ensemble Convolutional Neural Networks
Feb 05, 2024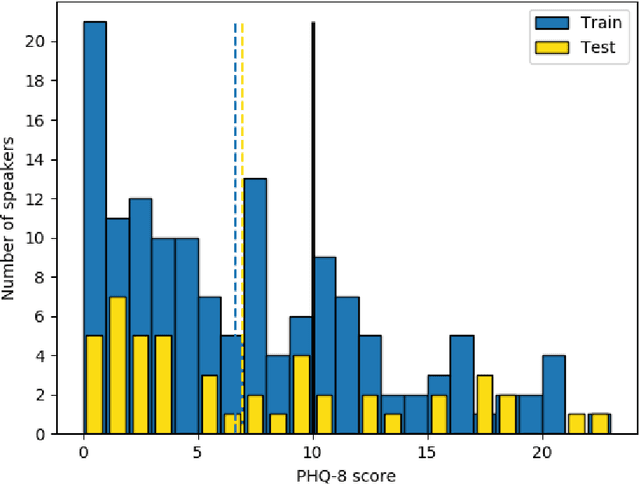
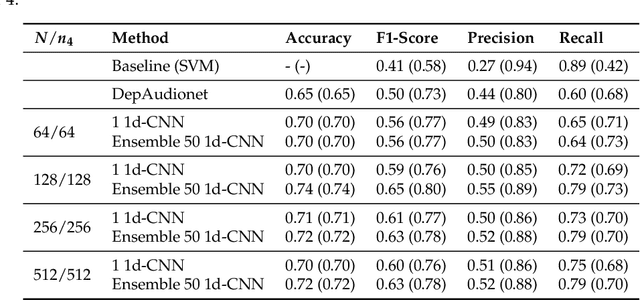
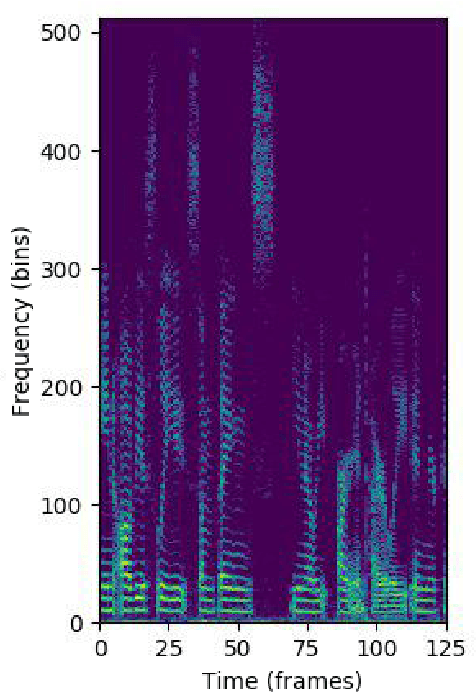
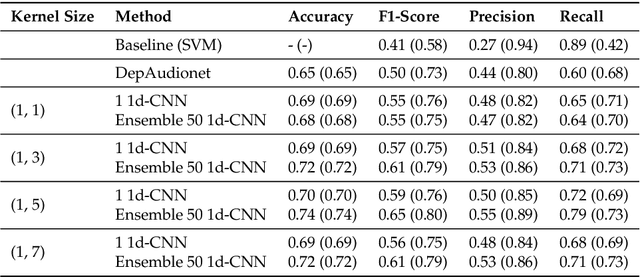
This paper proposes a speech-based method for automatic depression classification. The system is based on ensemble learning for Convolutional Neural Networks (CNNs) and is evaluated using the data and the experimental protocol provided in the Depression Classification Sub-Challenge (DCC) at the 2016 Audio-Visual Emotion Challenge (AVEC-2016). In the pre-processing phase, speech files are represented as a sequence of log-spectrograms and randomly sampled to balance positive and negative samples. For the classification task itself, first, a more suitable architecture for this task, based on One-Dimensional Convolutional Neural Networks, is built. Secondly, several of these CNN-based models are trained with different initializations and then the corresponding individual predictions are fused by using an Ensemble Averaging algorithm and combined per speaker to get an appropriate final decision. The proposed ensemble system achieves satisfactory results on the DCC at the AVEC-2016 in comparison with a reference system based on Support Vector Machines and hand-crafted features, with a CNN+LSTM-based system called DepAudionet, and with the case of a single CNN-based classifier.
An Attention Long Short-Term Memory based system for automatic classification of speech intelligibility
Feb 05, 2024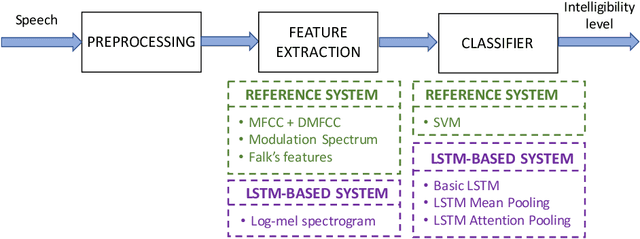

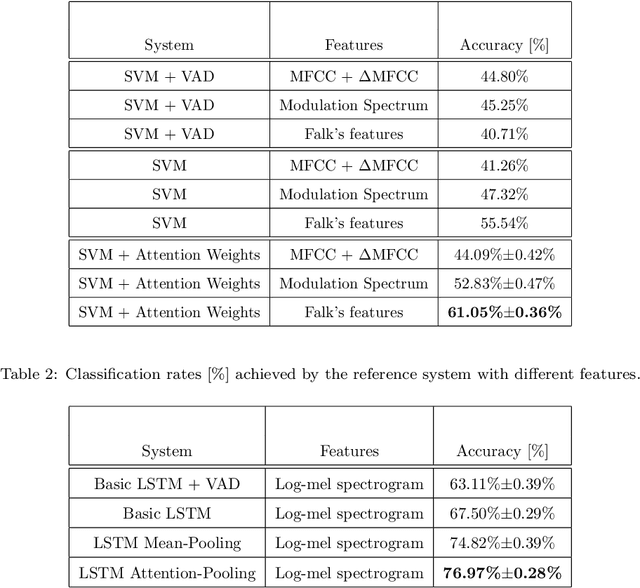
Speech intelligibility can be degraded due to multiple factors, such as noisy environments, technical difficulties or biological conditions. This work is focused on the development of an automatic non-intrusive system for predicting the speech intelligibility level in this latter case. The main contribution of our research on this topic is the use of Long Short-Term Memory (LSTM) networks with log-mel spectrograms as input features for this purpose. In addition, this LSTM-based system is further enhanced by the incorporation of a simple attention mechanism that is able to determine the more relevant frames to this task. The proposed models are evaluated with the UA-Speech database that contains dysarthric speech with different degrees of severity. Results show that the attention LSTM architecture outperforms both, a reference Support Vector Machine (SVM)-based system with hand-crafted features and a LSTM-based system with Mean-Pooling.
On combining acoustic and modulation spectrograms in an attention LSTM-based system for speech intelligibility level classification
Feb 05, 2024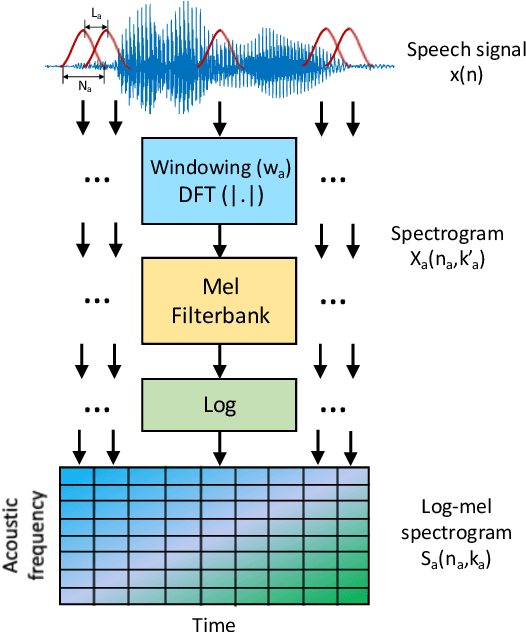
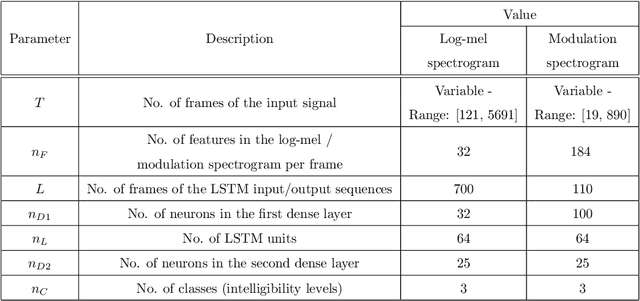
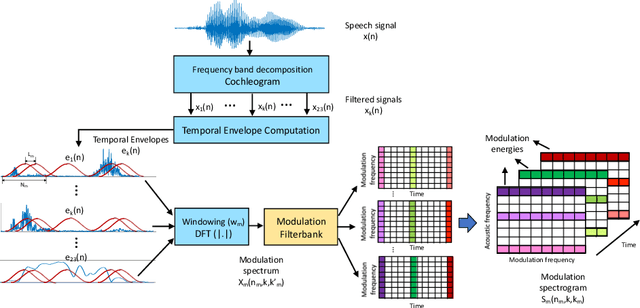
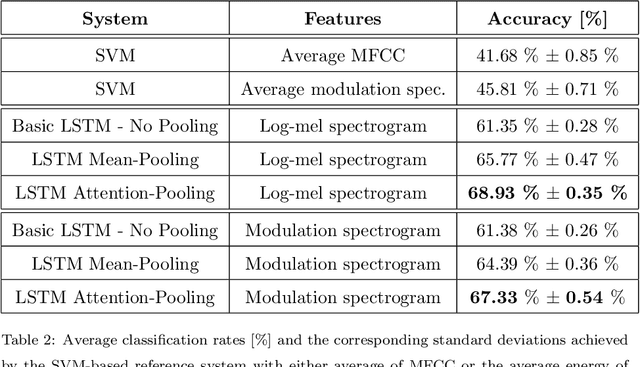
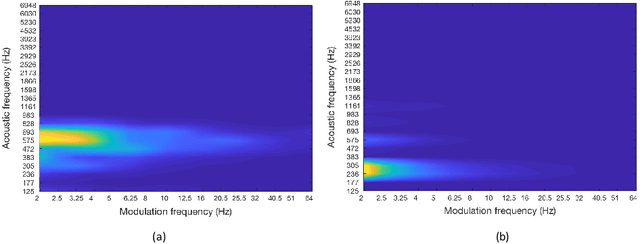
Speech intelligibility can be affected by multiple factors, such as noisy environments, channel distortions or physiological issues. In this work, we deal with the problem of automatic prediction of the speech intelligibility level in this latter case. Starting from our previous work, a non-intrusive system based on LSTM networks with attention mechanism designed for this task, we present two main contributions. In the first one, it is proposed the use of per-frame modulation spectrograms as input features, instead of compact representations derived from them that discard important temporal information. In the second one, two different strategies for the combination of per-frame acoustic log-mel and modulation spectrograms into the LSTM framework are explored: at decision level or late fusion and at utterance level or Weighted-Pooling (WP) fusion. The proposed models are evaluated with the UA-Speech database that contains dysarthric speech with different degrees of severity. On the one hand, results show that attentional LSTM networks are able to adequately modeling the modulation spectrograms sequences producing similar classification rates as in the case of log-mel spectrograms. On the other hand, both combination strategies, late and WP fusion, outperform the single-feature systems, suggesting that per-frame log-mel and modulation spectrograms carry complementary information for the task of speech intelligibility prediction, than can be effectively exploited by the LSTM-based architectures, being the system with the WP fusion strategy and Attention-Pooling the one that achieves best results.
Bayesian learning of feature spaces for multitasks problems
Sep 07, 2022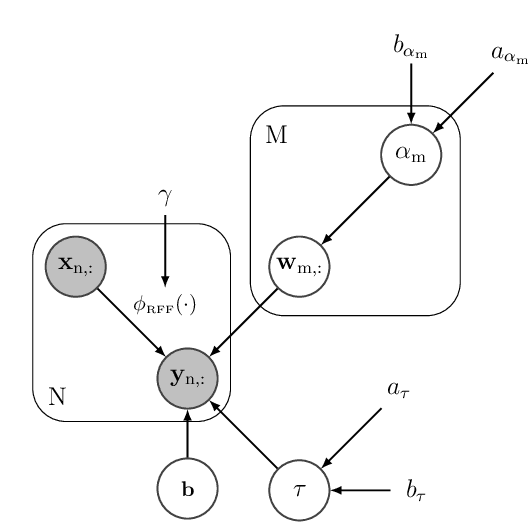


This paper presents a Bayesian framework to construct non-linear, parsimonious, shallow models for multitask regression. The proposed framework relies on the fact that Random Fourier Features (RFFs) enables the approximation of an RBF kernel by an extreme learning machine whose hidden layer is formed by RFFs. The main idea is to combine both dual views of a same model under a single Bayesian formulation that extends the Sparse Bayesian Extreme Learning Machines to multitask problems. From the kernel methods point of view, the proposed formulation facilitates the introduction of prior domain knowledge through the RBF kernel parameter. From the extreme learning machines perspective, the new formulation helps control overfitting and enables a parsimonious overall model (the models that serve each task share a same set of RFFs selected within the joint Bayesian optimisation). The experimental results show that combining advantages from kernel methods and extreme learning machines within the same framework can lead to significant improvements in the performance achieved by each of these two paradigms independently.