 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn combining acoustic and modulation spectrograms in an attention LSTM-based system for speech intelligibility level classification
Feb 05, 2024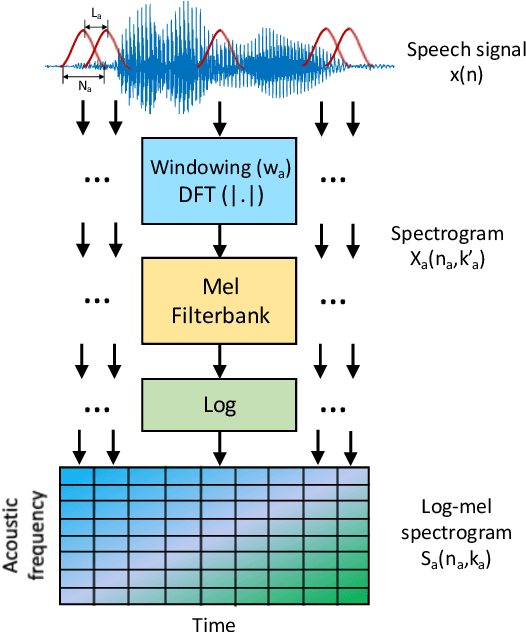
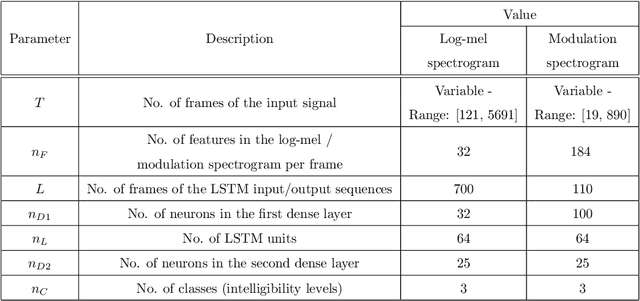
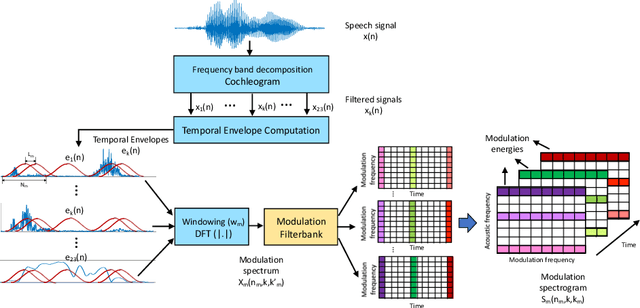
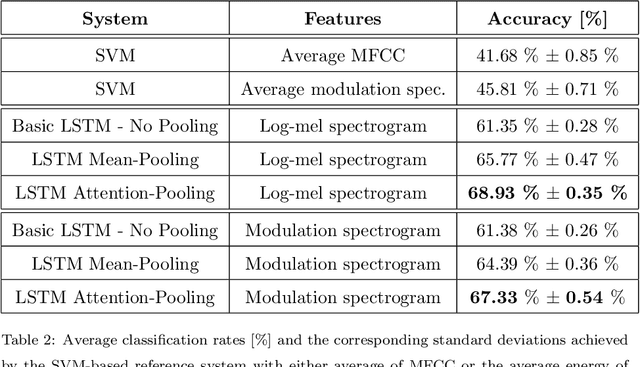
Speech intelligibility can be affected by multiple factors, such as noisy environments, channel distortions or physiological issues. In this work, we deal with the problem of automatic prediction of the speech intelligibility level in this latter case. Starting from our previous work, a non-intrusive system based on LSTM networks with attention mechanism designed for this task, we present two main contributions. In the first one, it is proposed the use of per-frame modulation spectrograms as input features, instead of compact representations derived from them that discard important temporal information. In the second one, two different strategies for the combination of per-frame acoustic log-mel and modulation spectrograms into the LSTM framework are explored: at decision level or late fusion and at utterance level or Weighted-Pooling (WP) fusion. The proposed models are evaluated with the UA-Speech database that contains dysarthric speech with different degrees of severity. On the one hand, results show that attentional LSTM networks are able to adequately modeling the modulation spectrograms sequences producing similar classification rates as in the case of log-mel spectrograms. On the other hand, both combination strategies, late and WP fusion, outperform the single-feature systems, suggesting that per-frame log-mel and modulation spectrograms carry complementary information for the task of speech intelligibility prediction, than can be effectively exploited by the LSTM-based architectures, being the system with the WP fusion strategy and Attention-Pooling the one that achieves best results.