 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Integration of Nonlinear Incomplete Clinical Data
Feb 02, 2026Multimodal clinical data are characterized by high dimensionality, heterogeneous representations, and structured missingness, posing significant challenges for predictive modeling, data integration, and interpretability. We propose BIONIC (Bayesian Integration of Nonlinear Incomplete Clinical data), a unified probabilistic framework that integrates heterogeneous multimodal data under missingness through a joint generative-discriminative latent architecture. BIONIC uses pretrained embeddings for complex modalities such as medical images and clinical text, while incorporating structured clinical variables directly within a Bayesian multimodal formulation. The proposed framework enables robust learning in partially observed and semi-supervised settings by explicitly modeling modality-level and variable-level missingness, as well as missing labels. We evaluate BIONIC on three multimodal clinical and biomedical datasets, demonstrating strong and consistent discriminative performance compared to representative multimodal baselines, particularly under incomplete data scenarios. Beyond predictive accuracy, BIONIC provides intrinsic interpretability through its latent structure, enabling population-level analysis of modality relevance and supporting clinically meaningful insight.
Interpretable Generative and Discriminative Learning for Multimodal and Incomplete Clinical Data
Oct 10, 2025Real-world clinical problems are often characterized by multimodal data, usually associated with incomplete views and limited sample sizes in their cohorts, posing significant limitations for machine learning algorithms. In this work, we propose a Bayesian approach designed to efficiently handle these challenges while providing interpretable solutions. Our approach integrates (1) a generative formulation to capture cross-view relationships with a semi-supervised strategy, and (2) a discriminative task-oriented formulation to identify relevant information for specific downstream objectives. This dual generative-discriminative formulation offers both general understanding and task-specific insights; thus, it provides an automatic imputation of the missing views while enabling robust inference across different data sources. The potential of this approach becomes evident when applied to the multimodal clinical data, where our algorithm is able to capture and disentangle the complex interactions among biological, psychological, and sociodemographic modalities.
Unified Bayesian representation for high-dimensional multi-modal biomedical data for small-sample classification
Nov 11, 2024We present BALDUR, a novel Bayesian algorithm designed to deal with multi-modal datasets and small sample sizes in high-dimensional settings while providing explainable solutions. To do so, the proposed model combines within a common latent space the different data views to extract the relevant information to solve the classification task and prune out the irrelevant/redundant features/data views. Furthermore, to provide generalizable solutions in small sample size scenarios, BALDUR efficiently integrates dual kernels over the views with a small sample-to-feature ratio. Finally, its linear nature ensures the explainability of the model outcomes, allowing its use for biomarker identification. This model was tested over two different neurodegeneration datasets, outperforming the state-of-the-art models and detecting features aligned with markers already described in the scientific literature.
The Relevance Feature and Vector Machine for health applications
Feb 11, 2024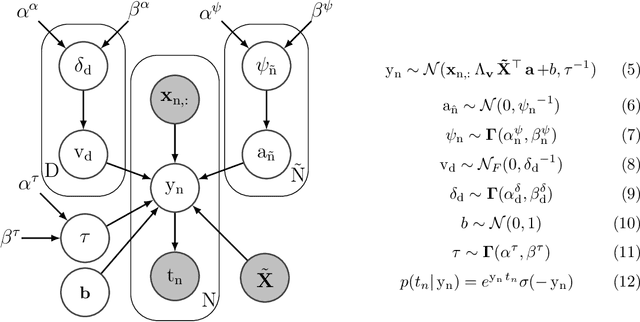
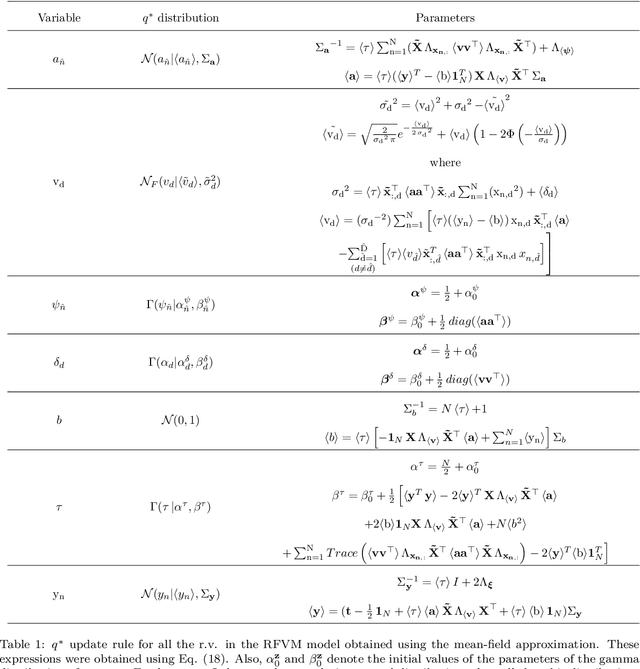
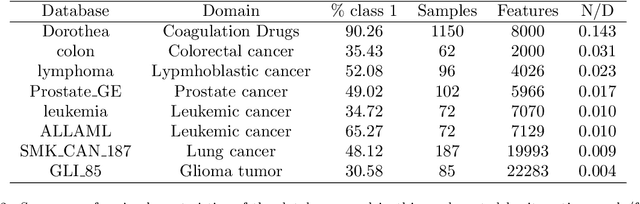
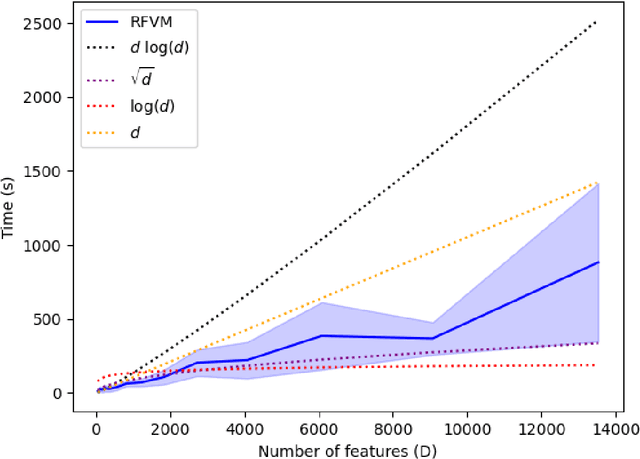
This paper presents the Relevance Feature and Vector Machine (RFVM), a novel model that addresses the challenges of the fat-data problem when dealing with clinical prospective studies. The fat-data problem refers to the limitations of Machine Learning (ML) algorithms when working with databases in which the number of features is much larger than the number of samples (a common scenario in certain medical fields). To overcome such limitations, the RFVM incorporates different characteristics: (1) A Bayesian formulation which enables the model to infer its parameters without overfitting thanks to the Bayesian model averaging. (2) A joint optimisation that overcomes the limitations arising from the fat-data characteristic by simultaneously including the variables that define the primal space (features) and those that define the dual space (observations). (3) An integrated prunning that removes the irrelevant features and samples during the training iterative optimization. Also, this last point turns out crucial when performing medical prospective studies, enabling researchers to exclude unnecessary medical tests, reducing costs and inconvenience for patients, and identifying the critical patients/subjects that characterize the disorder and, subsequently, optimize the patient recruitment process that leads to a balanced cohort. The model capabilities are tested against state-of-the-art models in several medical datasets with fat-data problems. These experimental works show that RFVM is capable of achieving competitive classification accuracies while providing the most compact subset of data (in both terms of features and samples). Moreover, the selected features (medical tests) seem to be aligned with the existing medical literature.