 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Relevance Feature and Vector Machine for health applications
Paper and Code
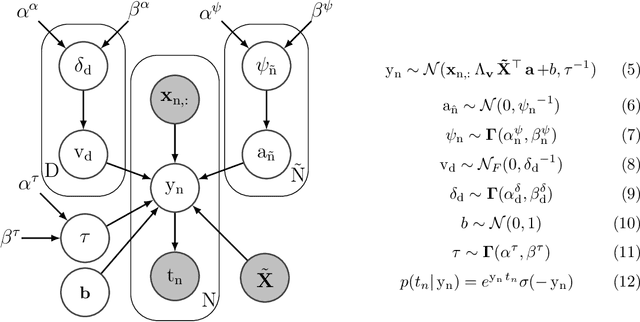
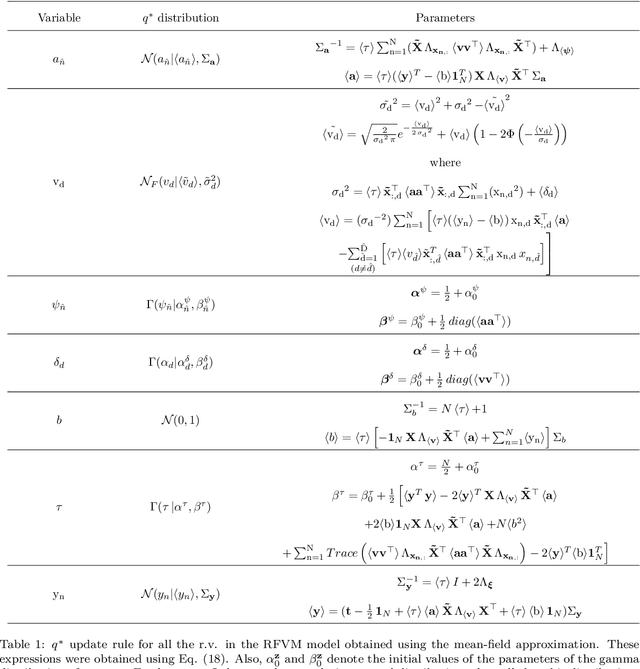
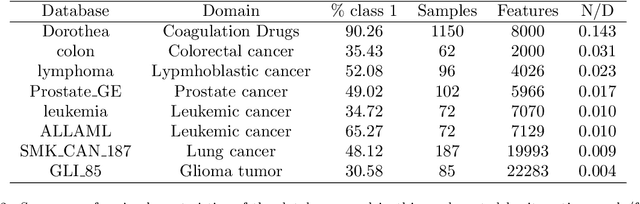
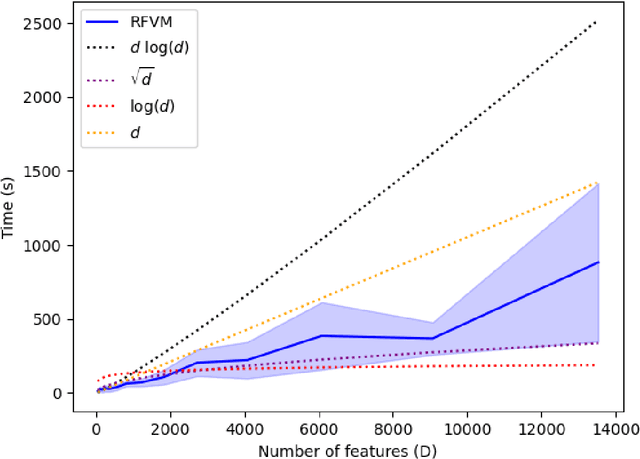
This paper presents the Relevance Feature and Vector Machine (RFVM), a novel model that addresses the challenges of the fat-data problem when dealing with clinical prospective studies. The fat-data problem refers to the limitations of Machine Learning (ML) algorithms when working with databases in which the number of features is much larger than the number of samples (a common scenario in certain medical fields). To overcome such limitations, the RFVM incorporates different characteristics: (1) A Bayesian formulation which enables the model to infer its parameters without overfitting thanks to the Bayesian model averaging. (2) A joint optimisation that overcomes the limitations arising from the fat-data characteristic by simultaneously including the variables that define the primal space (features) and those that define the dual space (observations). (3) An integrated prunning that removes the irrelevant features and samples during the training iterative optimization. Also, this last point turns out crucial when performing medical prospective studies, enabling researchers to exclude unnecessary medical tests, reducing costs and inconvenience for patients, and identifying the critical patients/subjects that characterize the disorder and, subsequently, optimize the patient recruitment process that leads to a balanced cohort. The model capabilities are tested against state-of-the-art models in several medical datasets with fat-data problems. These experimental works show that RFVM is capable of achieving competitive classification accuracies while providing the most compact subset of data (in both terms of features and samples). Moreover, the selected features (medical tests) seem to be aligned with the existing medical literature.