 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultural Diffusion and Trends in Facebook Photographs
May 24, 2017
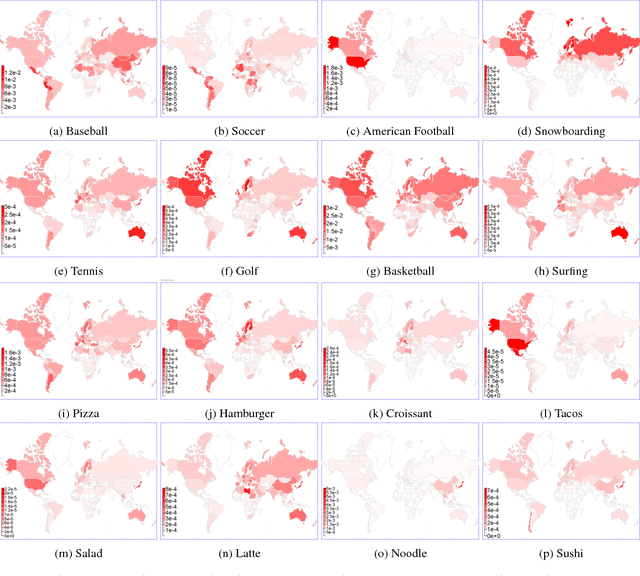
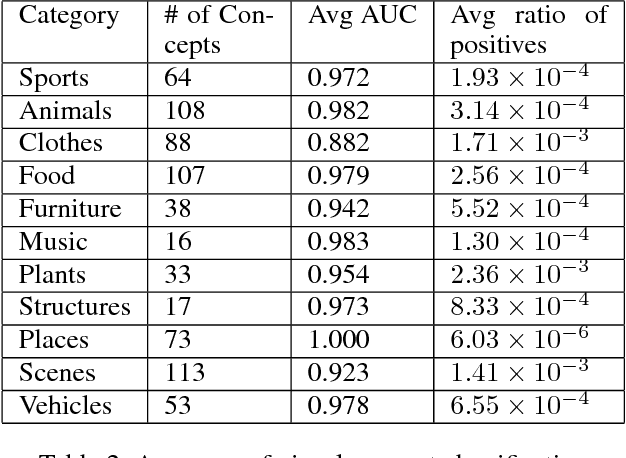
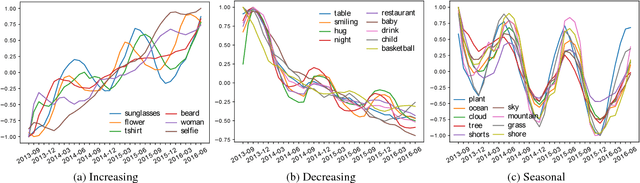
Online social media is a social vehicle in which people share various moments of their lives with their friends, such as playing sports, cooking dinner or just taking a selfie for fun, via visual means, that is, photographs. Our study takes a closer look at the popular visual concepts illustrating various cultural lifestyles from aggregated, de-identified photographs. We perform analysis both at macroscopic and microscopic levels, to gain novel insights about global and local visual trends as well as the dynamics of interpersonal cultural exchange and diffusion among Facebook friends. We processed images by automatically classifying the visual content by a convolutional neural network (CNN). Through various statistical tests, we find that socially tied individuals more likely post images showing similar cultural lifestyles. To further identify the main cause of the observed social correlation, we use the Shuffle test and the Preference-based Matched Estimation (PME) test to distinguish the effects of influence and homophily. The results indicate that the visual content of each user's photographs are temporally, although not necessarily causally, correlated with the photographs of their friends, which may suggest the effect of influence. Our paper demonstrates that Facebook photographs exhibit diverse cultural lifestyles and preferences and that the social interaction mediated through the visual channel in social media can be an effective mechanism for cultural diffusion.
State-Space Dynamics Distance for Clustering Sequential Data
Apr 09, 2010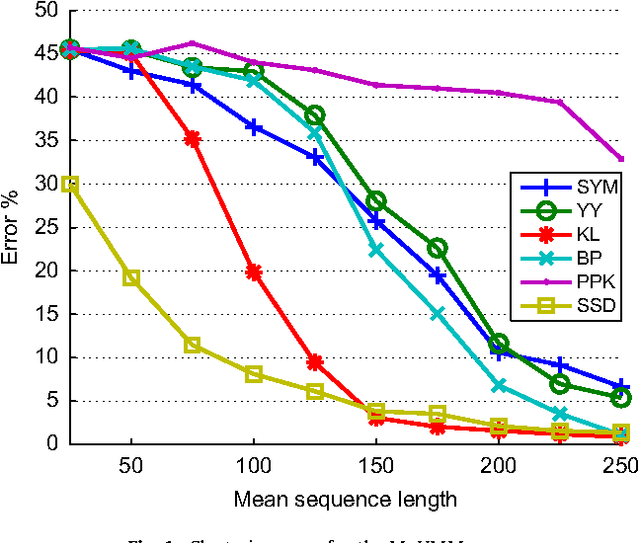
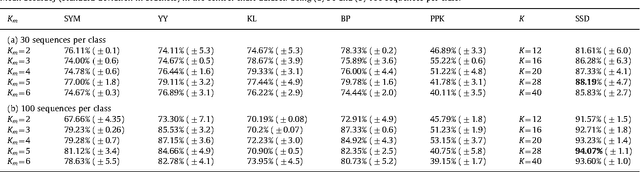
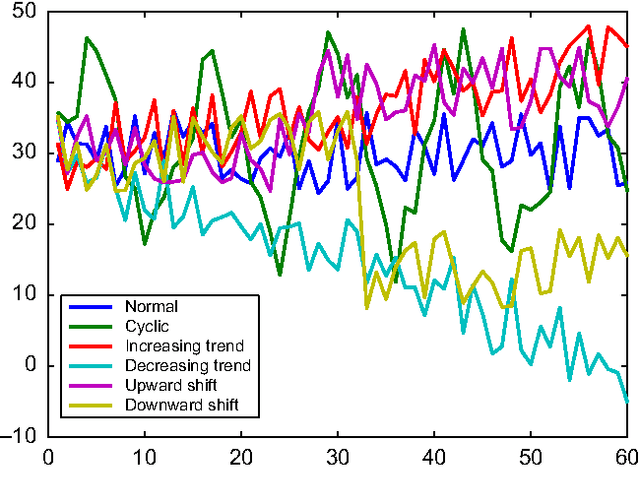
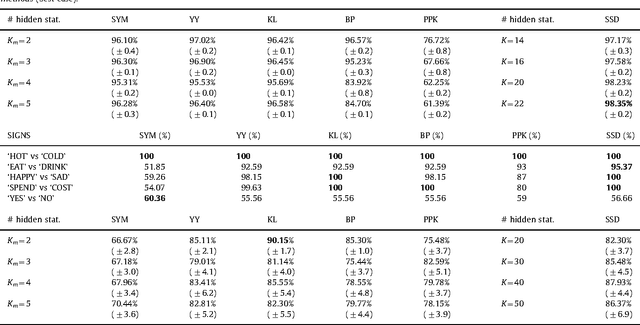
This paper proposes a novel similarity measure for clustering sequential data. We first construct a common state-space by training a single probabilistic model with all the sequences in order to get a unified representation for the dataset. Then, distances are obtained attending to the transition matrices induced by each sequence in that state-space. This approach solves some of the usual overfitting and scalability issues of the existing semi-parametric techniques, that rely on training a model for each sequence. Empirical studies on both synthetic and real-world datasets illustrate the advantages of the proposed similarity measure for clustering sequences.