 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNA-KG: An ontology-based knowledge graph for representing interactions involving RNA molecules
Nov 30, 2023The "RNA world" represents a novel frontier for the study of fundamental biological processes and human diseases and is paving the way for the development of new drugs tailored to the patient's biomolecular characteristics. Although scientific data about coding and non-coding RNA molecules are continuously produced and available from public repositories, they are scattered across different databases and a centralized, uniform, and semantically consistent representation of the "RNA world" is still lacking. We propose RNA-KG, a knowledge graph encompassing biological knowledge about RNAs gathered from more than 50 public databases, integrating functional relationships with genes, proteins, and chemicals and ontologically grounded biomedical concepts. To develop RNA-KG, we first identified, pre-processed, and characterized each data source; next, we built a meta-graph that provides an ontological description of the KG by representing all the bio-molecular entities and medical concepts of interest in this domain, as well as the types of interactions connecting them. Finally, we leveraged an instance-based semantically abstracted knowledge model to specify the ontological alignment according to which RNA-KG was generated. RNA-KG can be downloaded in different formats and also queried by a SPARQL endpoint. A thorough topological analysis of the resulting heterogeneous graph provides further insights into the characteristics of the "RNA world". RNA-KG can be both directly explored and visualized, and/or analyzed by applying computational methods to infer bio-medical knowledge from its heterogeneous nodes and edges. The resource can be easily updated with new experimental data, and specific views of the overall KG can be extracted according to the bio-medical problem to be studied.
An Open-Source Knowledge Graph Ecosystem for the Life Sciences
Jul 11, 2023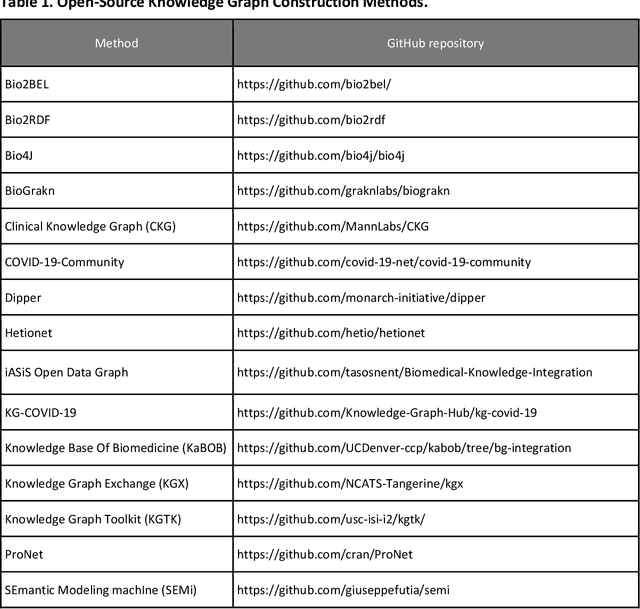
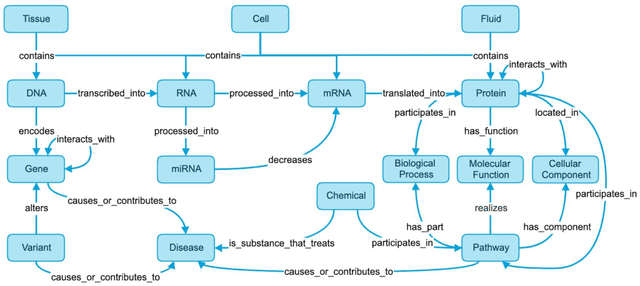
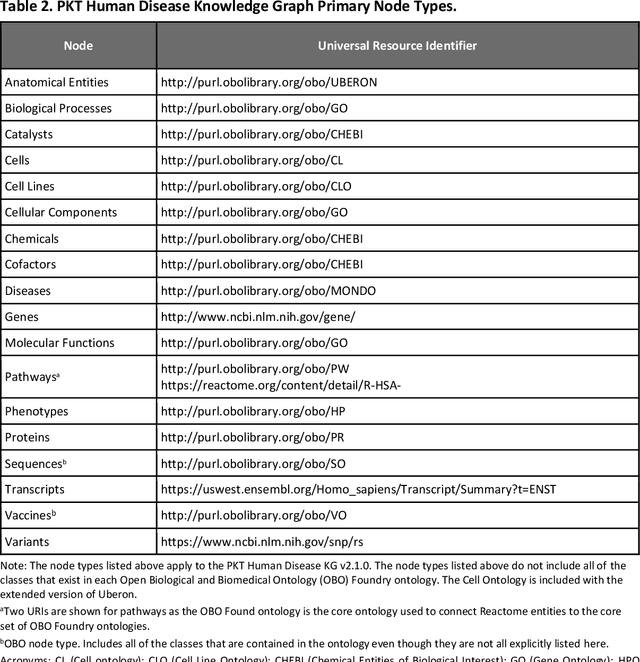
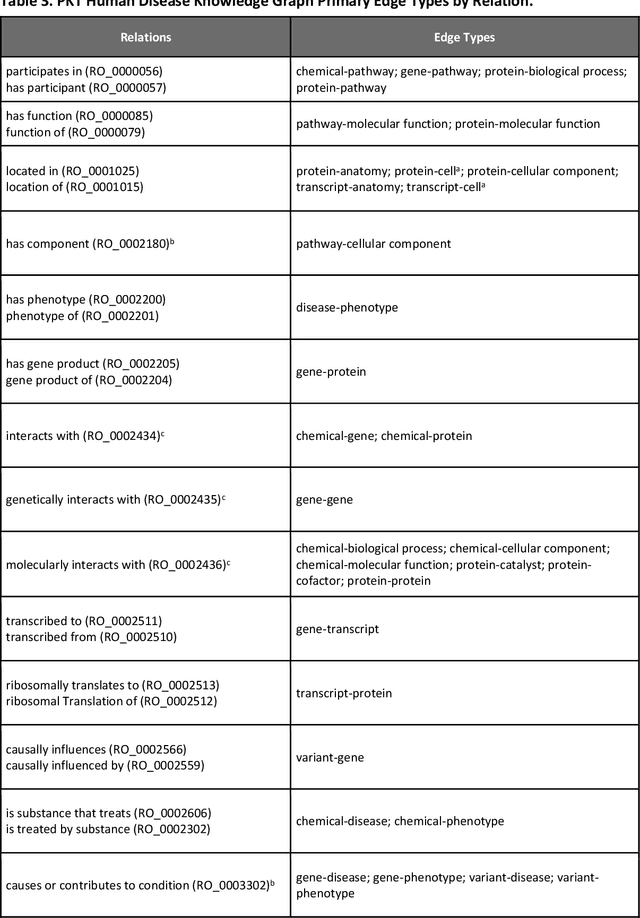
Translational research requires data at multiple scales of biological organization. Advancements in sequencing and multi-omics technologies have increased the availability of these data but researchers face significant integration challenges. Knowledge graphs (KGs) are used to model complex phenomena, and methods exist to automatically construct them. However, tackling complex biomedical integration problems requires flexibility in the way knowledge is modeled. Moreover, existing KG construction methods provide robust tooling at the cost of fixed or limited choices among knowledge representation models. PheKnowLator (Phenotype Knowledge Translator) is a semantic ecosystem for automating the FAIR (Findable, Accessible, Interoperable, and Reusable) construction of ontologically grounded KGs with fully customizable knowledge representation. The ecosystem includes KG construction resources (e.g., data preparation APIs), analysis tools (e.g., SPARQL endpoints and abstraction algorithms), and benchmarks (e.g., prebuilt KGs and embeddings). We evaluate the ecosystem by surveying open-source KG construction methods and analyzing its computational performance when constructing 12 large-scale KGs. With flexible knowledge representation, PheKnowLator enables fully customizable KGs without compromising performance or usability.