 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing Wideband Absorbance Immittance in Normal and Ears with Otitis Media with Effusion Using Machine Learning
Mar 04, 2021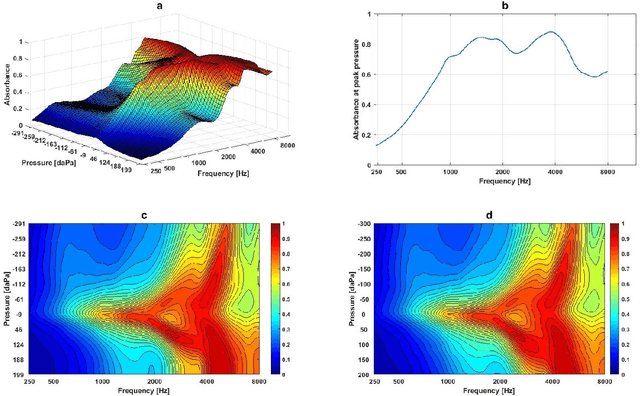
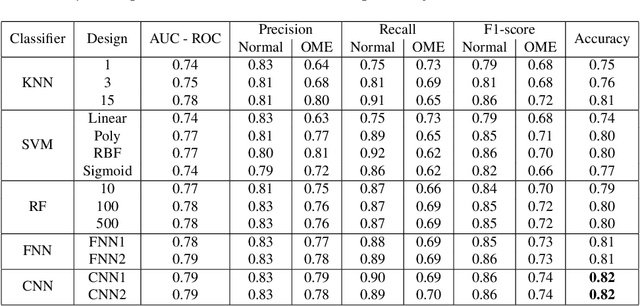
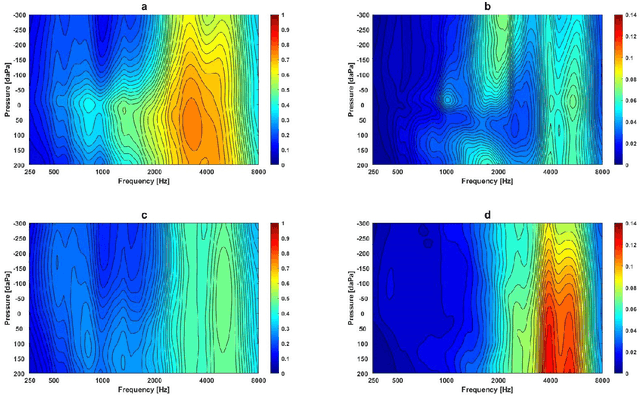
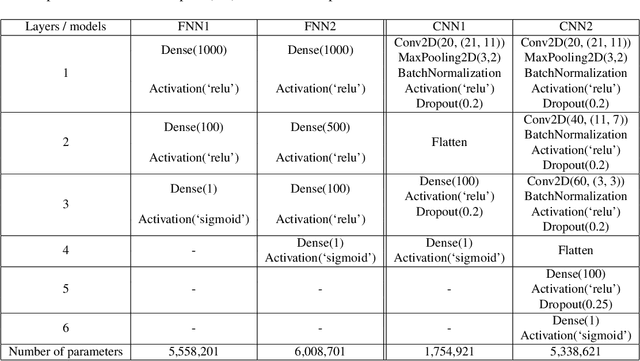
Wideband Absorbance Immittance (WAI) has been available for more than a decade, however its clinical use still faces the challenges of limited understanding and poor interpretation of WAI results. This study aimed to develop Machine Learning (ML) tools to identify the WAI absorbance characteristics across different frequency-pressure regions in the normal middle ear and ears with otitis media with effusion (OME) to enable diagnosis of middle ear conditions automatically. Data analysis including pre-processing of the WAI data, statistical analysis and classification model development, together with key regions extraction from the 2D frequency-pressure WAI images are conducted in this study. Our experimental results show that ML tools appear to hold great potential for the automated diagnosis of middle ear diseases from WAI data. The identified key regions in the WAI provide guidance to practitioners to better understand and interpret WAI data and offer the prospect of quick and accurate diagnostic decisions.
Multi-Band Multi-Resolution Fully Convolutional Neural Networks for Singing Voice Separation
Oct 21, 2019
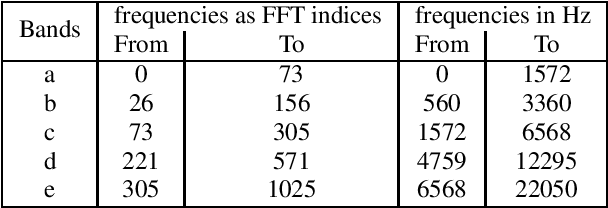

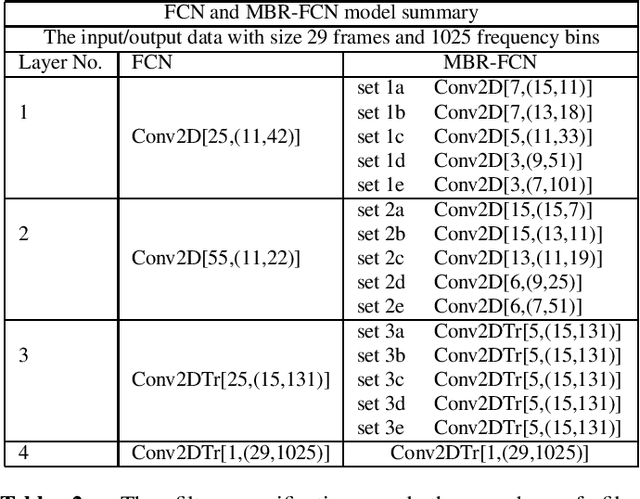
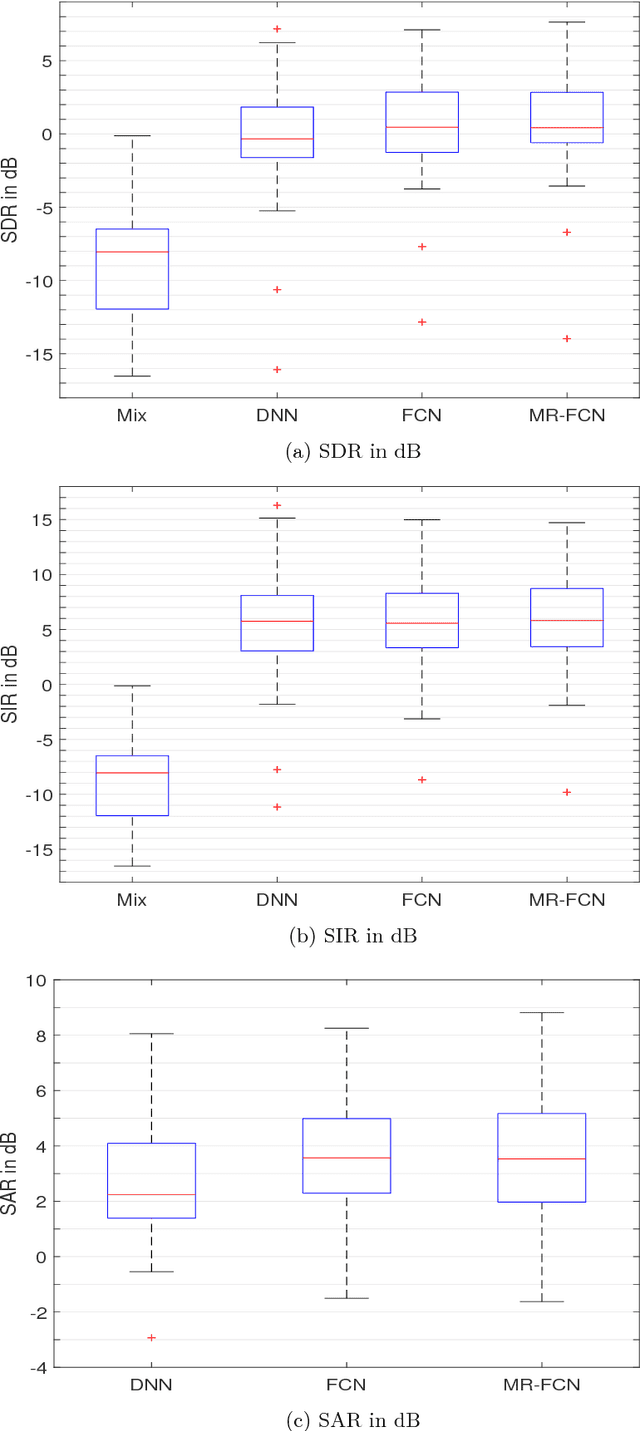
Deep neural networks with convolutional layers usually process the entire spectrogram of an audio signal with the same time-frequency resolutions, number of filters, and dimensionality reduction scale. According to the constant-Q transform, good features can be extracted from audio signals if the low frequency bands are processed with high frequency resolution filters and the high frequency bands with high time resolution filters. In the spectrogram of a mixture of singing voices and music signals, there is usually more information about the voice in the low frequency bands than the high frequency bands. These raise the need for processing each part of the spectrogram differently. In this paper, we propose a multi-band multi-resolution fully convolutional neural network (MBR-FCN) for singing voice separation. The MBR-FCN processes the frequency bands that have more information about the target signals with more filters and smaller dimentionality reduction scale than the bands with less information. Furthermore, the MBR-FCN processes the low frequency bands with high frequency resolution filters and the high frequency bands with high time resolution filters. Our experimental results show that the proposed MBR-FCN with very few parameters achieves better singing voice separation performance than other deep neural networks.
Referenceless Performance Evaluation of Audio Source Separation using Deep Neural Networks
Nov 01, 2018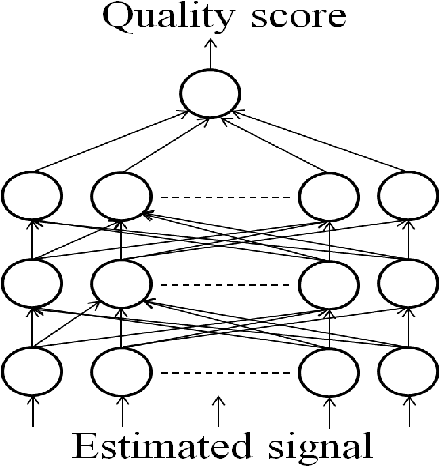
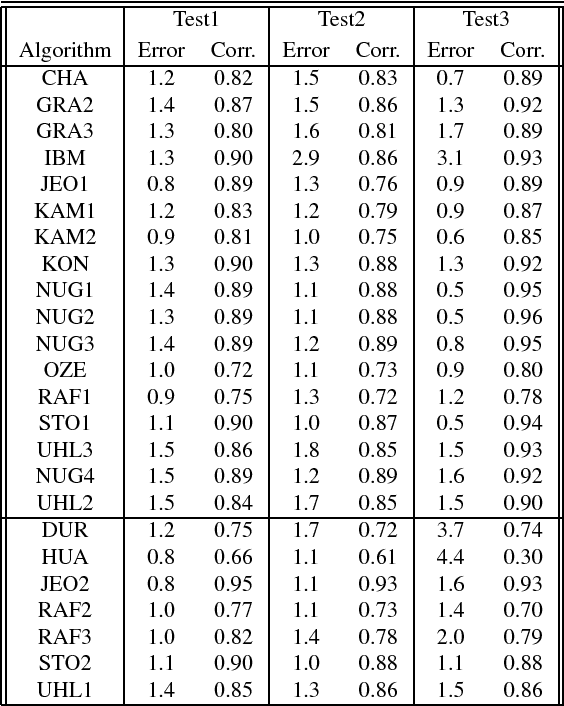
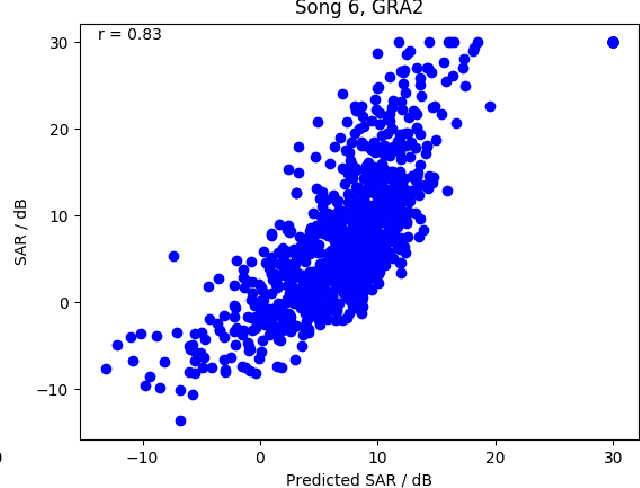
Current performance evaluation for audio source separation depends on comparing the processed or separated signals with reference signals. Therefore, common performance evaluation toolkits are not applicable to real-world situations where the ground truth audio is unavailable. In this paper, we propose a performance evaluation technique that does not require reference signals in order to assess separation quality. The proposed technique uses a deep neural network (DNN) to map the processed audio into its quality score. Our experiment results show that the DNN is capable of predicting the sources-to-artifacts ratio from the blind source separation evaluation toolkit without the need for reference signals.
Raw Multi-Channel Audio Source Separation using Multi-Resolution Convolutional Auto-Encoders
Mar 02, 2018


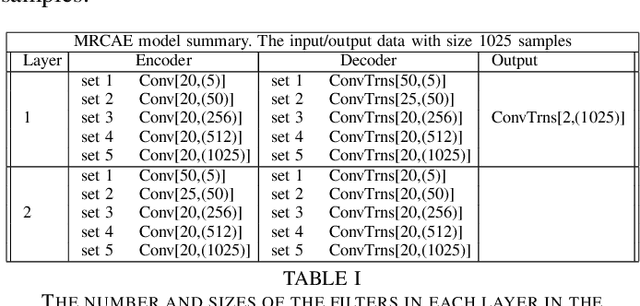
Supervised multi-channel audio source separation requires extracting useful spectral, temporal, and spatial features from the mixed signals. The success of many existing systems is therefore largely dependent on the choice of features used for training. In this work, we introduce a novel multi-channel, multi-resolution convolutional auto-encoder neural network that works on raw time-domain signals to determine appropriate multi-resolution features for separating the singing-voice from stereo music. Our experimental results show that the proposed method can achieve multi-channel audio source separation without the need for hand-crafted features or any pre- or post-processing.
Multi-Resolution Fully Convolutional Neural Networks for Monaural Audio Source Separation
Oct 28, 2017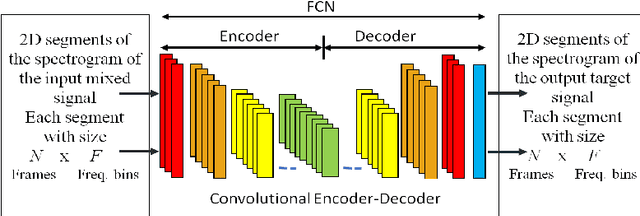
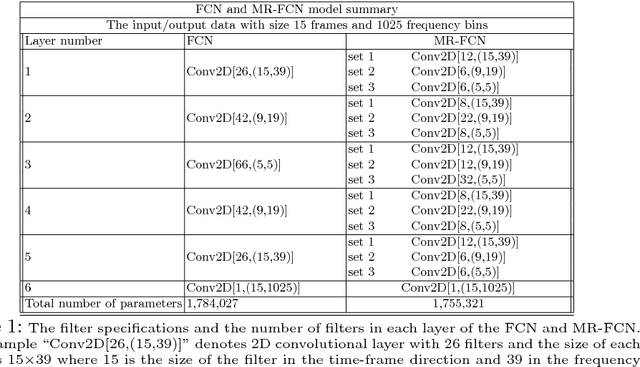
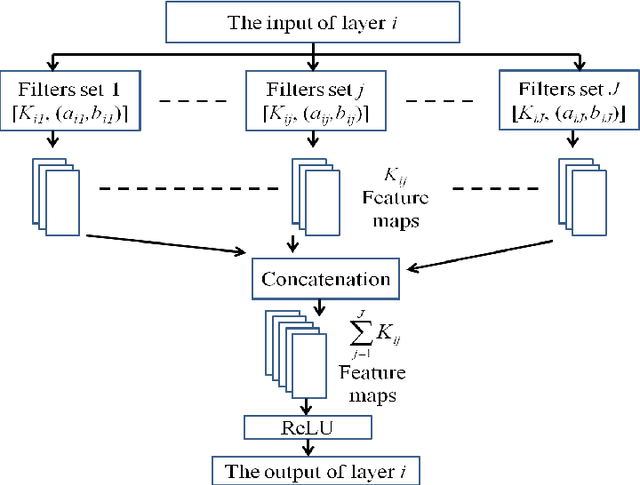
In deep neural networks with convolutional layers, each layer typically has fixed-size/single-resolution receptive field (RF). Convolutional layers with a large RF capture global information from the input features, while layers with small RF size capture local details with high resolution from the input features. In this work, we introduce novel deep multi-resolution fully convolutional neural networks (MR-FCNN), where each layer has different RF sizes to extract multi-resolution features that capture the global and local details information from its input features. The proposed MR-FCNN is applied to separate a target audio source from a mixture of many audio sources. Experimental results show that using MR-FCNN improves the performance compared to feedforward deep neural networks (DNNs) and single resolution deep fully convolutional neural networks (FCNNs) on the audio source separation problem.
Deep neural networks for single channel source separation
Nov 12, 2013
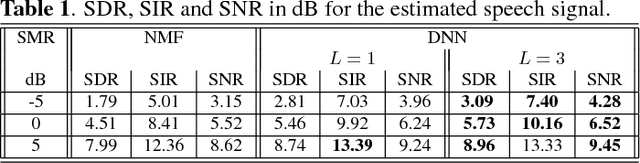
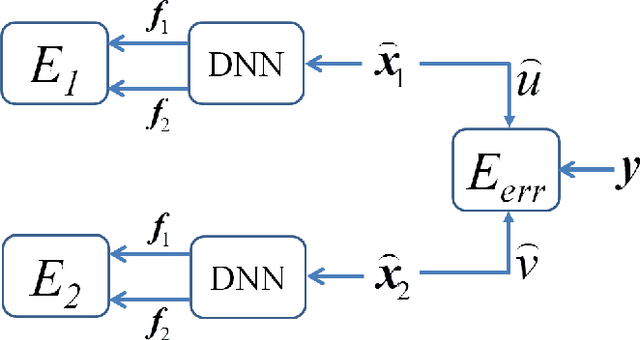
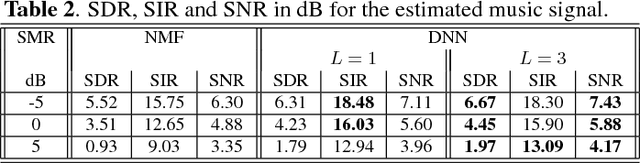
In this paper, a novel approach for single channel source separation (SCSS) using a deep neural network (DNN) architecture is introduced. Unlike previous studies in which DNN and other classifiers were used for classifying time-frequency bins to obtain hard masks for each source, we use the DNN to classify estimated source spectra to check for their validity during separation. In the training stage, the training data for the source signals are used to train a DNN. In the separation stage, the trained DNN is utilized to aid in estimation of each source in the mixed signal. Single channel source separation problem is formulated as an energy minimization problem where each source spectra estimate is encouraged to fit the trained DNN model and the mixed signal spectrum is encouraged to be written as a weighted sum of the estimated source spectra. The proposed approach works regardless of the energy scale differences between the source signals in the training and separation stages. Nonnegative matrix factorization (NMF) is used to initialize the DNN estimate for each source. The experimental results show that using DNN initialized by NMF for source separation improves the quality of the separated signal compared with using NMF for source separation.
Source Separation using Regularized NMF with MMSE Estimates under GMM Priors with Online Learning for The Uncertainties
Feb 28, 2013

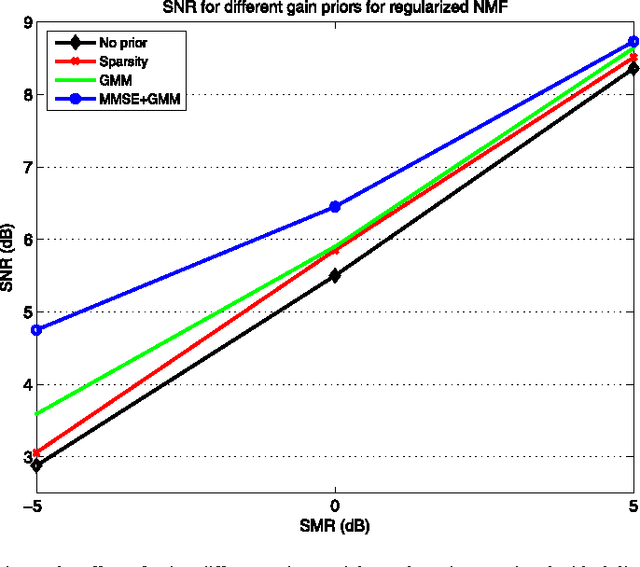

We propose a new method to enforce priors on the solution of the nonnegative matrix factorization (NMF). The proposed algorithm can be used for denoising or single-channel source separation (SCSS) applications. The NMF solution is guided to follow the Minimum Mean Square Error (MMSE) estimates under Gaussian mixture prior models (GMM) for the source signal. In SCSS applications, the spectra of the observed mixed signal are decomposed as a weighted linear combination of trained basis vectors for each source using NMF. In this work, the NMF decomposition weight matrices are treated as a distorted image by a distortion operator, which is learned directly from the observed signals. The MMSE estimate of the weights matrix under GMM prior and log-normal distribution for the distortion is then found to improve the NMF decomposition results. The MMSE estimate is embedded within the optimization objective to form a novel regularized NMF cost function. The corresponding update rules for the new objectives are derived in this paper. Experimental results show that, the proposed regularized NMF algorithm improves the source separation performance compared with using NMF without prior or with other prior models.