 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferenceless Performance Evaluation of Audio Source Separation using Deep Neural Networks
Nov 01, 2018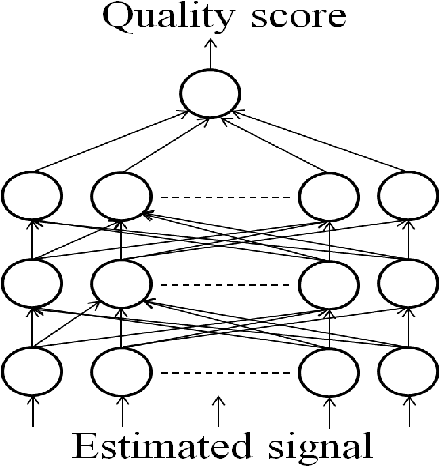
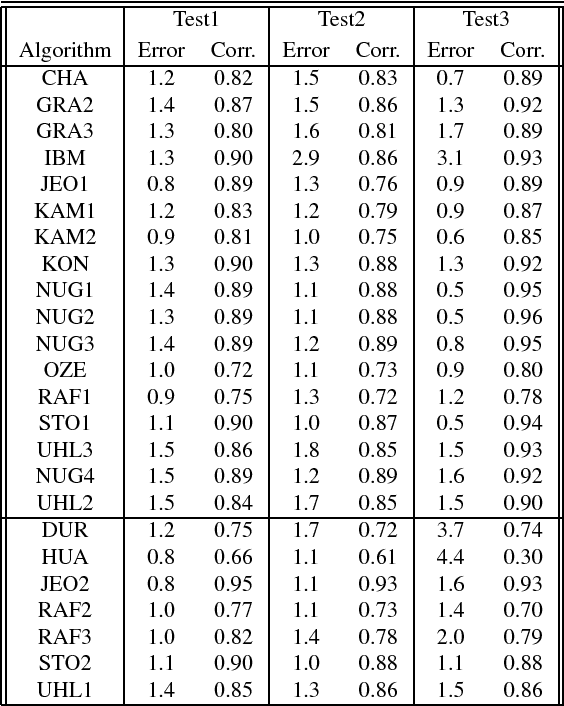
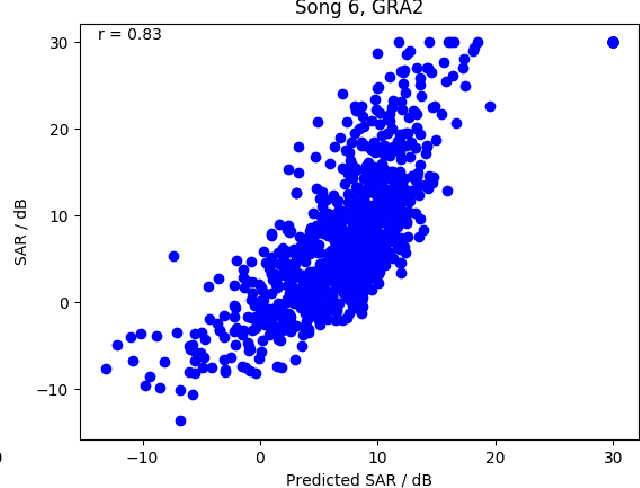
Current performance evaluation for audio source separation depends on comparing the processed or separated signals with reference signals. Therefore, common performance evaluation toolkits are not applicable to real-world situations where the ground truth audio is unavailable. In this paper, we propose a performance evaluation technique that does not require reference signals in order to assess separation quality. The proposed technique uses a deep neural network (DNN) to map the processed audio into its quality score. Our experiment results show that the DNN is capable of predicting the sources-to-artifacts ratio from the blind source separation evaluation toolkit without the need for reference signals.
Raw Multi-Channel Audio Source Separation using Multi-Resolution Convolutional Auto-Encoders
Mar 02, 2018


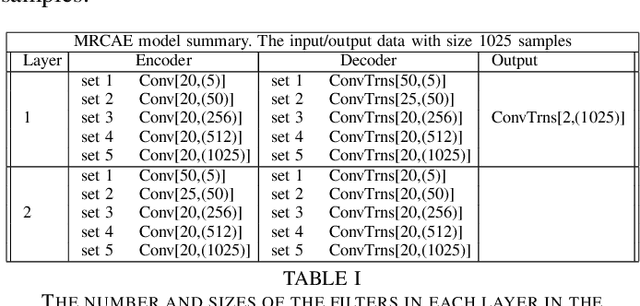
Supervised multi-channel audio source separation requires extracting useful spectral, temporal, and spatial features from the mixed signals. The success of many existing systems is therefore largely dependent on the choice of features used for training. In this work, we introduce a novel multi-channel, multi-resolution convolutional auto-encoder neural network that works on raw time-domain signals to determine appropriate multi-resolution features for separating the singing-voice from stereo music. Our experimental results show that the proposed method can achieve multi-channel audio source separation without the need for hand-crafted features or any pre- or post-processing.
Multi-Resolution Fully Convolutional Neural Networks for Monaural Audio Source Separation
Oct 28, 2017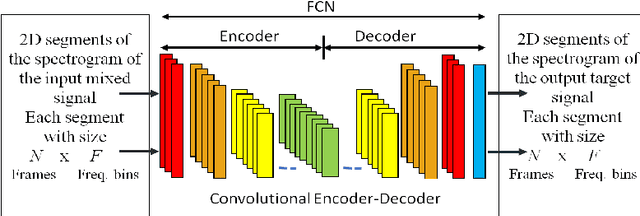
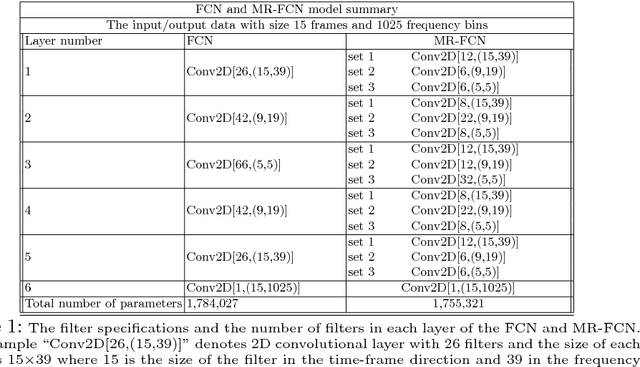
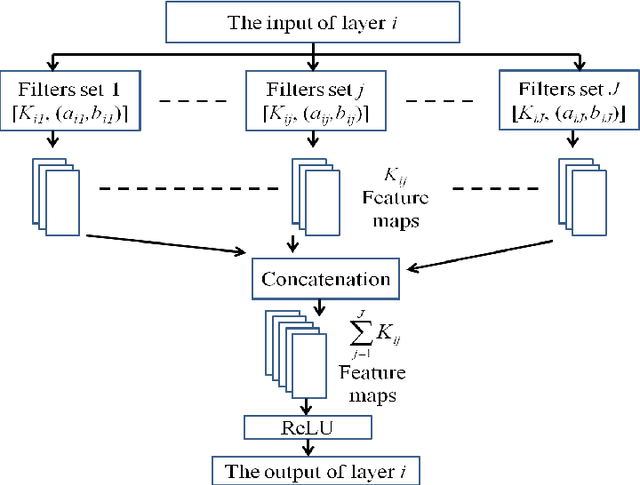
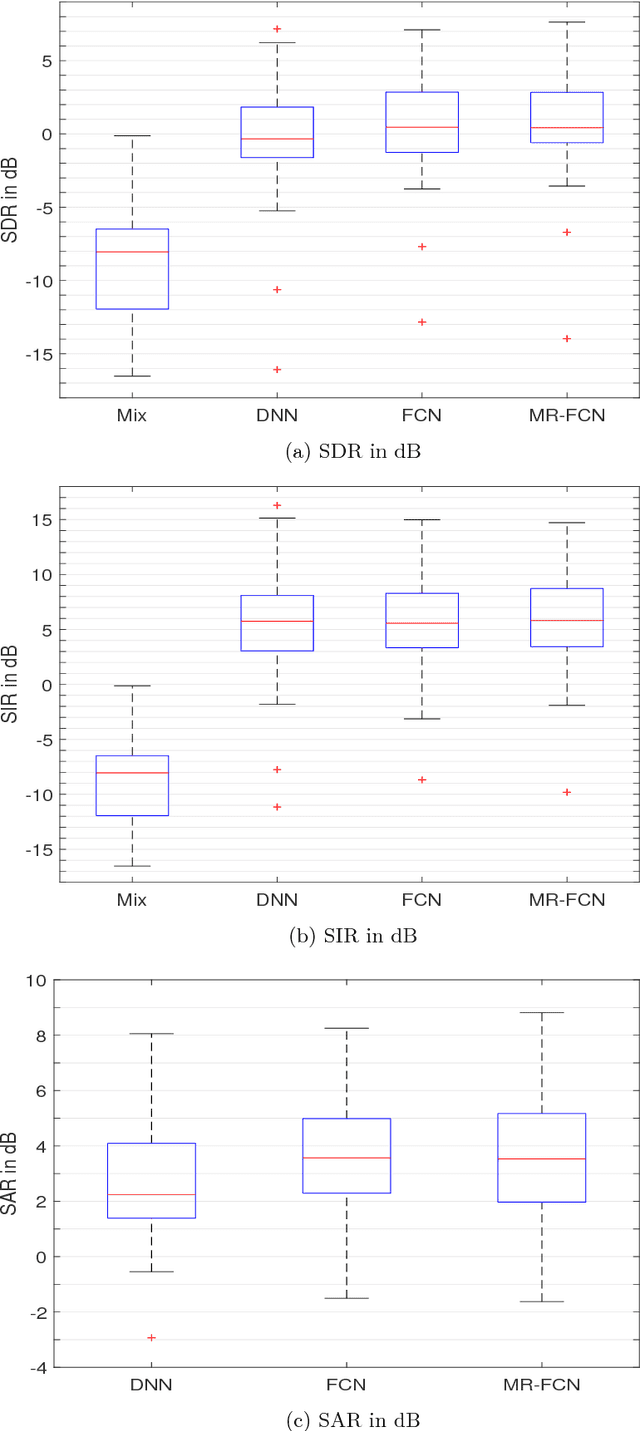
In deep neural networks with convolutional layers, each layer typically has fixed-size/single-resolution receptive field (RF). Convolutional layers with a large RF capture global information from the input features, while layers with small RF size capture local details with high resolution from the input features. In this work, we introduce novel deep multi-resolution fully convolutional neural networks (MR-FCNN), where each layer has different RF sizes to extract multi-resolution features that capture the global and local details information from its input features. The proposed MR-FCNN is applied to separate a target audio source from a mixture of many audio sources. Experimental results show that using MR-FCNN improves the performance compared to feedforward deep neural networks (DNNs) and single resolution deep fully convolutional neural networks (FCNNs) on the audio source separation problem.