Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaw Multi-Channel Audio Source Separation using Multi-Resolution Convolutional Auto-Encoders
Paper and Code



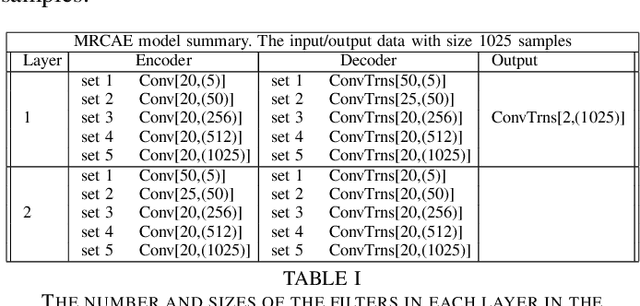
Supervised multi-channel audio source separation requires extracting useful spectral, temporal, and spatial features from the mixed signals. The success of many existing systems is therefore largely dependent on the choice of features used for training. In this work, we introduce a novel multi-channel, multi-resolution convolutional auto-encoder neural network that works on raw time-domain signals to determine appropriate multi-resolution features for separating the singing-voice from stereo music. Our experimental results show that the proposed method can achieve multi-channel audio source separation without the need for hand-crafted features or any pre- or post-processing.
View paper on