 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKroneckerBERT: Learning Kronecker Decomposition for Pre-trained Language Models via Knowledge Distillation
Sep 13, 2021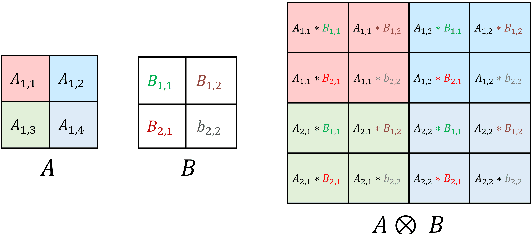
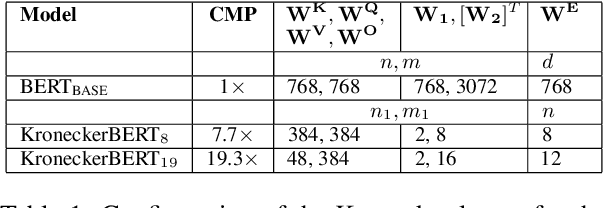
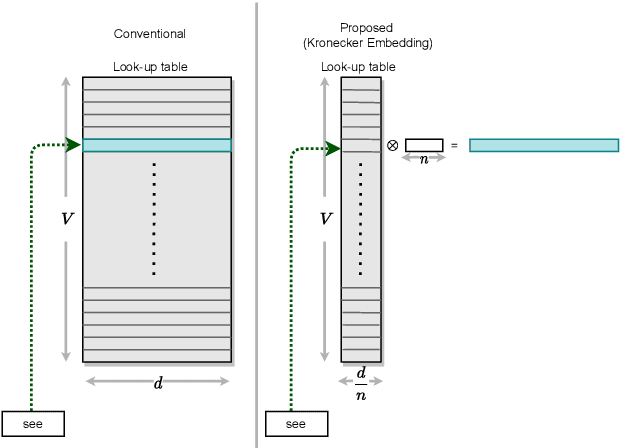
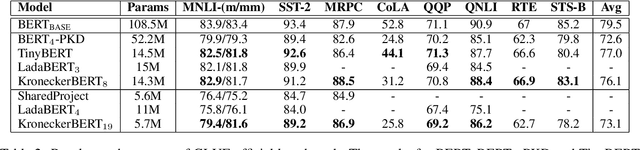
The development of over-parameterized pre-trained language models has made a significant contribution toward the success of natural language processing. While over-parameterization of these models is the key to their generalization power, it makes them unsuitable for deployment on low-capacity devices. We push the limits of state-of-the-art Transformer-based pre-trained language model compression using Kronecker decomposition. We use this decomposition for compression of the embedding layer, all linear mappings in the multi-head attention, and the feed-forward network modules in the Transformer layer. We perform intermediate-layer knowledge distillation using the uncompressed model as the teacher to improve the performance of the compressed model. We present our KroneckerBERT, a compressed version of the BERT_BASE model obtained using this framework. We evaluate the performance of KroneckerBERT on well-known NLP benchmarks and show that for a high compression factor of 19 (5% of the size of the BERT_BASE model), our KroneckerBERT outperforms state-of-the-art compression methods on the GLUE. Our experiments indicate that the proposed model has promising out-of-distribution robustness and is superior to the state-of-the-art compression methods on SQuAD.
Block Pruning For Faster Transformers
Sep 10, 2021

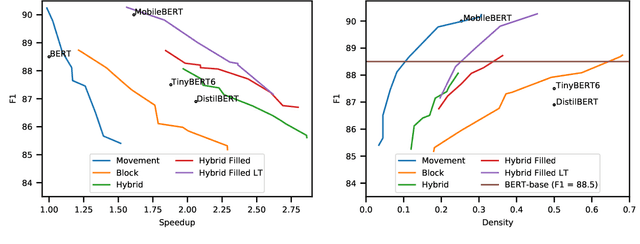

Pre-training has improved model accuracy for both classification and generation tasks at the cost of introducing much larger and slower models. Pruning methods have proven to be an effective way of reducing model size, whereas distillation methods are proven for speeding up inference. We introduce a block pruning approach targeting both small and fast models. Our approach extends structured methods by considering blocks of any size and integrates this structure into the movement pruning paradigm for fine-tuning. We find that this approach learns to prune out full components of the underlying model, such as attention heads. Experiments consider classification and generation tasks, yielding among other results a pruned model that is a 2.4x faster, 74% smaller BERT on SQuAD v1, with a 1% drop on F1, competitive both with distilled models in speed and pruned models in size.
Fully Quantized Transformer for Improved Translation
Nov 23, 2019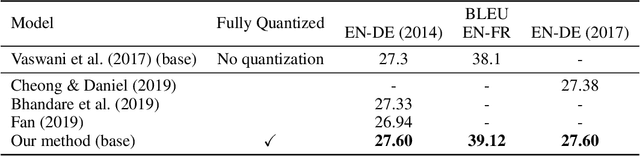
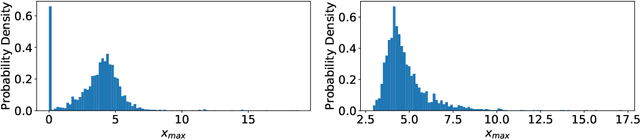
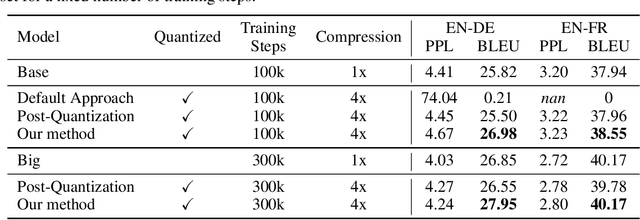
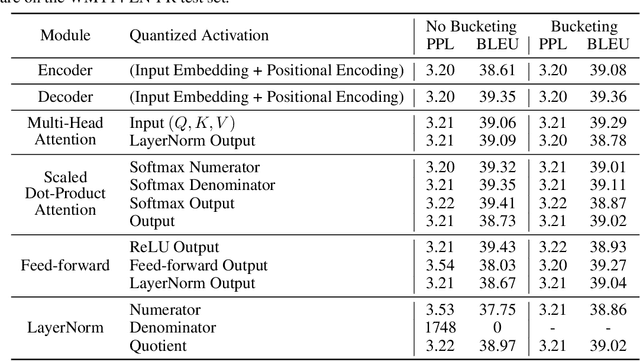
State-of-the-art neural machine translation methods employ massive amounts of parameters. Drastically reducing computational costs of such methods without affecting performance has been up to this point unsuccessful. To the best of our knowledge, we are the first to propose a quantization strategy inclusive of all components of the Transformer. We are also the first to show that it is possible to avoid any loss in translation quality with a fully quantized network. Indeed, our 8-bit models consistently score equal or higher BLEU than the full-precision variant on multiple translation datasets. Comparing ourselves to all previously proposed methods, we achieve state-of-the-art quantization results.