 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKroneckerBERT: Learning Kronecker Decomposition for Pre-trained Language Models via Knowledge Distillation
Paper and Code
Sep 13, 2021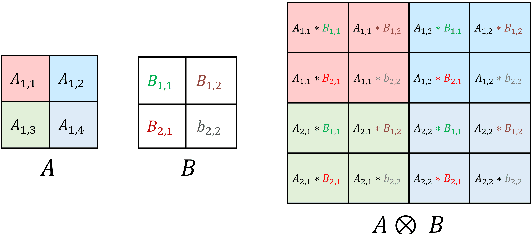
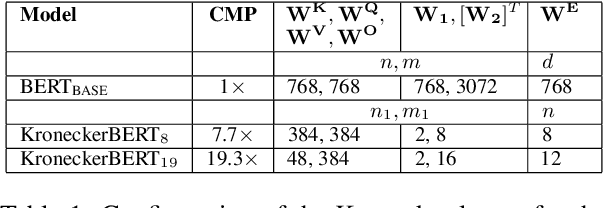
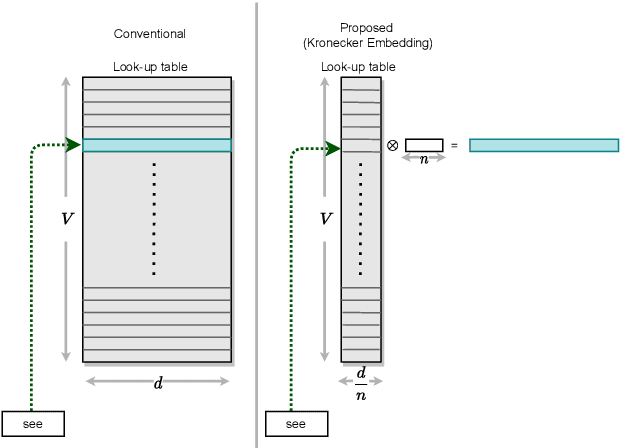
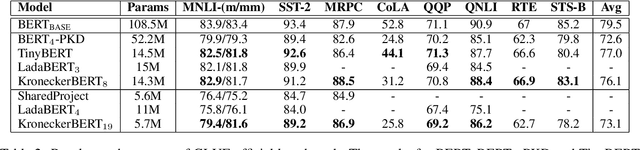
The development of over-parameterized pre-trained language models has made a significant contribution toward the success of natural language processing. While over-parameterization of these models is the key to their generalization power, it makes them unsuitable for deployment on low-capacity devices. We push the limits of state-of-the-art Transformer-based pre-trained language model compression using Kronecker decomposition. We use this decomposition for compression of the embedding layer, all linear mappings in the multi-head attention, and the feed-forward network modules in the Transformer layer. We perform intermediate-layer knowledge distillation using the uncompressed model as the teacher to improve the performance of the compressed model. We present our KroneckerBERT, a compressed version of the BERT_BASE model obtained using this framework. We evaluate the performance of KroneckerBERT on well-known NLP benchmarks and show that for a high compression factor of 19 (5% of the size of the BERT_BASE model), our KroneckerBERT outperforms state-of-the-art compression methods on the GLUE. Our experiments indicate that the proposed model has promising out-of-distribution robustness and is superior to the state-of-the-art compression methods on SQuAD.