Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Quantized Transformer for Improved Translation
Paper and Code
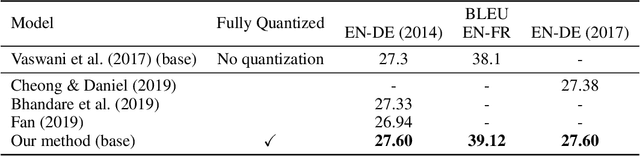
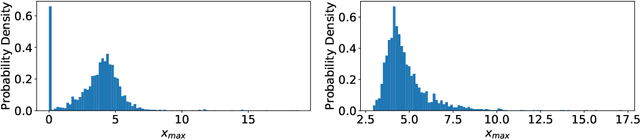
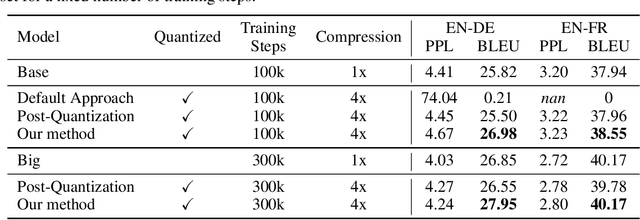
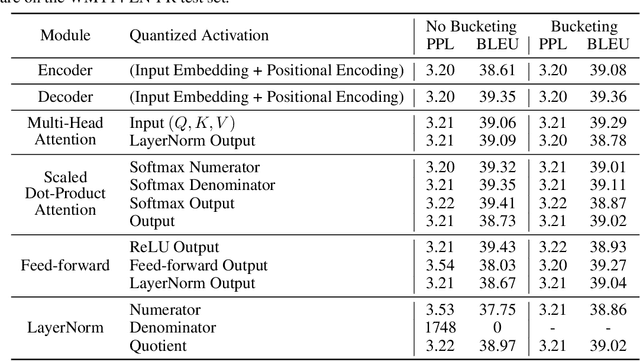
State-of-the-art neural machine translation methods employ massive amounts of parameters. Drastically reducing computational costs of such methods without affecting performance has been up to this point unsuccessful. To the best of our knowledge, we are the first to propose a quantization strategy inclusive of all components of the Transformer. We are also the first to show that it is possible to avoid any loss in translation quality with a fully quantized network. Indeed, our 8-bit models consistently score equal or higher BLEU than the full-precision variant on multiple translation datasets. Comparing ourselves to all previously proposed methods, we achieve state-of-the-art quantization results.
View paper on
 OpenReview
OpenReview