 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Meta Active Learning
Mar 09, 2022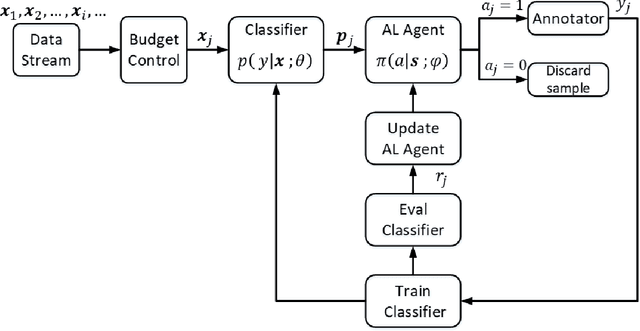
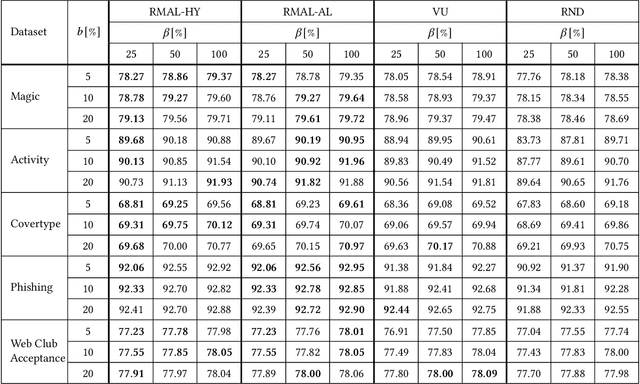

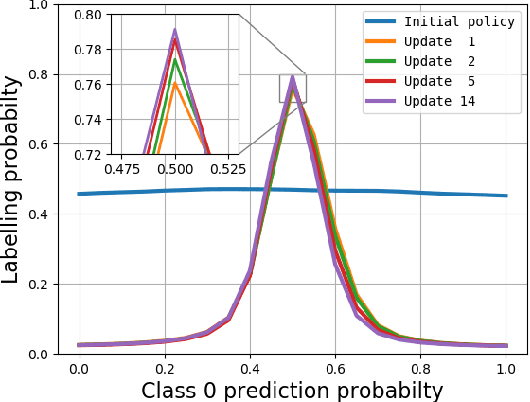
In stream-based active learning, the learning procedure typically has access to a stream of unlabeled data instances and must decide for each instance whether to label it and use it for training or to discard it. There are numerous active learning strategies which try to minimize the number of labeled samples required for training in this setting by identifying and retaining the most informative data samples. Most of these schemes are rule-based and rely on the notion of uncertainty, which captures how small the distance of a data sample is from the classifier's decision boundary. Recently, there have been some attempts to learn optimal selection strategies directly from the data, but many of them are still lacking generality for several reasons: 1) They focus on specific classification setups, 2) They rely on rule-based metrics, 3) They require offline pre-training of the active learner on related tasks. In this work we address the above limitations and present an online stream-based meta active learning method which learns on the fly an informativeness measure directly from the data, and is applicable to a general class of classification problems without any need for pretraining of the active learner on related tasks. The method is based on reinforcement learning and combines episodic policy search and a contextual bandits approach which are used to train the active learner in conjunction with training of the model. We demonstrate on several real datasets that this method learns to select training samples more efficiently than existing state-of-the-art methods.
Low-bit Quantization of Neural Networks for Efficient Inference
Mar 25, 2019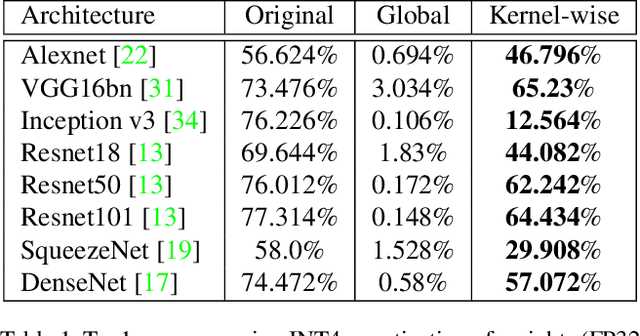
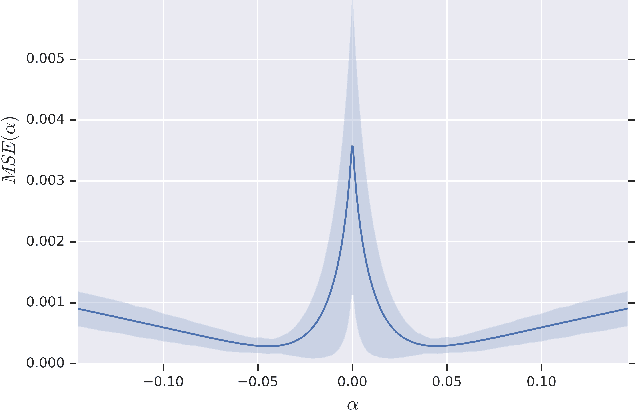
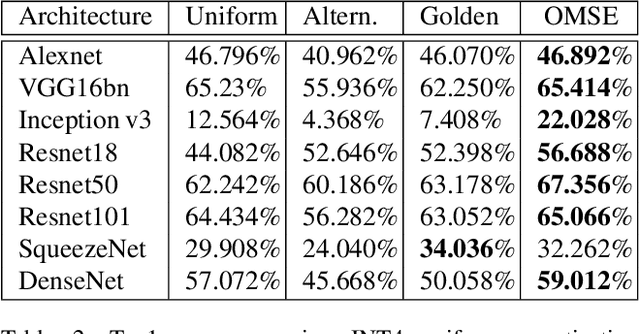
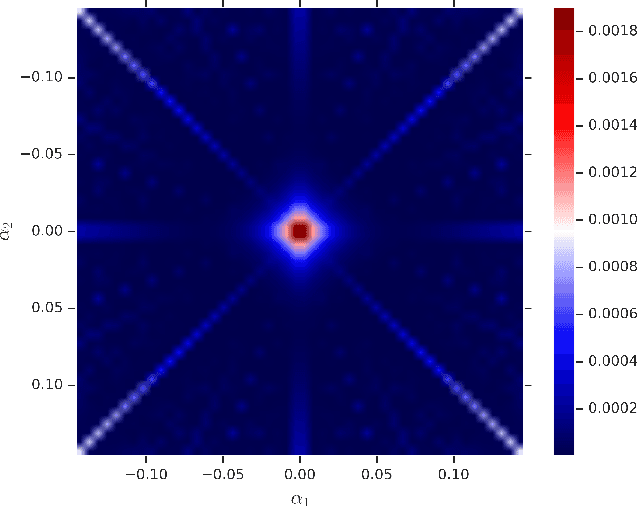
Recent machine learning methods use increasingly large deep neural networks to achieve state of the art results in various tasks. The gains in performance come at the cost of a substantial increase in computation and storage requirements. This makes real-time implementations on limited resources hardware a challenging task. One popular approach to address this challenge is to perform low-bit precision computations via neural network quantization. However, aggressive quantization generally entails a severe penalty in terms of accuracy, and often requires retraining of the network, or resorting to higher bit precision quantization. In this paper, we formalize the linear quantization task as a Minimum Mean Squared Error (MMSE) problem for both weights and activations, allowing low-bit precision inference without the need for full network retraining. The main contributions of our approach are the optimizations of the constrained MSE problem at each layer of the network, the hardware aware partitioning of the network parameters, and the use of multiple low precision quantized tensors for poorly approximated layers. The proposed approach allows 4 bits integer (INT4) quantization for deployment of pretrained models on limited hardware resources. Multiple experiments on various network architectures show that the suggested method yields state of the art results with minimal loss of tasks accuracy.