 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering by the local intrinsic dimension: the hidden structure of real-world data
Feb 27, 2019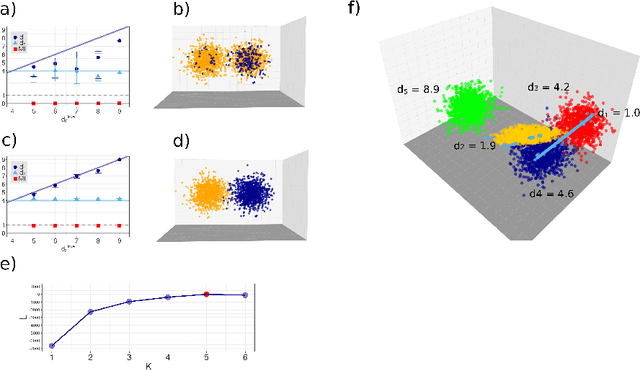
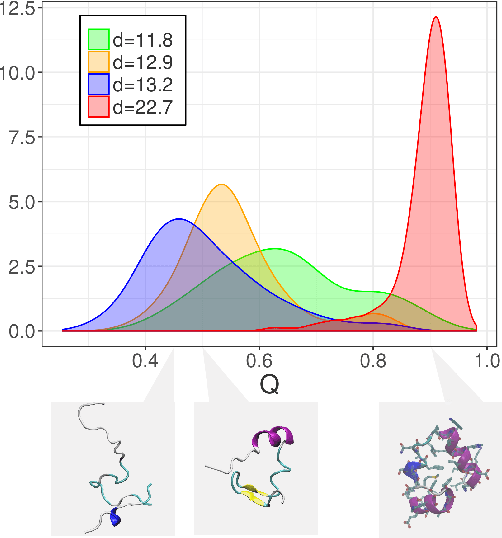
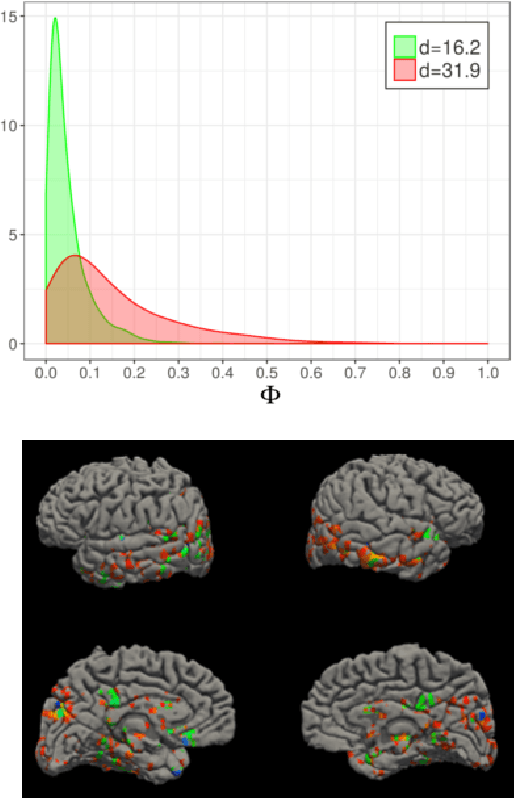
It is well known that a small number of variables is often sufficient to effectively describe high-dimensional data. This number is called the intrinsic dimension (ID) of the data. What is not so commonly known is that the ID can vary within the same dataset. This fact has been highlighted in technical discussions, but seldom exploited to gain practical insight in the data structure. Here we develop a simple and robust approach to cluster regions with the same local ID in a given data landscape. Surprisingly, we find that many real-world data sets contain regions with widely heterogeneous dimensions. These regions host points differing in core properties: folded vs unfolded configurations in a protein molecular dynamics trajectory, active vs non-active regions in brain imaging data, and firms with different financial risk in company balance sheets. Our results show that a simple topological feature, the local ID, is sufficient to uncover a rich structure in high-dimensional data landscapes.
Estimating the intrinsic dimension of datasets by a minimal neighborhood information
Mar 19, 2018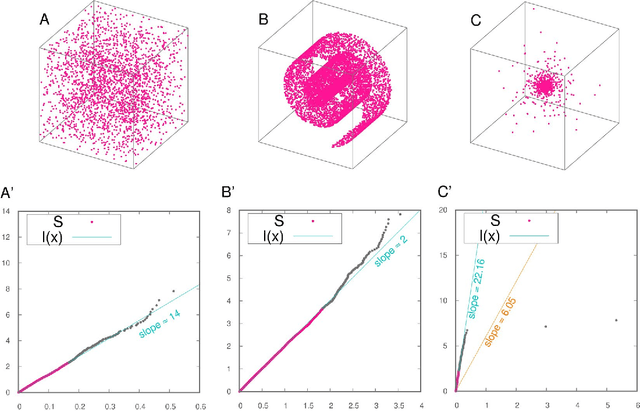
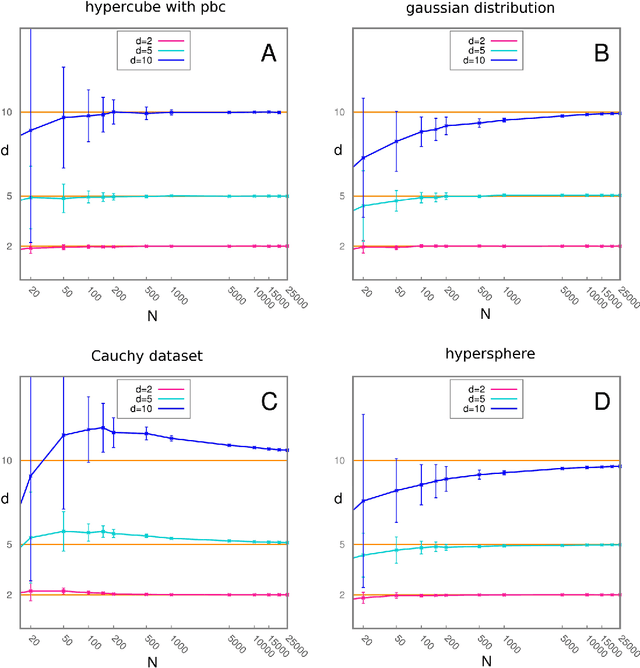
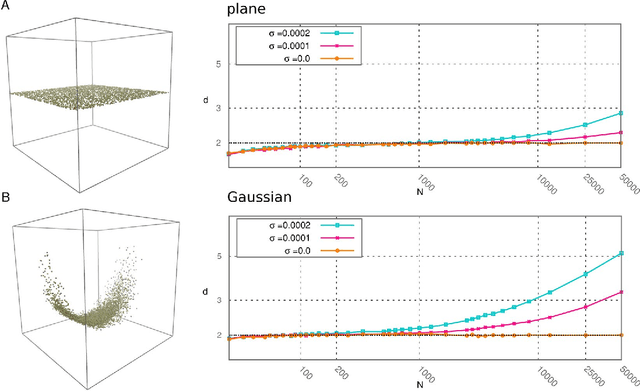
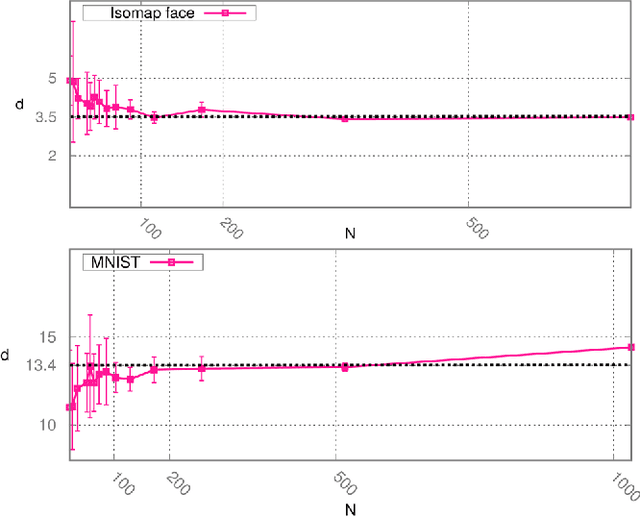
Analyzing large volumes of high-dimensional data is an issue of fundamental importance in data science, molecular simulations and beyond. Several approaches work on the assumption that the important content of a dataset belongs to a manifold whose Intrinsic Dimension (ID) is much lower than the crude large number of coordinates. Such manifold is generally twisted and curved, in addition points on it will be non-uniformly distributed: two factors that make the identification of the ID and its exploitation really hard. Here we propose a new ID estimator using only the distance of the first and the second nearest neighbor of each point in the sample. This extreme minimality enables us to reduce the effects of curvature, of density variation, and the resulting computational cost. The ID estimator is theoretically exact in uniformly distributed datasets, and provides consistent measures in general. When used in combination with block analysis, it allows discriminating the relevant dimensions as a function of the block size. This allows estimating the ID even when the data lie on a manifold perturbed by a high-dimensional noise, a situation often encountered in real world data sets. We demonstrate the usefulness of the approach on molecular simulations and image analysis.
Automatic topography of high-dimensional data sets by non-parametric Density Peak clustering
Feb 28, 2018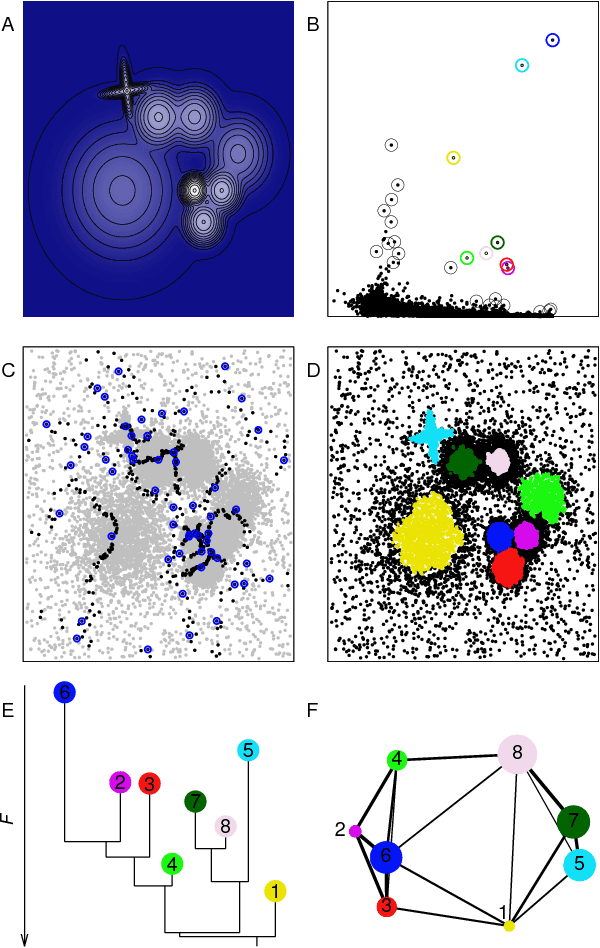
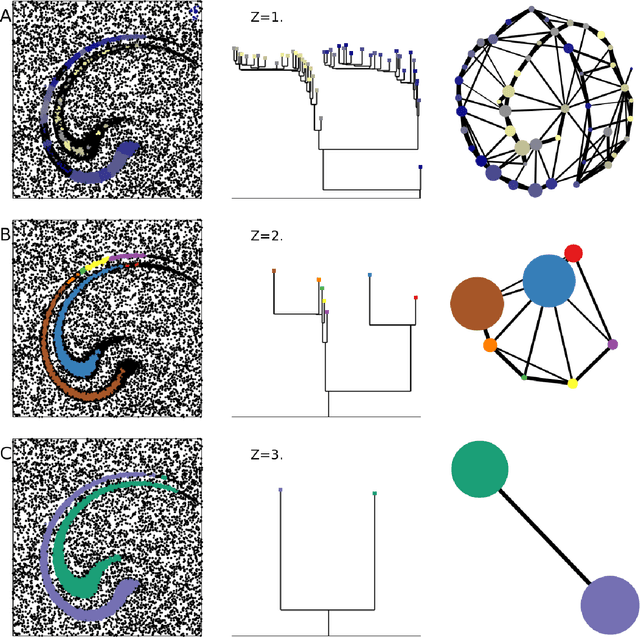
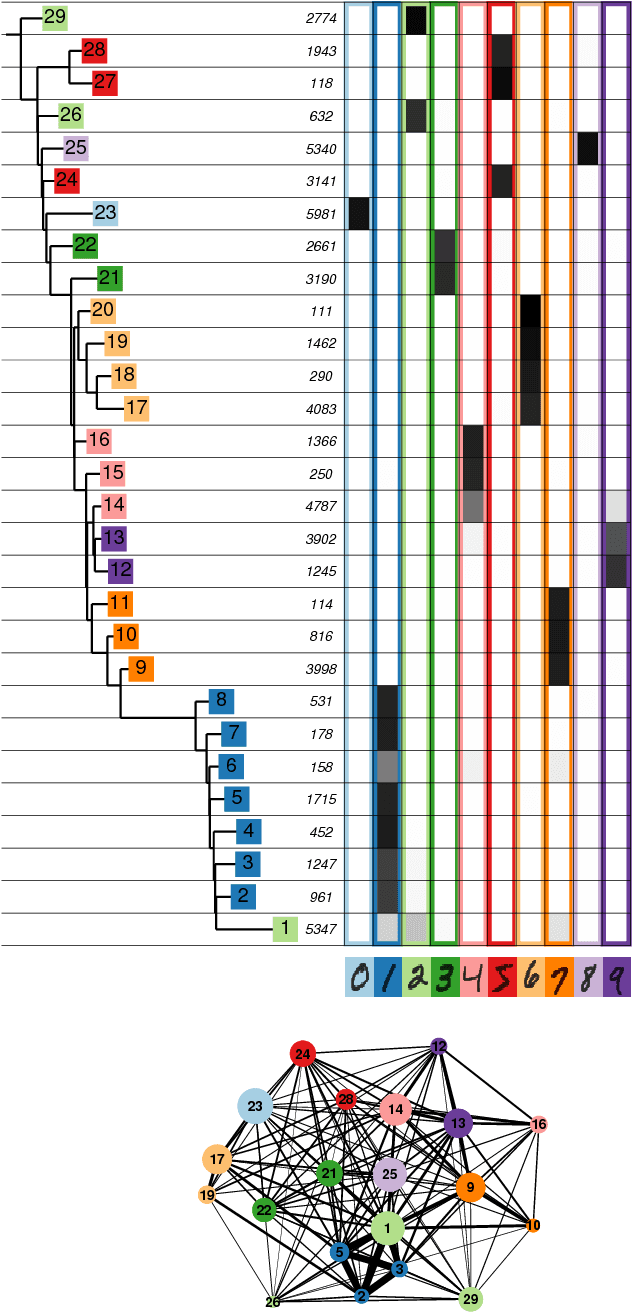
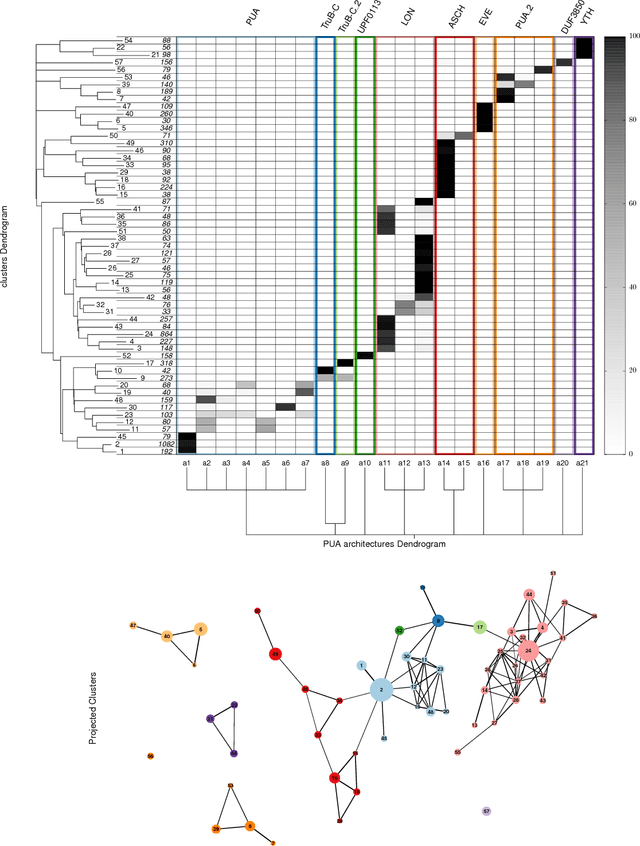
Data analysis in high-dimensional spaces aims at obtaining a synthetic description of a data set, revealing its main structure and its salient features. We here introduce an approach for charting data spaces, providing a topography of the probability distribution from which the data are harvested. This topography includes information on the number and the height of the probability peaks, the depth of the "valleys" separating them, the relative location of the peaks and their hierarchical organization. The topography is reconstructed by using an unsupervised variant of Density Peak clustering exploiting a non-parametric density estimator, which automatically measures the density in the manifold containing the data. Importantly, the density estimator provides an estimate of the error. This is a key feature, which allows distinguishing genuine probability peaks from density fluctuations due to finite sampling.