 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the intrinsic dimension of datasets by a minimal neighborhood information
Paper and Code
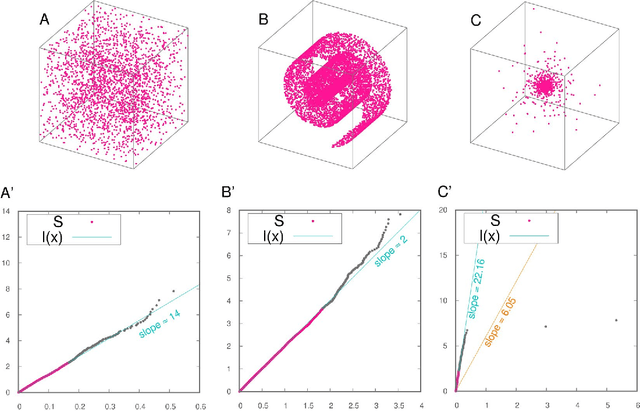
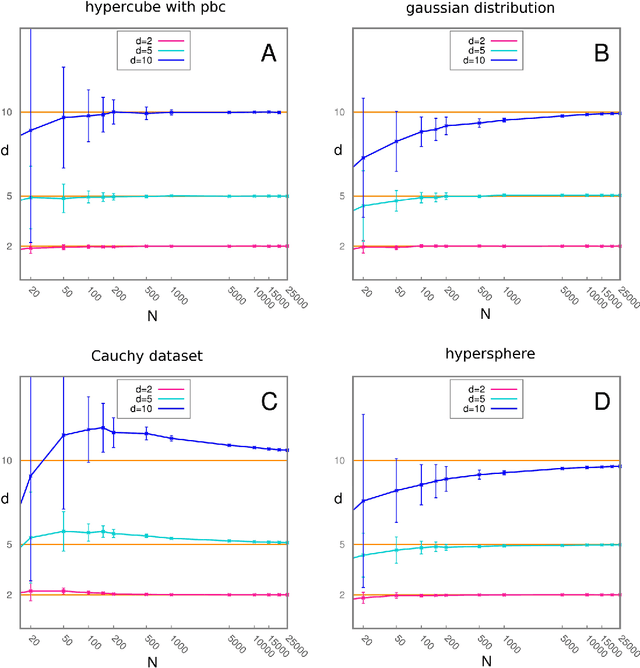
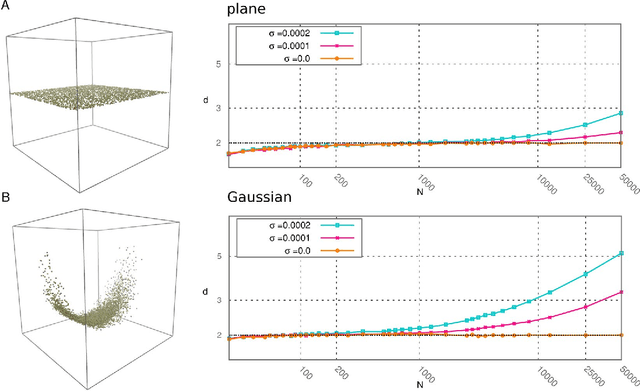
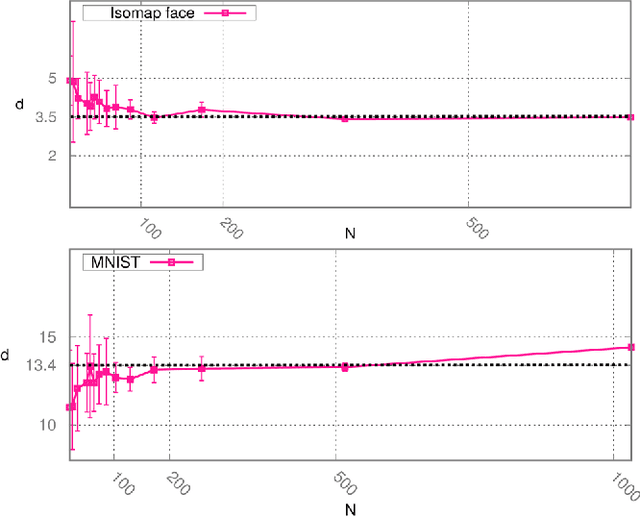
Analyzing large volumes of high-dimensional data is an issue of fundamental importance in data science, molecular simulations and beyond. Several approaches work on the assumption that the important content of a dataset belongs to a manifold whose Intrinsic Dimension (ID) is much lower than the crude large number of coordinates. Such manifold is generally twisted and curved, in addition points on it will be non-uniformly distributed: two factors that make the identification of the ID and its exploitation really hard. Here we propose a new ID estimator using only the distance of the first and the second nearest neighbor of each point in the sample. This extreme minimality enables us to reduce the effects of curvature, of density variation, and the resulting computational cost. The ID estimator is theoretically exact in uniformly distributed datasets, and provides consistent measures in general. When used in combination with block analysis, it allows discriminating the relevant dimensions as a function of the block size. This allows estimating the ID even when the data lie on a manifold perturbed by a high-dimensional noise, a situation often encountered in real world data sets. We demonstrate the usefulness of the approach on molecular simulations and image analysis.