 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorkspace Optimization: How to Train Your Agent
May 10, 2026Modern agents built on frontier language models often cannot adapt their weights. What, then, remains trainable? We argue it is the agent's \emph{workspace}, the structured external substrate it reads, writes, and tests; we call its evolution workspace optimization. Workspace optimization targets hard multi-turn environments where a frontier model has strong priors but cannot solve the task in a single shot, so the agent must learn through interaction. We propose a principled way to evolve the workspace, mirroring the structure of weight-space training: artifacts in place of parameters, evidence in place of data, counterexamples in place of losses, and textual feedback in place of gradients. We instantiate the idea in DreamTeam, a multi-agent harness for ARC-AGI-3 whose roles build an executable world model, plan, hypothesize, probe, strategize, and route failures. On the current 25-game ARC-AGI-3 public set under the official scoring protocol and averaged over two independent runs, DreamTeam improves the SOTA protocol-matched agent's score from 36% to 38.4%, while using 31% fewer environment actions per game.
Optimistic Gradient Learning with Hessian Corrections for High-Dimensional Black-Box Optimization
Feb 07, 2025



Black-box algorithms are designed to optimize functions without relying on their underlying analytical structure or gradient information, making them essential when gradients are inaccessible or difficult to compute. Traditional methods for solving black-box optimization (BBO) problems predominantly rely on non-parametric models and struggle to scale to large input spaces. Conversely, parametric methods that model the function with neural estimators and obtain gradient signals via backpropagation may suffer from significant gradient errors. A recent alternative, Explicit Gradient Learning (EGL), which directly learns the gradient using a first-order Taylor approximation, has demonstrated superior performance over both parametric and non-parametric methods. In this work, we propose two novel gradient learning variants to address the robustness challenges posed by high-dimensional, complex, and highly non-linear problems. Optimistic Gradient Learning (OGL) introduces a bias toward lower regions in the function landscape, while Higher-order Gradient Learning (HGL) incorporates second-order Taylor corrections to improve gradient accuracy. We combine these approaches into the unified OHGL algorithm, achieving state-of-the-art (SOTA) performance on the synthetic COCO suite. Additionally, we demonstrate OHGLs applicability to high-dimensional real-world machine learning (ML) tasks such as adversarial training and code generation. Our results highlight OHGLs ability to generate stronger candidates, offering a valuable tool for ML researchers and practitioners tackling high-dimensional, non-linear optimization challenges
A Coupled Flow Approach to Imitation Learning
Apr 29, 2023In reinforcement learning and imitation learning, an object of central importance is the state distribution induced by the policy. It plays a crucial role in the policy gradient theorem, and references to it--along with the related state-action distribution--can be found all across the literature. Despite its importance, the state distribution is mostly discussed indirectly and theoretically, rather than being modeled explicitly. The reason being an absence of appropriate density estimation tools. In this work, we investigate applications of a normalizing flow-based model for the aforementioned distributions. In particular, we use a pair of flows coupled through the optimality point of the Donsker-Varadhan representation of the Kullback-Leibler (KL) divergence, for distribution matching based imitation learning. Our algorithm, Coupled Flow Imitation Learning (CFIL), achieves state-of-the-art performance on benchmark tasks with a single expert trajectory and extends naturally to a variety of other settings, including the subsampled and state-only regimes.
Recomposing the Reinforcement Learning Building Blocks with Hypernetworks
Jun 12, 2021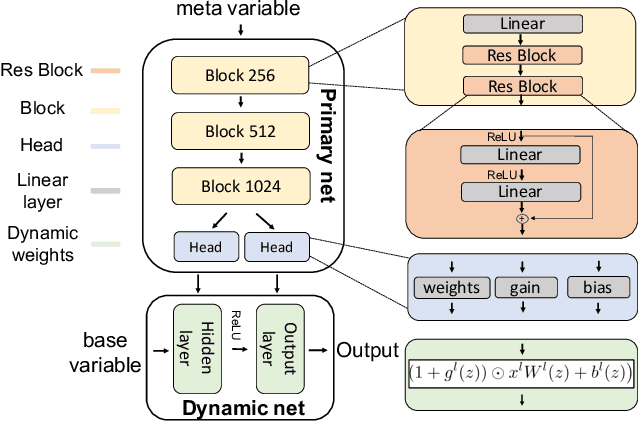
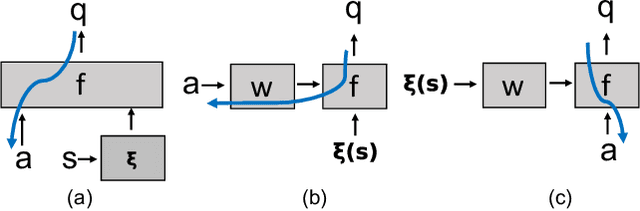

The Reinforcement Learning (RL) building blocks, i.e. Q-functions and policy networks, usually take elements from the cartesian product of two domains as input. In particular, the input of the Q-function is both the state and the action, and in multi-task problems (Meta-RL) the policy can take a state and a context. Standard architectures tend to ignore these variables' underlying interpretations and simply concatenate their features into a single vector. In this work, we argue that this choice may lead to poor gradient estimation in actor-critic algorithms and high variance learning steps in Meta-RL algorithms. To consider the interaction between the input variables, we suggest using a Hypernetwork architecture where a primary network determines the weights of a conditional dynamic network. We show that this approach improves the gradient approximation and reduces the learning step variance, which both accelerates learning and improves the final performance. We demonstrate a consistent improvement across different locomotion tasks and different algorithms both in RL (TD3 and SAC) and in Meta-RL (MAML and PEARL).
Explicit Gradient Learning
Jun 09, 2020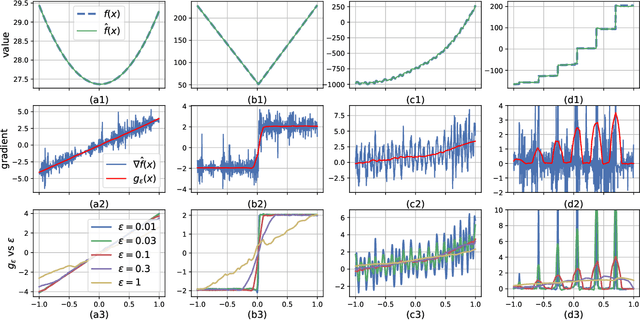
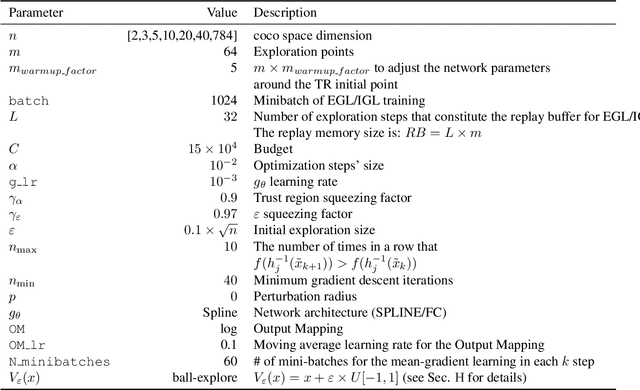
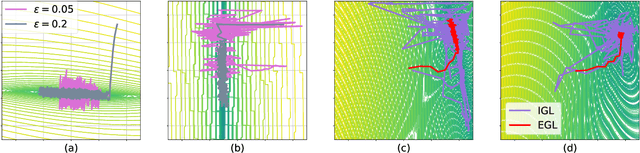

Black-Box Optimization (BBO) methods can find optimal policies for systems that interact with complex environments with no analytical representation. As such, they are of interest in many Artificial Intelligence (AI) domains. Yet classical BBO methods fall short in high-dimensional non-convex problems. They are thus often overlooked in real-world AI tasks. Here we present a BBO method, termed Explicit Gradient Learning (EGL), that is designed to optimize high-dimensional ill-behaved functions. We derive EGL by finding weak-spots in methods that fit the objective function with a parametric Neural Network (NN) model and obtain the gradient signal by calculating the parametric gradient. Instead of fitting the function, EGL trains a NN to estimate the objective gradient directly. We prove the convergence of EGL in convex optimization and its robustness in the optimization of integrable functions. We evaluate EGL and achieve state-of-the-art results in two challenging problems: (1) the COCO test suite against an assortment of standard BBO methods; and (2) in a high-dimensional non-convex image generation task.
Safe Policy Learning from Observations
Sep 28, 2018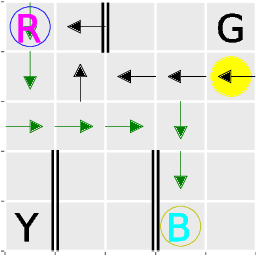
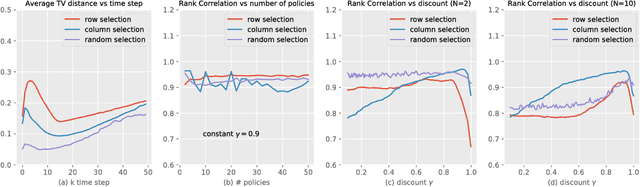
In this paper, we consider the problem of learning a policy by observing numerous non-expert agents. Our goal is to extract a policy that, with high-confidence, acts better than the agents' average performance. Such a setting is important for real-world problems where expert data is scarce but non-expert data can easily be obtained, e.g. by crowdsourcing. Our approach is to pose this problem as safe policy improvement in reinforcement learning. First, we evaluate an average behavior policy and approximate its value function. Then, we develop a stochastic policy improvement algorithm that safely improves the average behavior. The primary advantages of our approach, termed Rerouted Behavior Improvement (RBI), over other safe learning methods are its stability in the presence of value estimation errors and the elimination of a policy search process. We demonstrate these advantages in the Taxi grid-world domain and in four games from the Atari learning environment.