 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Policy Learning from Observations
Paper and Code
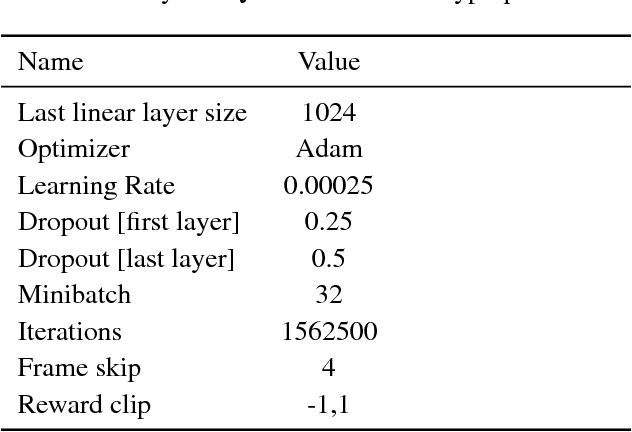
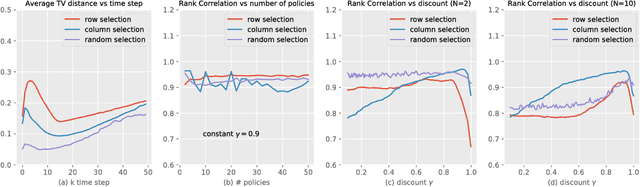
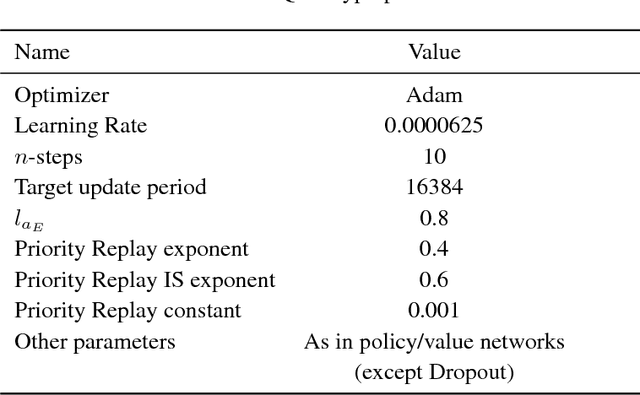
In this paper, we consider the problem of learning a policy by observing numerous non-expert agents. Our goal is to extract a policy that, with high-confidence, acts better than the agents' average performance. Such a setting is important for real-world problems where expert data is scarce but non-expert data can easily be obtained, e.g. by crowdsourcing. Our approach is to pose this problem as safe policy improvement in reinforcement learning. First, we evaluate an average behavior policy and approximate its value function. Then, we develop a stochastic policy improvement algorithm that safely improves the average behavior. The primary advantages of our approach, termed Rerouted Behavior Improvement (RBI), over other safe learning methods are its stability in the presence of value estimation errors and the elimination of a policy search process. We demonstrate these advantages in the Taxi grid-world domain and in four games from the Atari learning environment.