 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural network gradient-based learning of black-box function interfaces
Jan 13, 2019
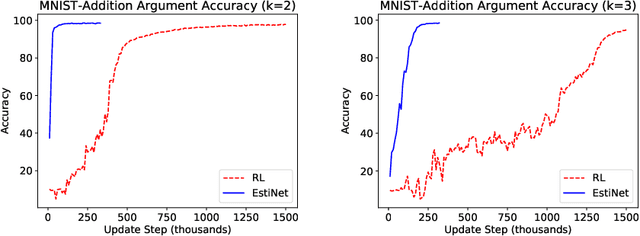

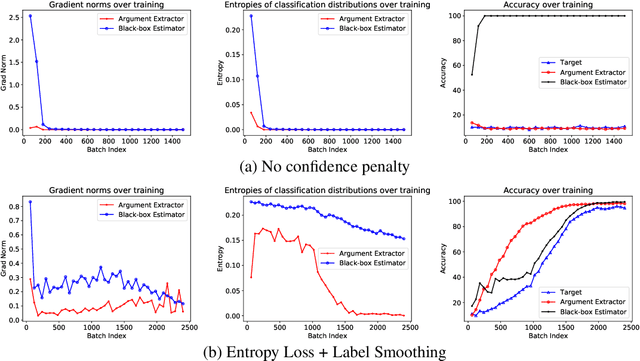
Deep neural networks work well at approximating complicated functions when provided with data and trained by gradient descent methods. At the same time, there is a vast amount of existing functions that programmatically solve different tasks in a precise manner eliminating the need for training. In many cases, it is possible to decompose a task to a series of functions, of which for some we may prefer to use a neural network to learn the functionality, while for others the preferred method would be to use existing black-box functions. We propose a method for end-to-end training of a base neural network that integrates calls to existing black-box functions. We do so by approximating the black-box functionality with a differentiable neural network in a way that drives the base network to comply with the black-box function interface during the end-to-end optimization process. At inference time, we replace the differentiable estimator with its external black-box non-differentiable counterpart such that the base network output matches the input arguments of the black-box function. Using this "Estimate and Replace" paradigm, we train a neural network, end to end, to compute the input to black-box functionality while eliminating the need for intermediate labels. We show that by leveraging the existing precise black-box function during inference, the integrated model generalizes better than a fully differentiable model, and learns more efficiently compared to RL-based methods.
Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks with Existing Applications
Apr 24, 2018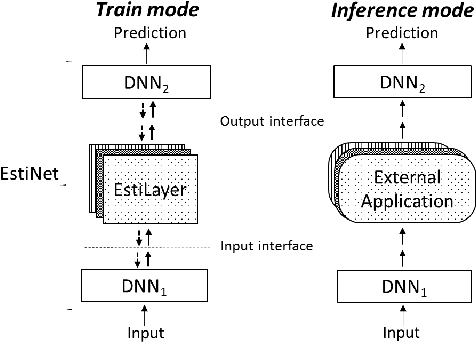
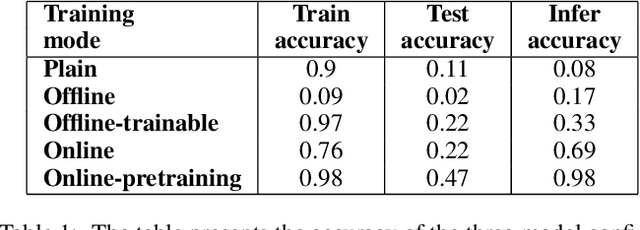
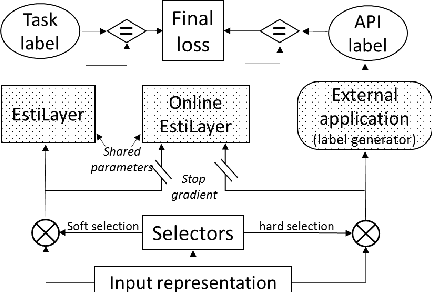
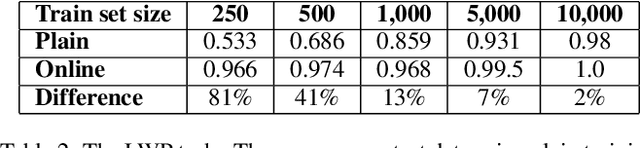
Existing applications include a huge amount of knowledge that is out of reach for deep neural networks. This paper presents a novel approach for integrating calls to existing applications into deep learning architectures. Using this approach, we estimate each application's functionality with an estimator, which is implemented as a deep neural network (DNN). The estimator is then embedded into a base network that we direct into complying with the application's interface during an end-to-end optimization process. At inference time, we replace each estimator with its existing application counterpart and let the base network solve the task by interacting with the existing application. Using this 'Estimate and Replace' method, we were able to train a DNN end-to-end with less data and outperformed a matching DNN that did not interact with the external application.
Fine-grained Analysis of Sentence Embeddings Using Auxiliary Prediction Tasks
Feb 09, 2017


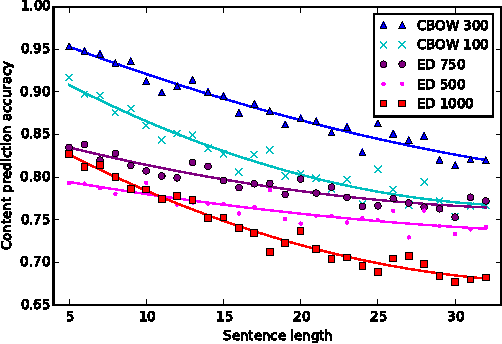
There is a lot of research interest in encoding variable length sentences into fixed length vectors, in a way that preserves the sentence meanings. Two common methods include representations based on averaging word vectors, and representations based on the hidden states of recurrent neural networks such as LSTMs. The sentence vectors are used as features for subsequent machine learning tasks or for pre-training in the context of deep learning. However, not much is known about the properties that are encoded in these sentence representations and about the language information they capture. We propose a framework that facilitates better understanding of the encoded representations. We define prediction tasks around isolated aspects of sentence structure (namely sentence length, word content, and word order), and score representations by the ability to train a classifier to solve each prediction task when using the representation as input. We demonstrate the potential contribution of the approach by analyzing different sentence representation mechanisms. The analysis sheds light on the relative strengths of different sentence embedding methods with respect to these low level prediction tasks, and on the effect of the encoded vector's dimensionality on the resulting representations.