 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence-Assisted Prostate Cancer Diagnosis for Reduced Use of Immunohistochemistry
Mar 31, 2025Prostate cancer diagnosis heavily relies on histopathological evaluation, which is subject to variability. While immunohistochemical staining (IHC) assists in distinguishing benign from malignant tissue, it involves increased work, higher costs, and diagnostic delays. Artificial intelligence (AI) presents a promising solution to reduce reliance on IHC by accurately classifying atypical glands and borderline morphologies in hematoxylin & eosin (H&E) stained tissue sections. In this study, we evaluated an AI model's ability to minimize IHC use without compromising diagnostic accuracy by retrospectively analyzing prostate core needle biopsies from routine diagnostics at three different pathology sites. These cohorts were composed exclusively of difficult cases where the diagnosing pathologists required IHC to finalize the diagnosis. The AI model demonstrated area under the curve values of 0.951-0.993 for detecting cancer in routine H&E-stained slides. Applying sensitivity-prioritized diagnostic thresholds reduced the need for IHC staining by 44.4%, 42.0%, and 20.7% in the three cohorts investigated, without a single false negative prediction. This AI model shows potential for optimizing IHC use, streamlining decision-making in prostate pathology, and alleviating resource burdens.
The impact of tissue detection on diagnostic artificial intelligence algorithms in digital pathology
Mar 29, 2025Tissue detection is a crucial first step in most digital pathology applications. Details of the segmentation algorithm are rarely reported, and there is a lack of studies investigating the downstream effects of a poor segmentation algorithm. Disregarding tissue detection quality could create a bottleneck for downstream performance and jeopardize patient safety if diagnostically relevant parts of the specimen are excluded from analysis in clinical applications. This study aims to determine whether performance of downstream tasks is sensitive to the tissue detection method, and to compare performance of classical and AI-based tissue detection. To this end, we trained an AI model for Gleason grading of prostate cancer in whole slide images (WSIs) using two different tissue detection algorithms: thresholding (classical) and UNet++ (AI). A total of 33,823 WSIs scanned on five digital pathology scanners were used to train the tissue detection AI model. The downstream Gleason grading algorithm was trained and tested using 70,524 WSIs from 13 clinical sites scanned on 13 different scanners. There was a decrease from 116 (0.43%) to 22 (0.08%) fully undetected tissue samples when switching from thresholding-based tissue detection to AI-based, suggesting an AI model may be more reliable than a classical model for avoiding total failures on slides with unusual appearance. On the slides where tissue could be detected by both algorithms, no significant difference in overall Gleason grading performance was observed. However, tissue detection dependent clinically significant variations in AI grading were observed in 3.5% of malignant slides, highlighting the importance of robust tissue detection for optimal clinical performance of diagnostic AI.
Foundation Models -- A Panacea for Artificial Intelligence in Pathology?
Feb 28, 2025
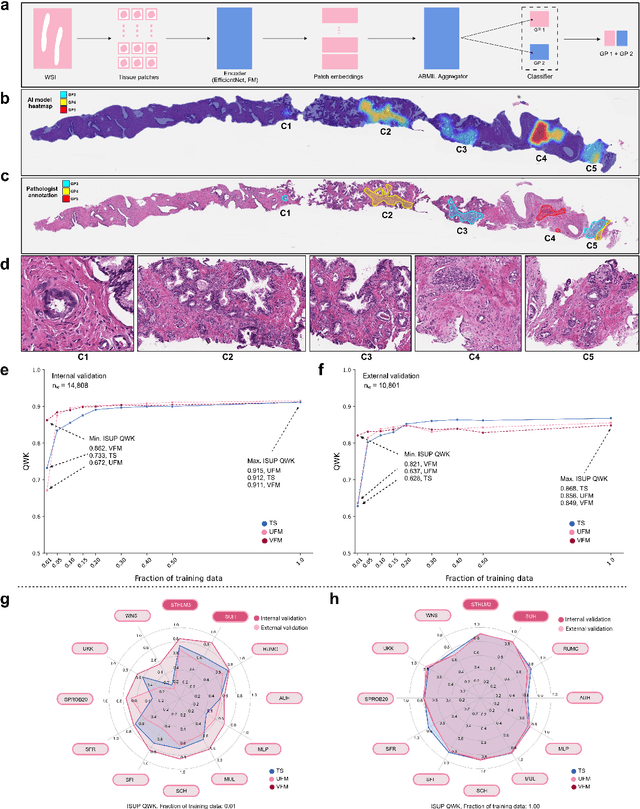

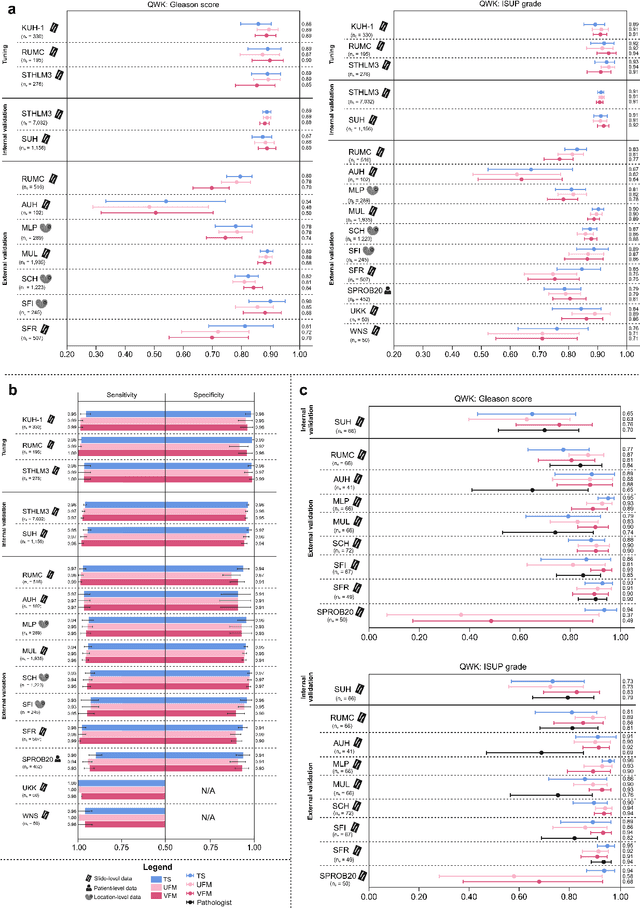
The role of artificial intelligence (AI) in pathology has evolved from aiding diagnostics to uncovering predictive morphological patterns in whole slide images (WSIs). Recently, foundation models (FMs) leveraging self-supervised pre-training have been widely advocated as a universal solution for diverse downstream tasks. However, open questions remain about their clinical applicability and generalization advantages over end-to-end learning using task-specific (TS) models. Here, we focused on AI with clinical-grade performance for prostate cancer diagnosis and Gleason grading. We present the largest validation of AI for this task, using over 100,000 core needle biopsies from 7,342 patients across 15 sites in 11 countries. We compared two FMs with a fully end-to-end TS model in a multiple instance learning framework. Our findings challenge assumptions that FMs universally outperform TS models. While FMs demonstrated utility in data-scarce scenarios, their performance converged with - and was in some cases surpassed by - TS models when sufficient labeled training data were available. Notably, extensive task-specific training markedly reduced clinically significant misgrading, misdiagnosis of challenging morphologies, and variability across different WSI scanners. Additionally, FMs used up to 35 times more energy than the TS model, raising concerns about their sustainability. Our results underscore that while FMs offer clear advantages for rapid prototyping and research, their role as a universal solution for clinically applicable medical AI remains uncertain. For high-stakes clinical applications, rigorous validation and consideration of task-specific training remain critically important. We advocate for integrating the strengths of FMs and end-to-end learning to achieve robust and resource-efficient AI pathology solutions fit for clinical use.