 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Learning-Based Sampling Optimization for Compressive Dynamic MRI
Feb 20, 2019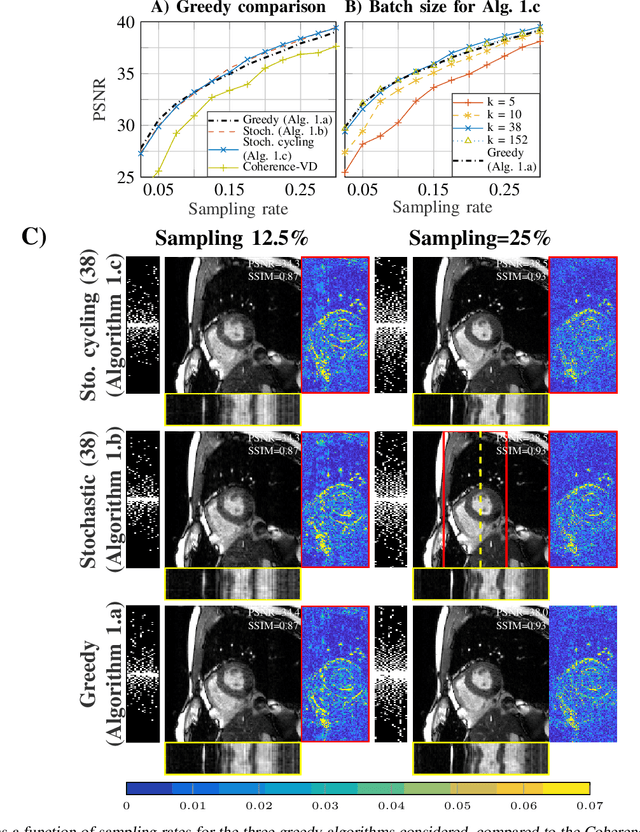
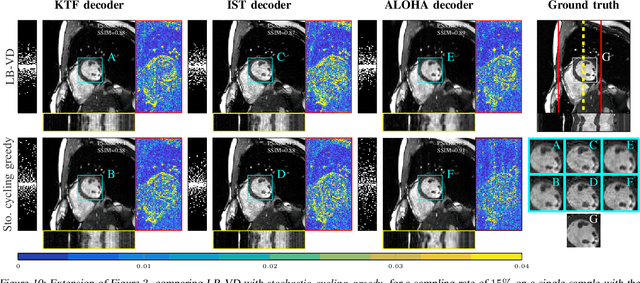
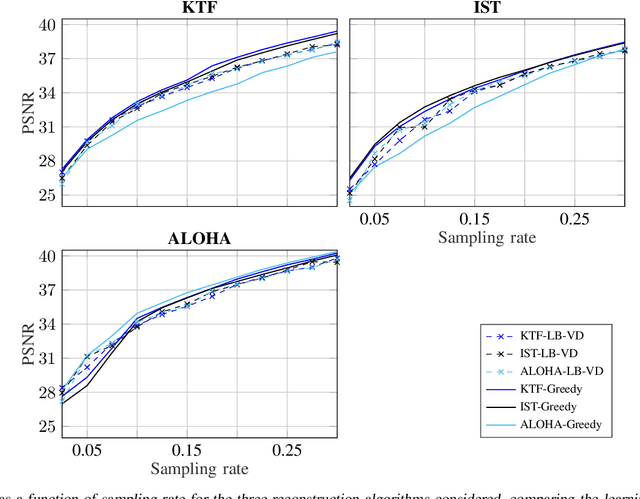

Slow acquisition has been one of the historical problems in dynamic magnetic resonance imaging (dMRI), but the rise of compressed sensing (CS) has brought numerous algorithms that successfully achieve high acceleration rates. While CS proposes random sampling for data acquisition, practical CS applications to dMRI have typically relied on random variable-density (VD) sampling patterns, where masks are drawn from probabilistic models, which preferably sample from the center of the Fourier domain. In contrast to this model-driven approach, we propose the first data-driven, scalable framework for optimizing sampling patterns in dMRI. Through a greedy algorithm, this approach allows the data to directly govern the search for a mask that exhibits good empirical performance. Previous greedy approach, designed for static MRI, required very intensive computations, prohibiting their direct application to dMRI, and we address this issue by resorting to a stochastic greedy algorithm that exploits only a fraction of resources compared to the previous approach without sacrificing the reconstruction accuracy. A thorough comparison on in vivo datasets shows the inefficiency of model-based approaches in terms of sampling performance and suggests that our data-driven sampling approach could fully enable the potential of CS applied to dMRI.
Learning-Based Compressive MRI
May 03, 2018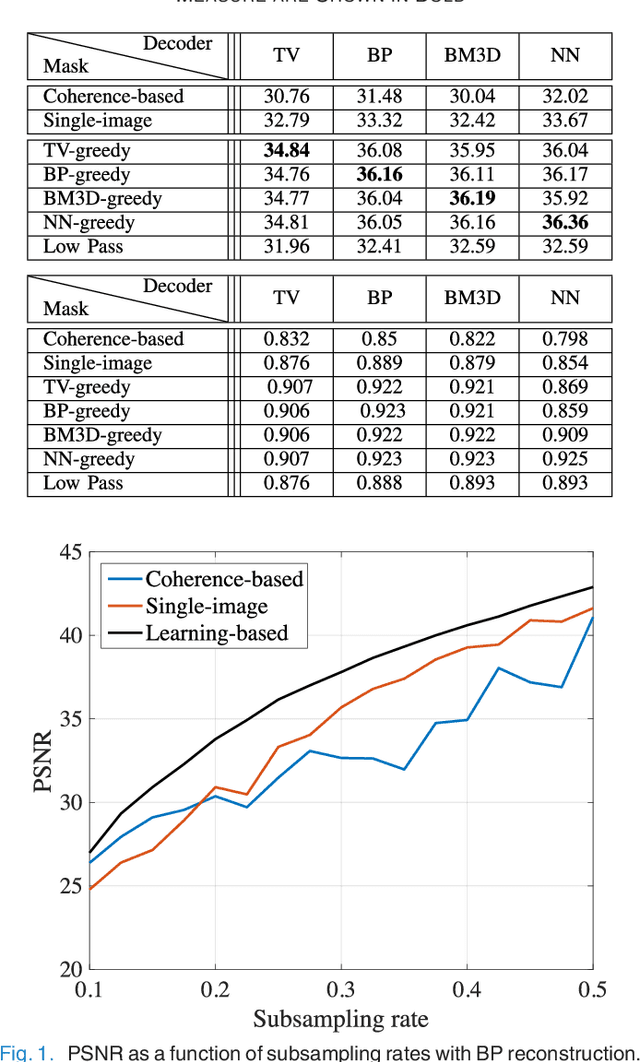

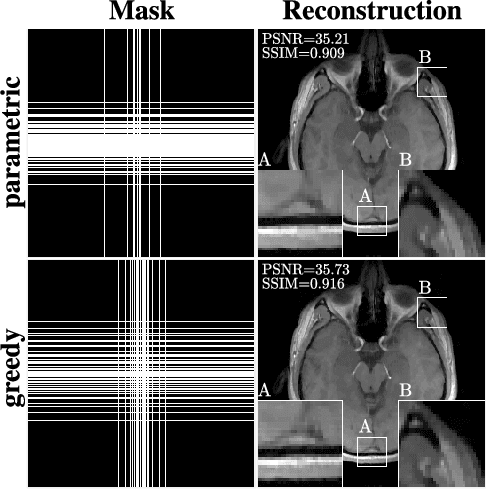
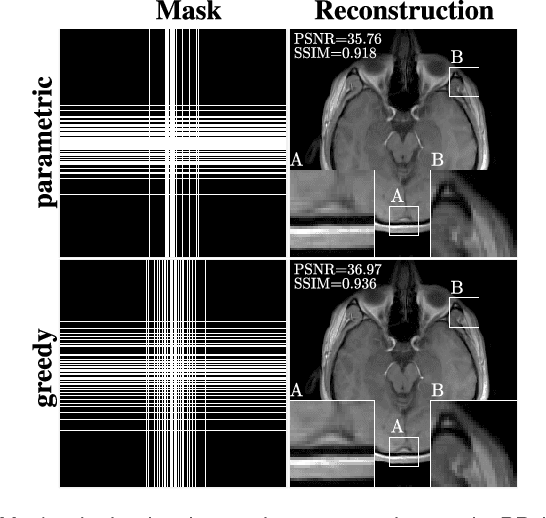
In the area of magnetic resonance imaging (MRI), an extensive range of non-linear reconstruction algorithms have been proposed that can be used with general Fourier subsampling patterns. However, the design of these subsampling patterns has typically been considered in isolation from the reconstruction rule and the anatomy under consideration. In this paper, we propose a learning-based framework for optimizing MRI subsampling patterns for a specific reconstruction rule and anatomy, considering both the noiseless and noisy settings. Our learning algorithm has access to a representative set of training signals, and searches for a sampling pattern that performs well on average for the signals in this set. We present a novel parameter-free greedy mask selection method, and show it to be effective for a variety of reconstruction rules and performance metrics. Moreover we also support our numerical findings by providing a rigorous justification of our framework via statistical learning theory.