 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Transformer for 3D Point Cloud Automatic Annotation
Mar 27, 20233D automatic annotation has received increased attention since manually annotating 3D point clouds is laborious. However, existing methods are usually complicated, e.g., pipelined training for 3D foreground/background segmentation, cylindrical object proposals, and point completion. Furthermore, they often overlook the inter-object feature relation that is particularly informative to hard samples for 3D annotation. To this end, we propose a simple yet effective end-to-end Context-Aware Transformer (CAT) as an automated 3D-box labeler to generate precise 3D box annotations from 2D boxes, trained with a small number of human annotations. We adopt the general encoder-decoder architecture, where the CAT encoder consists of an intra-object encoder (local) and an inter-object encoder (global), performing self-attention along the sequence and batch dimensions, respectively. The former models intra-object interactions among points, and the latter extracts feature relations among different objects, thus boosting scene-level understanding. Via local and global encoders, CAT can generate high-quality 3D box annotations with a streamlined workflow, allowing it to outperform existing state-of-the-art by up to 1.79% 3D AP on the hard task of the KITTI test set.
Multimodal Transformer for Automatic 3D Annotation and Object Detection
Jul 20, 2022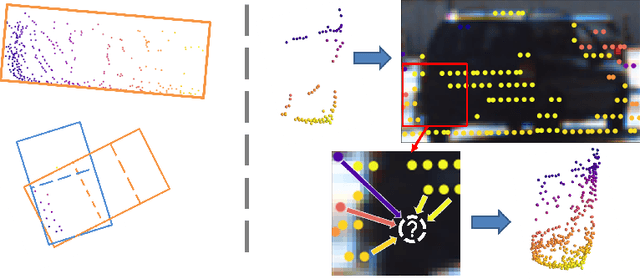
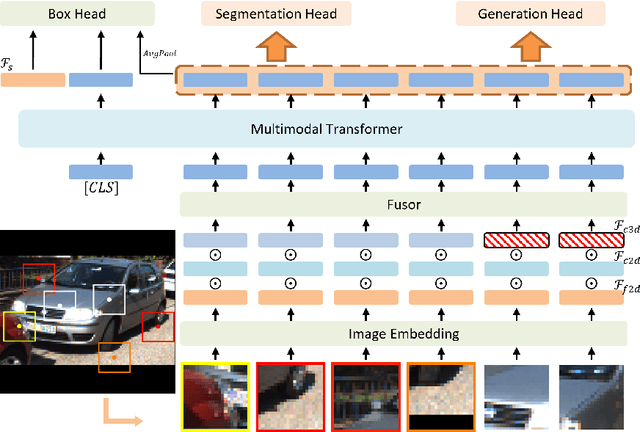
Despite a growing number of datasets being collected for training 3D object detection models, significant human effort is still required to annotate 3D boxes on LiDAR scans. To automate the annotation and facilitate the production of various customized datasets, we propose an end-to-end multimodal transformer (MTrans) autolabeler, which leverages both LiDAR scans and images to generate precise 3D box annotations from weak 2D bounding boxes. To alleviate the pervasive sparsity problem that hinders existing autolabelers, MTrans densifies the sparse point clouds by generating new 3D points based on 2D image information. With a multi-task design, MTrans segments the foreground/background, densifies LiDAR point clouds, and regresses 3D boxes simultaneously. Experimental results verify the effectiveness of the MTrans for improving the quality of the generated labels. By enriching the sparse point clouds, our method achieves 4.48\% and 4.03\% better 3D AP on KITTI moderate and hard samples, respectively, versus the state-of-the-art autolabeler. MTrans can also be extended to improve the accuracy for 3D object detection, resulting in a remarkable 89.45\% AP on KITTI hard samples. Codes are at \url{https://github.com/Cliu2/MTrans}.
AET-EFN: A Versatile Design for Static and Dynamic Event-Based Vision
Mar 22, 2021



The neuromorphic event cameras, which capture the optical changes of a scene, have drawn increasing attention due to their high speed and low power consumption. However, the event data are noisy, sparse, and nonuniform in the spatial-temporal domain with an extremely high temporal resolution, making it challenging to design backend algorithms for event-based vision. Existing methods encode events into point-cloud-based or voxel-based representations, but suffer from noise and/or information loss. Additionally, there is little research that systematically studies how to handle static and dynamic scenes with one universal design for event-based vision. This work proposes the Aligned Event Tensor (AET) as a novel event data representation, and a neat framework called Event Frame Net (EFN), which enables our model for event-based vision under static and dynamic scenes. The proposed AET and EFN are evaluated on various datasets, and proved to surpass existing state-of-the-art methods by large margins. Our method is also efficient and achieves the fastest inference speed among others.