 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot the Silver Bullet: LLM-enhanced Programming Error Messages are Ineffective in Practice
Sep 27, 2024The sudden emergence of large language models (LLMs) such as ChatGPT has had a disruptive impact throughout the computing education community. LLMs have been shown to excel at producing correct code to CS1 and CS2 problems, and can even act as friendly assistants to students learning how to code. Recent work shows that LLMs demonstrate unequivocally superior results in being able to explain and resolve compiler error messages -- for decades, one of the most frustrating parts of learning how to code. However, LLM-generated error message explanations have only been assessed by expert programmers in artificial conditions. This work sought to understand how novice programmers resolve programming error messages (PEMs) in a more realistic scenario. We ran a within-subjects study with $n$ = 106 participants in which students were tasked to fix six buggy C programs. For each program, participants were randomly assigned to fix the problem using either a stock compiler error message, an expert-handwritten error message, or an error message explanation generated by GPT-4. Despite promising evidence on synthetic benchmarks, we found that GPT-4 generated error messages outperformed conventional compiler error messages in only 1 of the 6 tasks, measured by students' time-to-fix each problem. Handwritten explanations still outperform LLM and conventional error messages, both on objective and subjective measures.
Computing Education in the Era of Generative AI
Jun 05, 2023



The computing education community has a rich history of pedagogical innovation designed to support students in introductory courses, and to support teachers in facilitating student learning. Very recent advances in artificial intelligence have resulted in code generation models that can produce source code from natural language problem descriptions -- with impressive accuracy in many cases. The wide availability of these models and their ease of use has raised concerns about potential impacts on many aspects of society, including the future of computing education. In this paper, we discuss the challenges and opportunities such models present to computing educators, with a focus on introductory programming classrooms. We summarize the results of two recent articles, the first evaluating the performance of code generation models on typical introductory-level programming problems, and the second exploring the quality and novelty of learning resources generated by these models. We consider likely impacts of such models upon pedagogical practice in the context of the most recent advances at the time of writing.
"It's Weird That it Knows What I Want": Usability and Interactions with Copilot for Novice Programmers
Apr 05, 2023


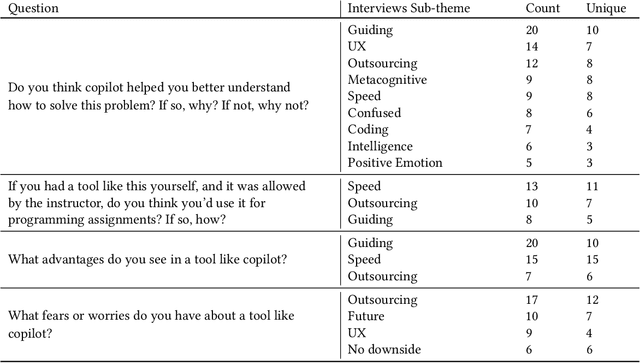
Recent developments in deep learning have resulted in code-generation models that produce source code from natural language and code-based prompts with high accuracy. This is likely to have profound effects in the classroom, where novices learning to code can now use free tools to automatically suggest solutions to programming exercises and assignments. However, little is currently known about how novices interact with these tools in practice. We present the first study that observes students at the introductory level using one such code auto-generating tool, Github Copilot, on a typical introductory programming (CS1) assignment. Through observations and interviews we explore student perceptions of the benefits and pitfalls of this technology for learning, present new observed interaction patterns, and discuss cognitive and metacognitive difficulties faced by students. We consider design implications of these findings, specifically in terms of how tools like Copilot can better support and scaffold the novice programming experience.
Programming Is Hard -- Or at Least It Used to Be: Educational Opportunities And Challenges of AI Code Generation
Dec 02, 2022The introductory programming sequence has been the focus of much research in computing education. The recent advent of several viable and freely-available AI-driven code generation tools present several immediate opportunities and challenges in this domain. In this position paper we argue that the community needs to act quickly in deciding what possible opportunities can and should be leveraged and how, while also working on how to overcome or otherwise mitigate the possible challenges. Assuming that the effectiveness and proliferation of these tools will continue to progress rapidly, without quick, deliberate, and concerted efforts, educators will lose advantage in helping shape what opportunities come to be, and what challenges will endure. With this paper we aim to seed this discussion within the computing education community.