 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Educational Recommendation Engine (NERE)
Sep 21, 2018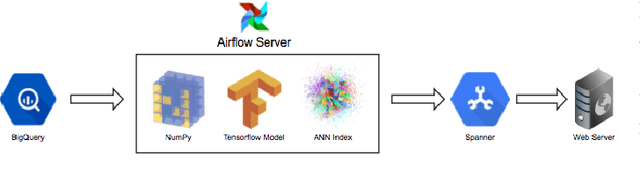
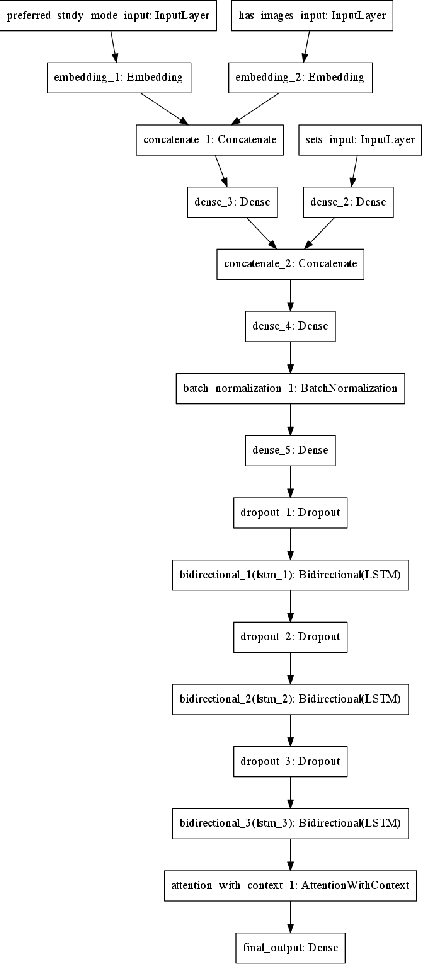
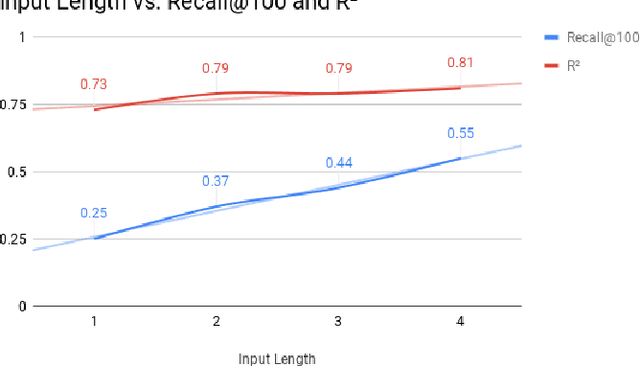

Quizlet is the most popular online learning tool in the United States, and is used by over 2/3 of high school students, and 1/2 of college students. With more than 95% of Quizlet users reporting improved grades as a result, the platform has become the de-facto tool used in millions of classrooms. In this paper, we explore the task of recommending suitable content for a student to study, given their prior interests, as well as what their peers are studying. We propose a novel approach, i.e. Neural Educational Recommendation Engine (NERE), to recommend educational content by leveraging student behaviors rather than ratings. We have found that this approach better captures social factors that are more aligned with learning. NERE is based on a recurrent neural network that includes collaborative and content-based approaches for recommendation, and takes into account any particular student's speed, mastery, and experience to recommend the appropriate task. We train NERE by jointly learning the user embeddings and content embeddings, and attempt to predict the content embedding for the final timestamp. We also develop a confidence estimator for our neural network, which is a crucial requirement for productionizing this model. We apply NERE to Quizlet's proprietary dataset, and present our results. We achieved an R^2 score of 0.81 in the content embedding space, and a recall score of 54% on our 100 nearest neighbors. This vastly exceeds the recall@100 score of 12% that a standard matrix-factorization approach provides. We conclude with a discussion on how NERE will be deployed, and position our work as one of the first educational recommender systems for the K-12 space.
Pixels to Voxels: Modeling Visual Representation in the Human Brain
Jul 18, 2014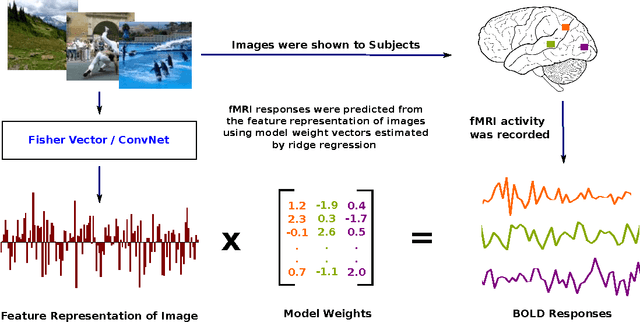

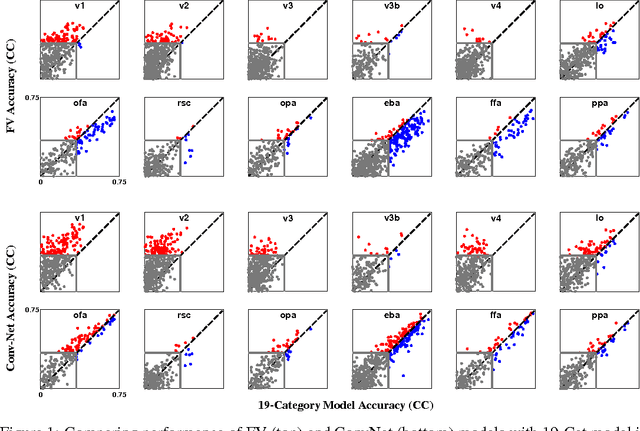
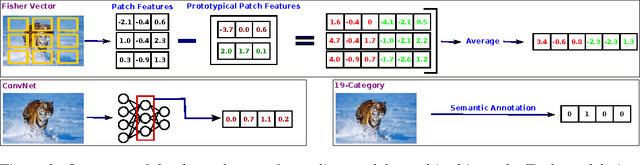
The human brain is adept at solving difficult high-level visual processing problems such as image interpretation and object recognition in natural scenes. Over the past few years neuroscientists have made remarkable progress in understanding how the human brain represents categories of objects and actions in natural scenes. However, all current models of high-level human vision operate on hand annotated images in which the objects and actions have been assigned semantic tags by a human operator. No current models can account for high-level visual function directly in terms of low-level visual input (i.e., pixels). To overcome this fundamental limitation we sought to develop a new class of models that can predict human brain activity directly from low-level visual input (i.e., pixels). We explored two classes of models drawn from computer vision and machine learning. The first class of models was based on Fisher Vectors (FV) and the second was based on Convolutional Neural Networks (ConvNets). We find that both classes of models accurately predict brain activity in high-level visual areas, directly from pixels and without the need for any semantic tags or hand annotation of images. This is the first time that such a mapping has been obtained. The fit models provide a new platform for exploring the functional principles of human vision, and they show that modern methods of computer vision and machine learning provide important tools for characterizing brain function.