 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels to Voxels: Modeling Visual Representation in the Human Brain
Paper and Code
Jul 18, 2014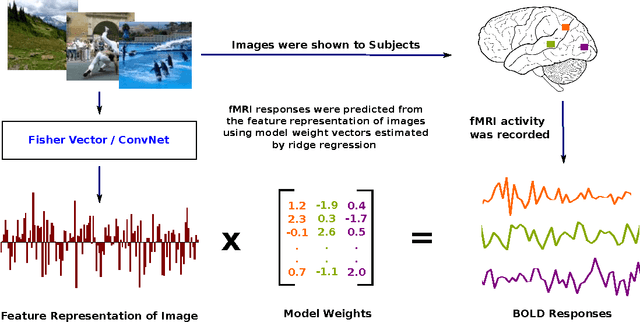

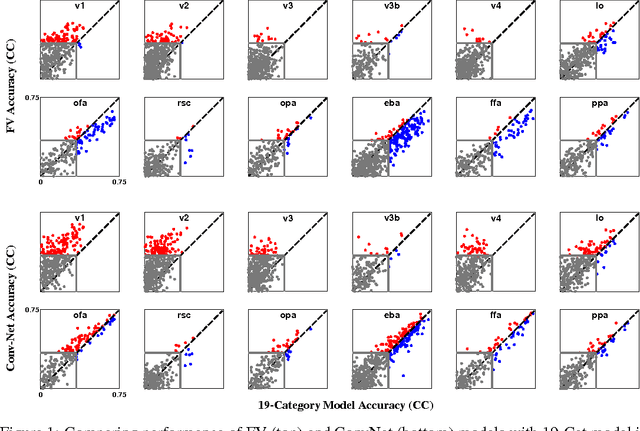
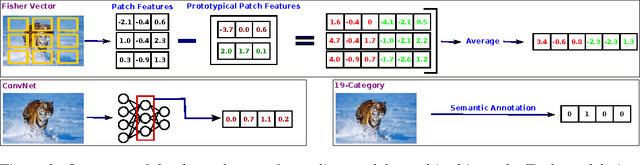
The human brain is adept at solving difficult high-level visual processing problems such as image interpretation and object recognition in natural scenes. Over the past few years neuroscientists have made remarkable progress in understanding how the human brain represents categories of objects and actions in natural scenes. However, all current models of high-level human vision operate on hand annotated images in which the objects and actions have been assigned semantic tags by a human operator. No current models can account for high-level visual function directly in terms of low-level visual input (i.e., pixels). To overcome this fundamental limitation we sought to develop a new class of models that can predict human brain activity directly from low-level visual input (i.e., pixels). We explored two classes of models drawn from computer vision and machine learning. The first class of models was based on Fisher Vectors (FV) and the second was based on Convolutional Neural Networks (ConvNets). We find that both classes of models accurately predict brain activity in high-level visual areas, directly from pixels and without the need for any semantic tags or hand annotation of images. This is the first time that such a mapping has been obtained. The fit models provide a new platform for exploring the functional principles of human vision, and they show that modern methods of computer vision and machine learning provide important tools for characterizing brain function.