 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Educational Recommendation Engine (NERE)
Sep 21, 2018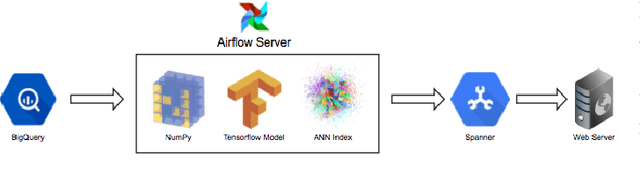
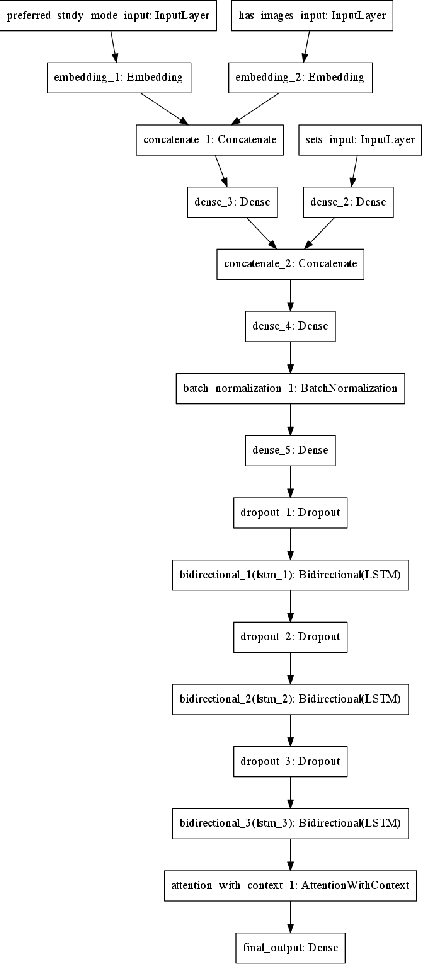
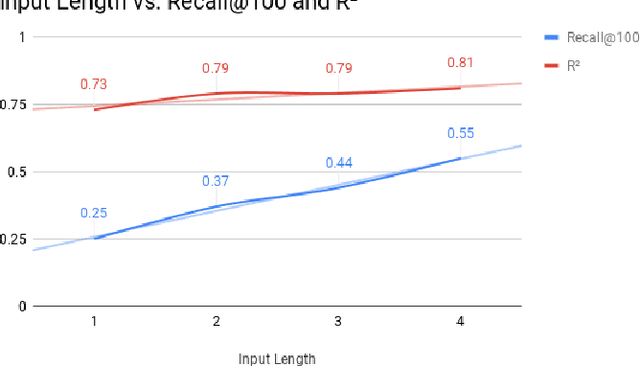

Quizlet is the most popular online learning tool in the United States, and is used by over 2/3 of high school students, and 1/2 of college students. With more than 95% of Quizlet users reporting improved grades as a result, the platform has become the de-facto tool used in millions of classrooms. In this paper, we explore the task of recommending suitable content for a student to study, given their prior interests, as well as what their peers are studying. We propose a novel approach, i.e. Neural Educational Recommendation Engine (NERE), to recommend educational content by leveraging student behaviors rather than ratings. We have found that this approach better captures social factors that are more aligned with learning. NERE is based on a recurrent neural network that includes collaborative and content-based approaches for recommendation, and takes into account any particular student's speed, mastery, and experience to recommend the appropriate task. We train NERE by jointly learning the user embeddings and content embeddings, and attempt to predict the content embedding for the final timestamp. We also develop a confidence estimator for our neural network, which is a crucial requirement for productionizing this model. We apply NERE to Quizlet's proprietary dataset, and present our results. We achieved an R^2 score of 0.81 in the content embedding space, and a recall score of 54% on our 100 nearest neighbors. This vastly exceeds the recall@100 score of 12% that a standard matrix-factorization approach provides. We conclude with a discussion on how NERE will be deployed, and position our work as one of the first educational recommender systems for the K-12 space.
Predicting Recall Probability to Adaptively Prioritize Study
Feb 28, 2018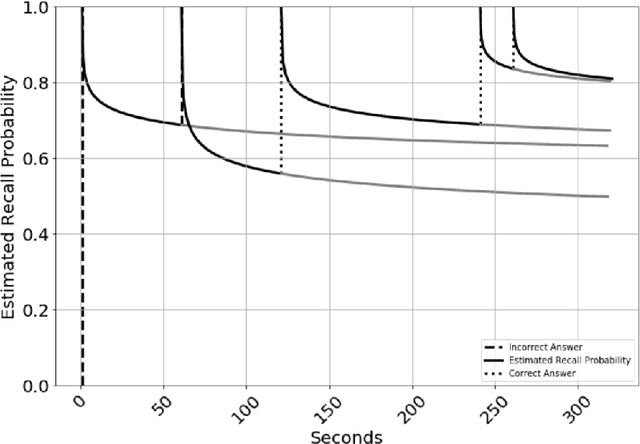
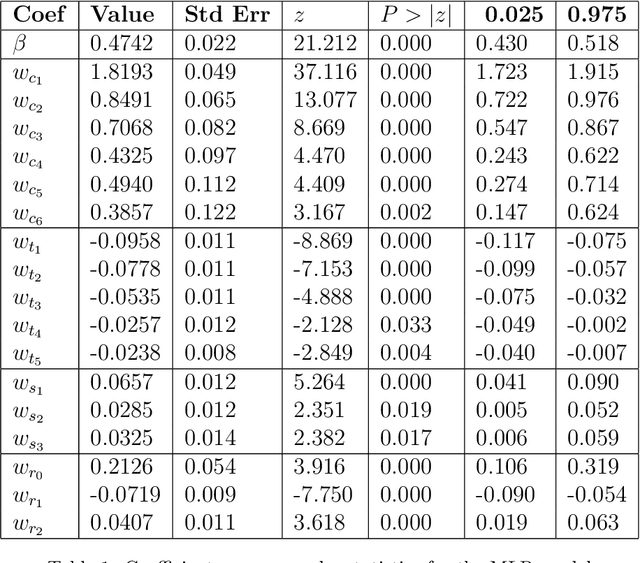

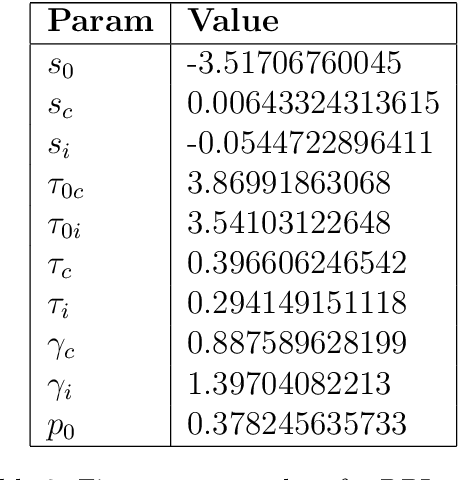
Students have a limited time to study and are typically ineffective at allocating study time. Machine-directed study strategies that identify which items need reinforcement and dictate the spacing of repetition have been shown to help students optimize mastery (Mozer & Lindsey 2017). The large volume of research on this matter is typically conducted in constructed experimental settings with fixed instruction, content, and scheduling; in contrast, we aim to develop methods that can address any demographic, subject matter, or study schedule. We show two methods that model item-specific recall probability for use in a discrepancy-reduction instruction strategy. The first model predicts item recall probability using a multiple logistic regression (MLR) model based on previous answer correctness and temporal spacing of study. Prompted by literature suggesting that forgetting is better modeled by the power law than an exponential decay (Wickelgren 1974), we compare the MLR approach with a Recurrent Power Law (RPL) model which adaptively fits a forgetting curve. We then discuss the performance of these models against study datasets comprised of millions of answers and show that the RPL approach is more accurate and flexible than the MLR model. Finally, we give an overview of promising future approaches to knowledge modeling.