 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslational Motion Compensation for Soft Tissue Velocity Images
Aug 20, 2018

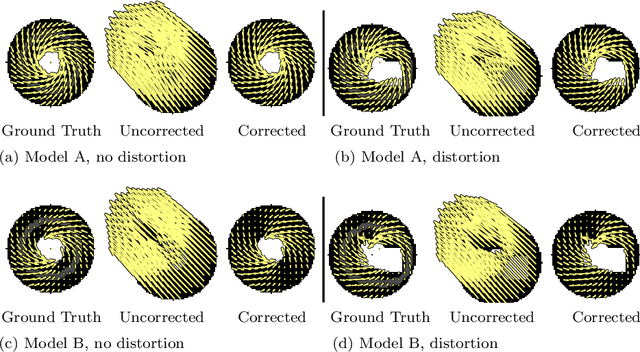
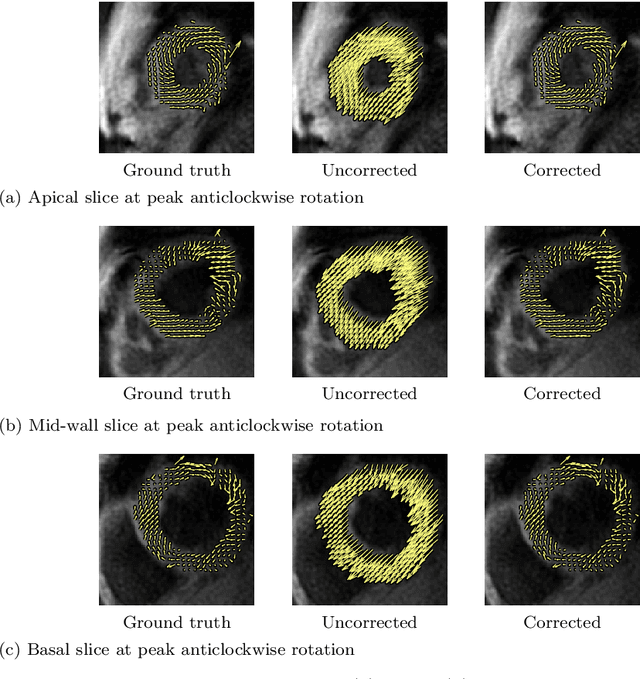
Purpose: Advancements in MRI Tissue Phase Velocity Mapping (TPM) allow for the acquisition of higher quality velocity cardiac images providing better assessment of regional myocardial deformation for accurate disease diagnosis, pre-operative planning and post-operative patient surveillance. Translation of TPM velocities from the scanner's reference coordinate system to the regional cardiac coordinate system requires decoupling of translational motion and motion due to myocardial deformation. Despite existing techniques for respiratory motion compensation in TPM, there is still a remaining translational velocity component due to the global motion of the beating heart. To compensate for translational motion in cardiac TPM, we propose an image-processing method, which we have evaluated on synthetic data and applied on in vivo TPM data. Methods: Translational motion is estimated from a suitable region of velocities automatically defined in the left-ventricular volume. The region is generated by dilating the medial axis of myocardial masks in each slice and the translational velocity is estimated by integration in this region. The method was evaluated on synthetic data and in vivo data corrupted with a translational velocity component (200% of the maximum measured velocity). Accuracy and robustness were examined and the method was applied on 10 in vivo datasets. Results: The results from synthetic and in vivo corrupted data show excellent performance with an estimation error less than 0.3% and high robustness in both cases. The effectiveness of the method is confirmed with visual observation of results from the 10 datasets. Conclusion: The proposed method is accurate and suitable for translational motion correction of the left ventricular velocity fields. The current method for translational motion compensation could be applied to any annular contracting (tissue) structure.
Near Real-time Hippocampus Segmentation Using Patch-based Canonical Neural Network
Jul 15, 2018

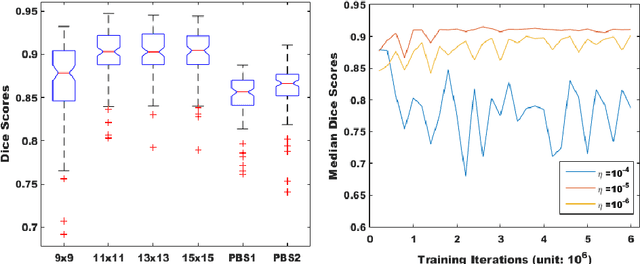

Over the past decades, state-of-the-art medical image segmentation has heavily rested on signal processing paradigms, most notably registration-based label propagation and pair-wise patch comparison, which are generally slow despite a high segmentation accuracy. In recent years, deep learning has revolutionalized computer vision with many practices outperforming prior art, in particular the convolutional neural network (CNN) studies on image classification. Deep CNN has also started being applied to medical image segmentation lately, but generally involves long training and demanding memory requirements, achieving limited success. We propose a patch-based deep learning framework based on a revisit to the classic neural network model with substantial modernization, including the use of Rectified Linear Unit (ReLU) activation, dropout layers, 2.5D tri-planar patch multi-pathway settings. In a test application to hippocampus segmentation using 100 brain MR images from the ADNI database, our approach significantly outperformed prior art in terms of both segmentation accuracy and speed: scoring a median Dice score up to 90.98% on a near real-time performance (<1s).
Learning Multiple Categories on Deep Convolution Networks
Feb 21, 2018


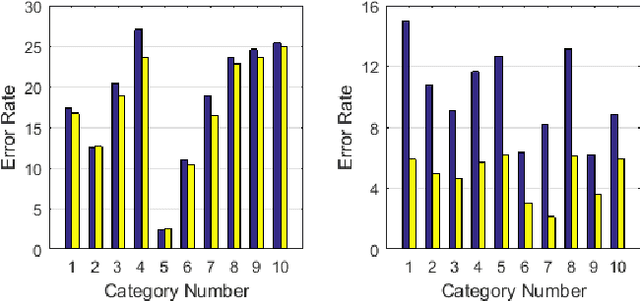
Deep convolution networks have proved very successful with big datasets such as the 1000-classes ImageNet. Results show that the error rate increases slowly as the size of the dataset increases. Experiments presented here may explain why these networks are very effective in solving big recognition problems. If the big task is made up of multiple smaller tasks, then the results show the ability of deep convolution networks to decompose the complex task into a number of smaller tasks and to learn them simultaneously. The results show that the performance of solving the big task on a single network is very close to the average performance of solving each of the smaller tasks on a separate network. Experiments also show the advantage of using task specific or category labels in combination with class labels.
Batch Normalization and the impact of batch structure on the behavior of deep convolution networks
Feb 21, 2018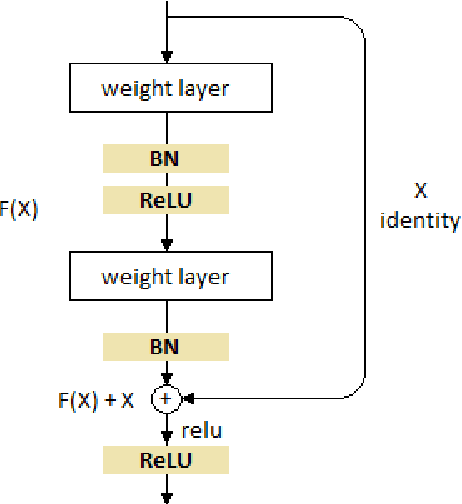
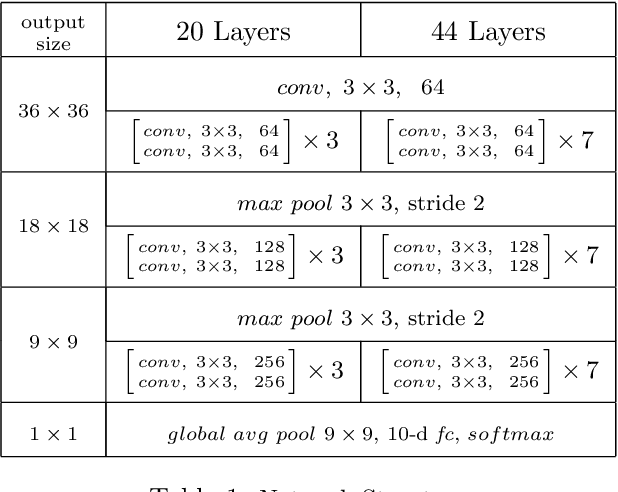

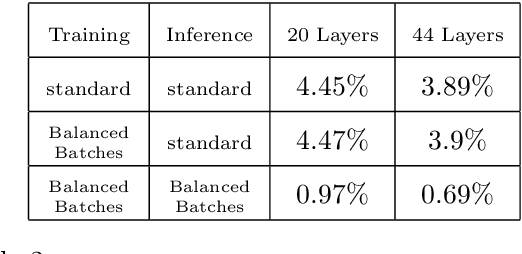
Batch normalization was introduced in 2015 to speed up training of deep convolution networks by normalizing the activations across the current batch to have zero mean and unity variance. The results presented here show an interesting aspect of batch normalization, where controlling the shape of the training batches can influence what the network will learn. If training batches are structured as balanced batches (one image per class), and inference is also carried out on balanced test batches, using the batch's own means and variances, then the conditional results will improve considerably. The network uses the strong information about easy images in a balanced batch, and propagates it through the shared means and variances to help decide the identity of harder images on the same batch. Balancing the test batches requires the labels of the test images, which are not available in practice, however further investigation can be done using batch structures that are less strict and might not require the test image labels. The conditional results show the error rate almost reduced to zero for nontrivial datasets with small number of classes such as the CIFAR10.