 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch Normalization and the impact of batch structure on the behavior of deep convolution networks
Paper and Code
Feb 21, 2018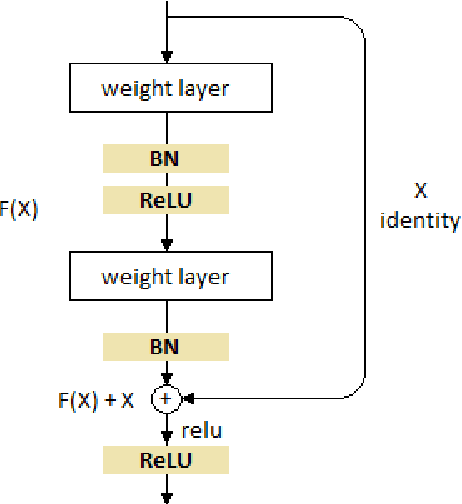
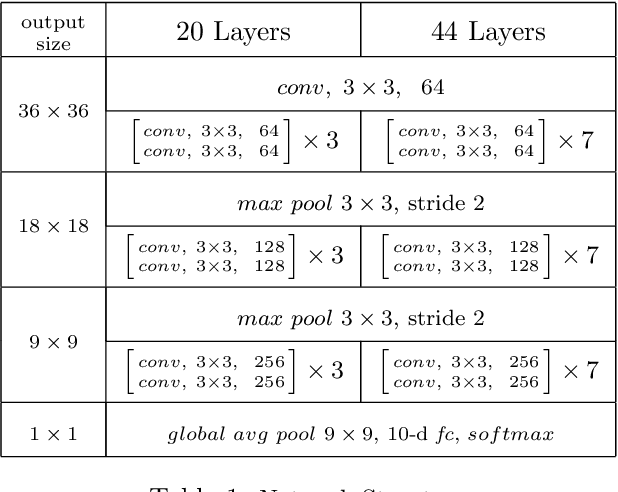

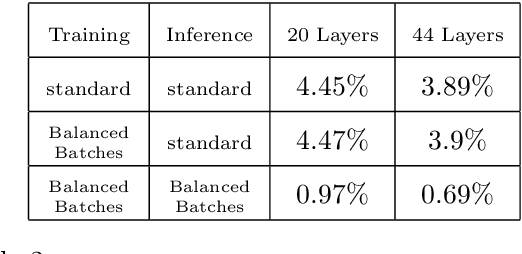
Batch normalization was introduced in 2015 to speed up training of deep convolution networks by normalizing the activations across the current batch to have zero mean and unity variance. The results presented here show an interesting aspect of batch normalization, where controlling the shape of the training batches can influence what the network will learn. If training batches are structured as balanced batches (one image per class), and inference is also carried out on balanced test batches, using the batch's own means and variances, then the conditional results will improve considerably. The network uses the strong information about easy images in a balanced batch, and propagates it through the shared means and variances to help decide the identity of harder images on the same batch. Balancing the test batches requires the labels of the test images, which are not available in practice, however further investigation can be done using batch structures that are less strict and might not require the test image labels. The conditional results show the error rate almost reduced to zero for nontrivial datasets with small number of classes such as the CIFAR10.