 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaritime object classification with SAR imagery using quantum kernel methods
Dec 12, 2025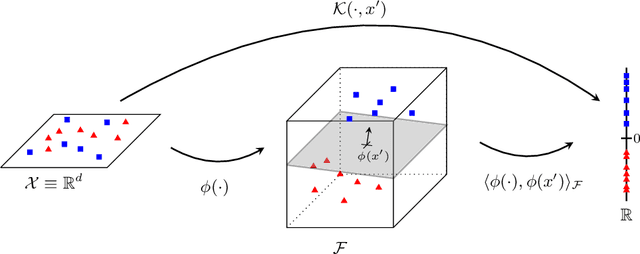
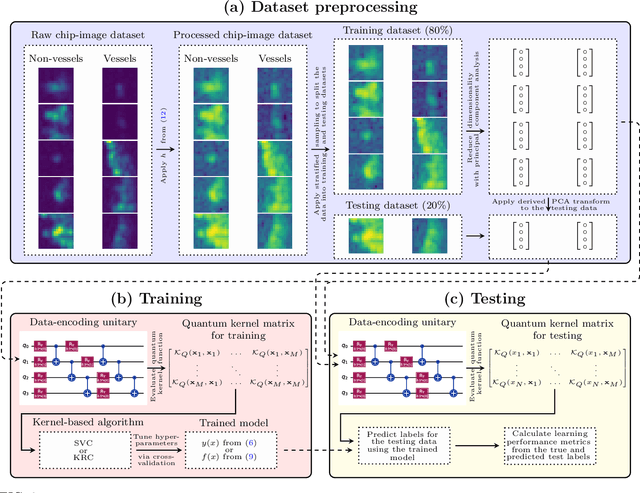
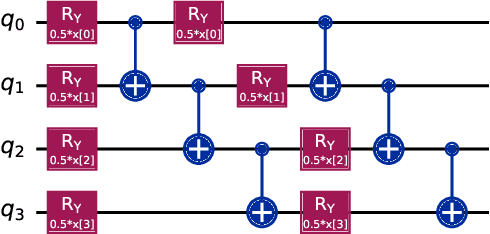
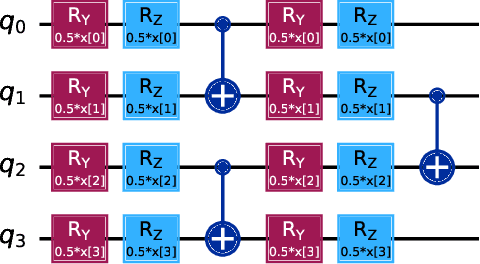
Illegal, unreported, and unregulated (IUU) fishing causes global economic losses of \$10-25 billion annually and undermines marine sustainability and governance. Synthetic Aperture Radar (SAR) provides reliable maritime surveillance under all weather and lighting conditions, but classifying small maritime objects in SAR imagery remains challenging. We investigate quantum machine learning for this task, focusing on Quantum Kernel Methods (QKMs) applied to real and complex SAR chips extracted from the SARFish dataset. We tackle two binary classification problems, the first for distinguishing vessels from non-vessels, and the second for distinguishing fishing vessels from other types of vessels. We compare QKMs applied to real and complex SAR chips against classical Laplacian, RBF, and linear kernels applied to real SAR chips. Using noiseless numerical simulations of the quantum kernels, we find that QKMs are capable of obtaining equal or better performance than the classical kernel on these tasks in the best case, but do not demonstrate a clear advantage for the complex SAR data. This work presents the first application of QKMs to maritime classification in SAR imagery and offers insight into the potential and current limitations of quantum-enhanced learning for maritime surveillance.
DocSpiral: A Platform for Integrated Assistive Document Annotation through Human-in-the-Spiral
May 06, 2025Acquiring structured data from domain-specific, image-based documents such as scanned reports is crucial for many downstream tasks but remains challenging due to document variability. Many of these documents exist as images rather than as machine-readable text, which requires human annotation to train automated extraction systems. We present DocSpiral, the first Human-in-the-Spiral assistive document annotation platform, designed to address the challenge of extracting structured information from domain-specific, image-based document collections. Our spiral design establishes an iterative cycle in which human annotations train models that progressively require less manual intervention. DocSpiral integrates document format normalization, comprehensive annotation interfaces, evaluation metrics dashboard, and API endpoints for the development of AI / ML models into a unified workflow. Experiments demonstrate that our framework reduces annotation time by at least 41\% while showing consistent performance gains across three iterations during model training. By making this annotation platform freely accessible, we aim to lower barriers to AI/ML models development in document processing, facilitating the adoption of large language models in image-based, document-intensive fields such as geoscience and healthcare. The system is freely available at: https://app.ai4wa.com. The demonstration video is available: https://app.ai4wa.com/docs/docspiral/demo.
TimelineKGQA: A Comprehensive Question-Answer Pair Generator for Temporal Knowledge Graphs
Jan 08, 2025



Question answering over temporal knowledge graphs (TKGs) is crucial for understanding evolving facts and relationships, yet its development is hindered by limited datasets and difficulties in generating custom QA pairs. We propose a novel categorization framework based on timeline-context relationships, along with \textbf{TimelineKGQA}, a universal temporal QA generator applicable to any TKGs. The code is available at: \url{https://github.com/PascalSun/TimelineKGQA} as an open source Python package.
Histogram of Oriented Principal Components for Cross-View Action Recognition
Sep 03, 2015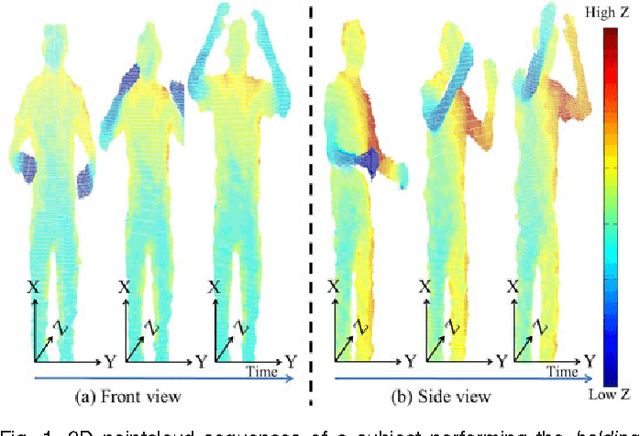

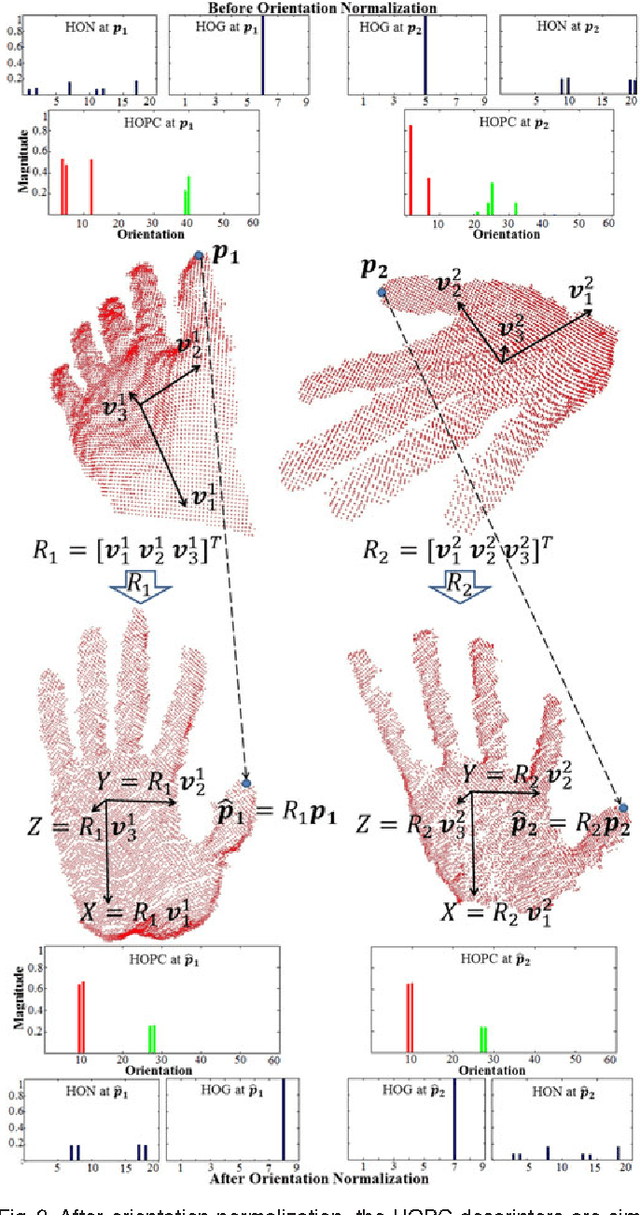

Existing techniques for 3D action recognition are sensitive to viewpoint variations because they extract features from depth images which are viewpoint dependent. In contrast, we directly process pointclouds for cross-view action recognition from unknown and unseen views. We propose the Histogram of Oriented Principal Components (HOPC) descriptor that is robust to noise, viewpoint, scale and action speed variations. At a 3D point, HOPC is computed by projecting the three scaled eigenvectors of the pointcloud within its local spatio-temporal support volume onto the vertices of a regular dodecahedron. HOPC is also used for the detection of Spatio-Temporal Keypoints (STK) in 3D pointcloud sequences so that view-invariant STK descriptors (or Local HOPC descriptors) at these key locations only are used for action recognition. We also propose a global descriptor computed from the normalized spatio-temporal distribution of STKs in 4-D, which we refer to as STK-D. We have evaluated the performance of our proposed descriptors against nine existing techniques on two cross-view and three single-view human action recognition datasets. The Experimental results show that our techniques provide significant improvement over state-of-the-art methods.
Action Classification with Locality-constrained Linear Coding
Sep 22, 2014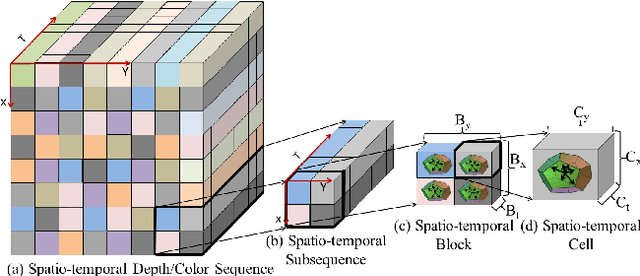
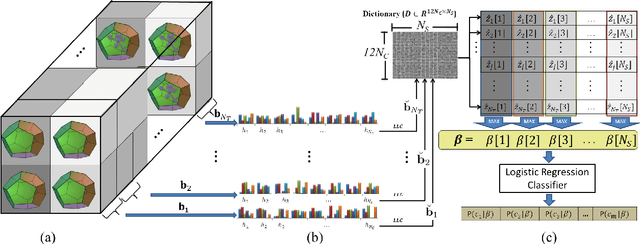
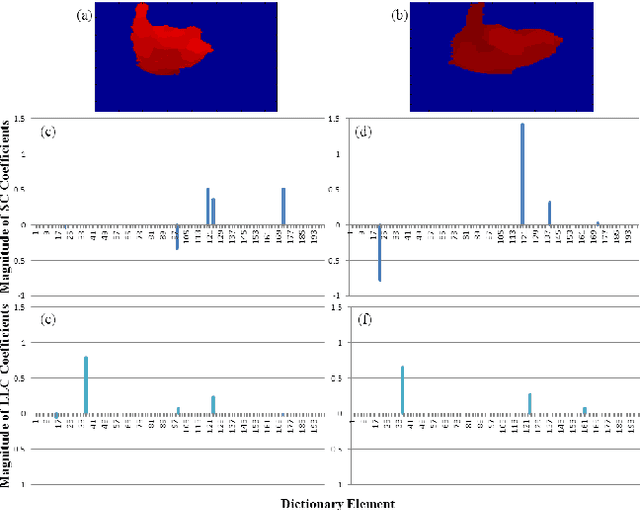
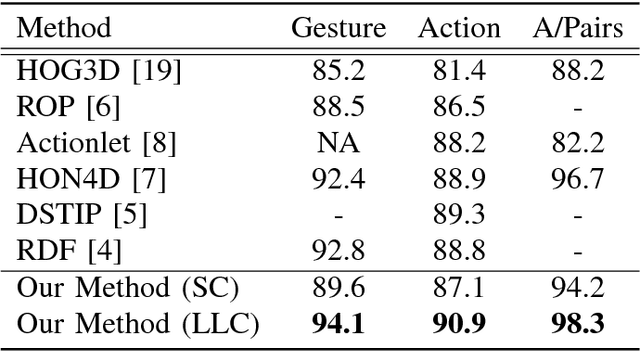
We propose an action classification algorithm which uses Locality-constrained Linear Coding (LLC) to capture discriminative information of human body variations in each spatiotemporal subsequence of a video sequence. Our proposed method divides the input video into equally spaced overlapping spatiotemporal subsequences, each of which is decomposed into blocks and then cells. We use the Histogram of Oriented Gradient (HOG3D) feature to encode the information in each cell. We justify the use of LLC for encoding the block descriptor by demonstrating its superiority over Sparse Coding (SC). Our sequence descriptor is obtained via a logistic regression classifier with L2 regularization. We evaluate and compare our algorithm with ten state-of-the-art algorithms on five benchmark datasets. Experimental results show that, on average, our algorithm gives better accuracy than these ten algorithms.