 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Knowledge Distillation: Building Ensembles for Efficient Inference
Feb 20, 2023



We study the problem of progressive distillation: Given a large, pre-trained teacher model $g$, we seek to decompose the model into an ensemble of smaller, low-inference cost student models $f_i$. The resulting ensemble allows for flexibly tuning accuracy vs. inference cost, which is useful for a number of applications in on-device inference. The method we propose, B-DISTIL, relies on an algorithmic procedure that uses function composition over intermediate activations to construct expressive ensembles with similar performance as $g$, but with much smaller student models. We demonstrate the effectiveness of \algA by decomposing pretrained models across standard image, speech, and sensor datasets. We also provide theoretical guarantees for our method in terms of convergence and generalization.
Heterogeneity for the Win: One-Shot Federated Clustering
Mar 01, 2021
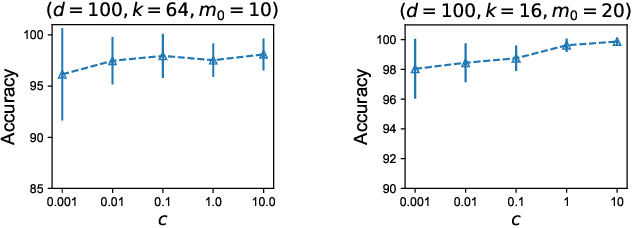
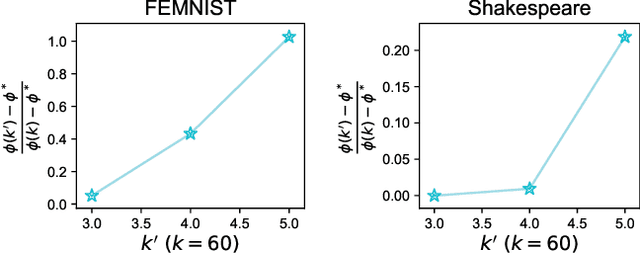
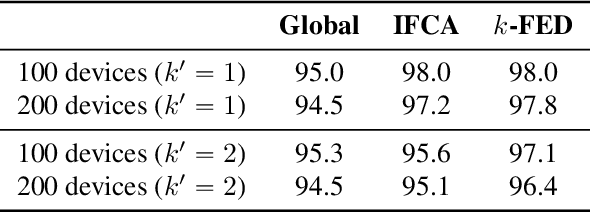
In this work, we explore the unique challenges -- and opportunities -- of unsupervised federated learning (FL). We develop and analyze a one-shot federated clustering scheme, $k$-FED, based on the widely-used Lloyd's method for $k$-means clustering. In contrast to many supervised problems, we show that the issue of statistical heterogeneity in federated networks can in fact benefit our analysis. We analyse $k$-FED under a center separation assumption and compare it to the best known requirements of its centralized counterpart. Our analysis shows that in heterogeneous regimes where the number of clusters per device $(k')$ is smaller than the total number of clusters over the network $k$, $(k'\le \sqrt{k})$, we can use heterogeneity to our advantage -- significantly weakening the cluster separation requirements for $k$-FED. From a practical viewpoint, $k$-FED also has many desirable properties: it requires only round of communication, can run asynchronously, and can handle partial participation or node/network failures. We motivate our analysis with experiments on common FL benchmarks, and highlight the practical utility of one-shot clustering through use-cases in personalized FL and device sampling.