 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Knowledge Distillation: Building Ensembles for Efficient Inference
Paper and Code
Feb 20, 2023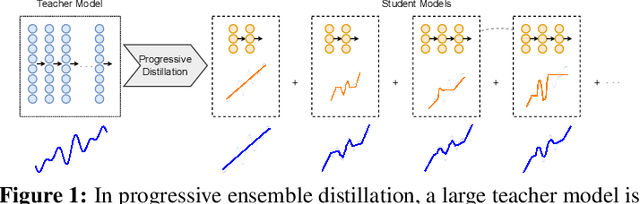



We study the problem of progressive distillation: Given a large, pre-trained teacher model $g$, we seek to decompose the model into an ensemble of smaller, low-inference cost student models $f_i$. The resulting ensemble allows for flexibly tuning accuracy vs. inference cost, which is useful for a number of applications in on-device inference. The method we propose, B-DISTIL, relies on an algorithmic procedure that uses function composition over intermediate activations to construct expressive ensembles with similar performance as $g$, but with much smaller student models. We demonstrate the effectiveness of \algA by decomposing pretrained models across standard image, speech, and sensor datasets. We also provide theoretical guarantees for our method in terms of convergence and generalization.