 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Differentially Private Online Federated Learning With Correlated Noise
Nov 27, 2024We introduce a locally differentially private (LDP) algorithm for online federated learning that employs temporally correlated noise to improve utility while preserving privacy. To address challenges posed by the correlated noise and local updates with streaming non-IID data, we develop a perturbed iterate analysis that controls the impact of the noise on the utility. Moreover, we demonstrate how the drift errors from local updates can be effectively managed for several classes of nonconvex loss functions. Subject to an $(\epsilon,\delta)$-LDP budget, we establish a dynamic regret bound that quantifies the impact of key parameters and the intensity of changes in the dynamic environment on the learning performance. Numerical experiments confirm the efficacy of the proposed algorithm.
Dynamic Privacy Allocation for Locally Differentially Private Federated Learning with Composite Objectives
Aug 02, 2023This paper proposes a locally differentially private federated learning algorithm for strongly convex but possibly nonsmooth problems that protects the gradients of each worker against an honest but curious server. The proposed algorithm adds artificial noise to the shared information to ensure privacy and dynamically allocates the time-varying noise variance to minimize an upper bound of the optimization error subject to a predefined privacy budget constraint. This allows for an arbitrarily large but finite number of iterations to achieve both privacy protection and utility up to a neighborhood of the optimal solution, removing the need for tuning the number of iterations. Numerical results show the superiority of the proposed algorithm over state-of-the-art methods.
Privacy Amplification via Importance Sampling
Jul 05, 2023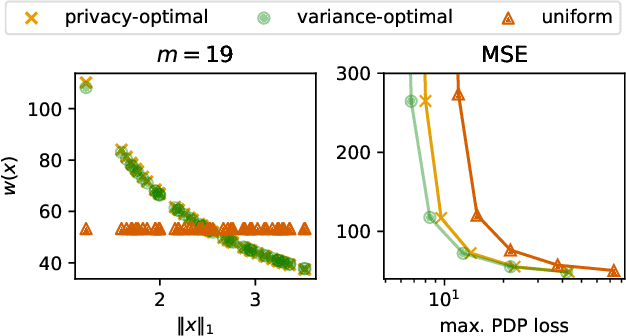



We examine the privacy-enhancing properties of subsampling a data set via importance sampling as a pre-processing step for differentially private mechanisms. This extends the established privacy amplification by subsampling result to importance sampling where each data point is weighted by the reciprocal of its selection probability. The implications for privacy of weighting each point are not obvious. On the one hand, a lower selection probability leads to a stronger privacy amplification. On the other hand, the higher the weight, the stronger the influence of the point on the output of the mechanism in the event that the point does get selected. We provide a general result that quantifies the trade-off between these two effects. We show that heterogeneous sampling probabilities can lead to both stronger privacy and better utility than uniform subsampling while retaining the subsample size. In particular, we formulate and solve the problem of privacy-optimal sampling, that is, finding the importance weights that minimize the expected subset size subject to a given privacy budget. Empirically, we evaluate the privacy, efficiency, and accuracy of importance sampling-based privacy amplification on the example of k-means clustering.
Decentralized Differentially Private Segmentation with PATE
Apr 10, 2020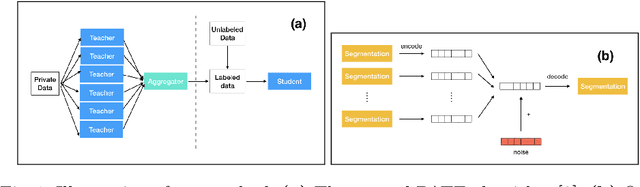
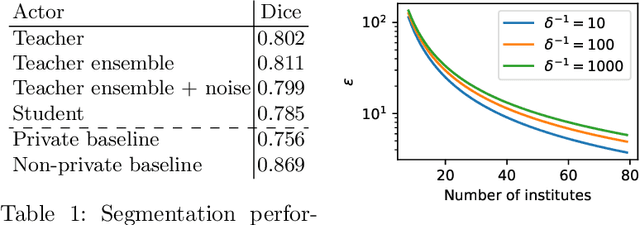
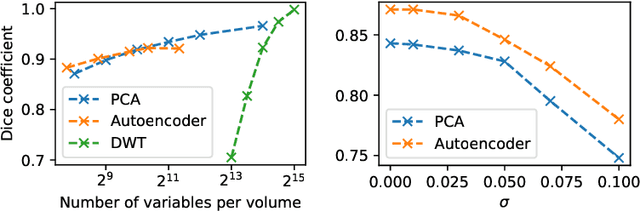
When it comes to preserving privacy in medical machine learning, two important considerations are (1) keeping data local to the institution and (2) avoiding inference of sensitive information from the trained model. These are often addressed using federated learning and differential privacy, respectively. However, the commonly used Federated Averaging algorithm requires a high degree of synchronization between participating institutions. For this reason, we turn our attention to Private Aggregation of Teacher Ensembles (PATE), where all local models can be trained independently without inter-institutional communication. The purpose of this paper is thus to explore how PATE -- originally designed for classification -- can best be adapted for semantic segmentation. To this end, we build low-dimensional representations of segmentation masks which the student can obtain through low-sensitivity queries to the private aggregator. On the Brain Tumor Segmentation (BraTS 2019) dataset, an Autoencoder-based PATE variant achieves a higher Dice coefficient for the same privacy guarantee than prior work based on noisy Federated Averaging.
Implementing Adaptive Separable Convolution for Video Frame Interpolation
Sep 20, 2018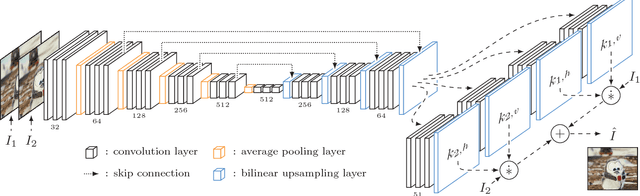
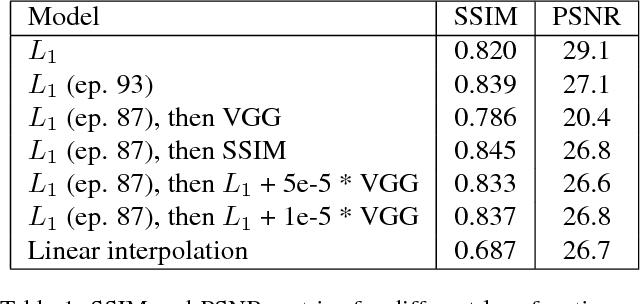

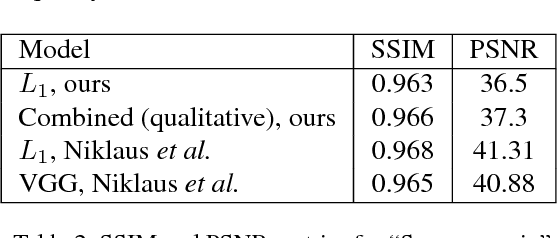
As Deep Neural Networks are becoming more popular, much of the attention is being devoted to Computer Vision problems that used to be solved with more traditional approaches. Video frame interpolation is one of such challenges that has seen new research involving various techniques in deep learning. In this paper, we replicate the work of Niklaus et al. on Adaptive Separable Convolution, which claims high quality results on the video frame interpolation task. We apply the same network structure trained on a smaller dataset and experiment with various different loss functions, in order to determine the optimal approach in data-scarce scenarios. The best resulting model is still able to provide visually pleasing videos, although achieving lower evaluation scores.