 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVote3Deep: Fast Object Detection in 3D Point Clouds Using Efficient Convolutional Neural Networks
Mar 05, 2017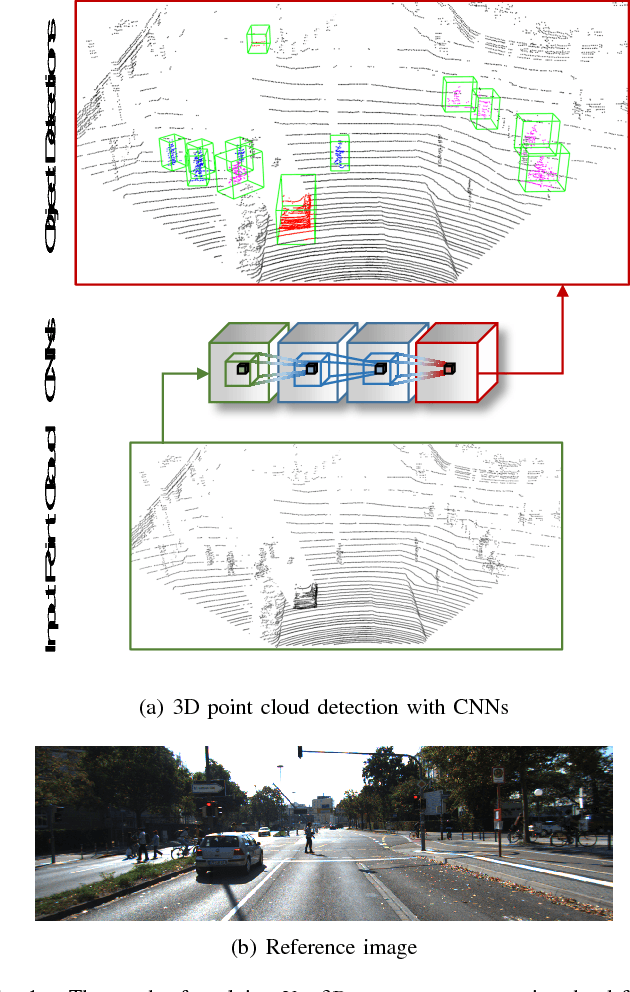
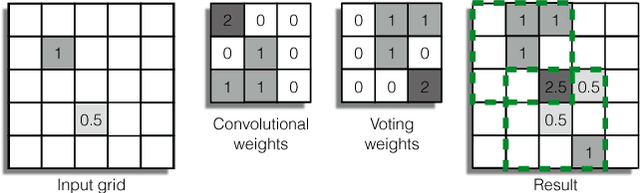

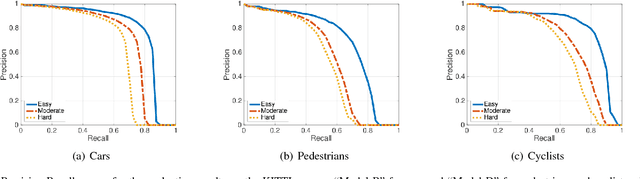
This paper proposes a computationally efficient approach to detecting objects natively in 3D point clouds using convolutional neural networks (CNNs). In particular, this is achieved by leveraging a feature-centric voting scheme to implement novel convolutional layers which explicitly exploit the sparsity encountered in the input. To this end, we examine the trade-off between accuracy and speed for different architectures and additionally propose to use an L1 penalty on the filter activations to further encourage sparsity in the intermediate representations. To the best of our knowledge, this is the first work to propose sparse convolutional layers and L1 regularisation for efficient large-scale processing of 3D data. We demonstrate the efficacy of our approach on the KITTI object detection benchmark and show that Vote3Deep models with as few as three layers outperform the previous state of the art in both laser and laser-vision based approaches by margins of up to 40% while remaining highly competitive in terms of processing time.
Watch This: Scalable Cost-Function Learning for Path Planning in Urban Environments
Jul 08, 2016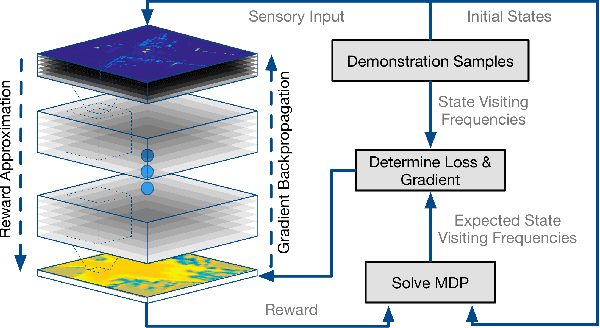
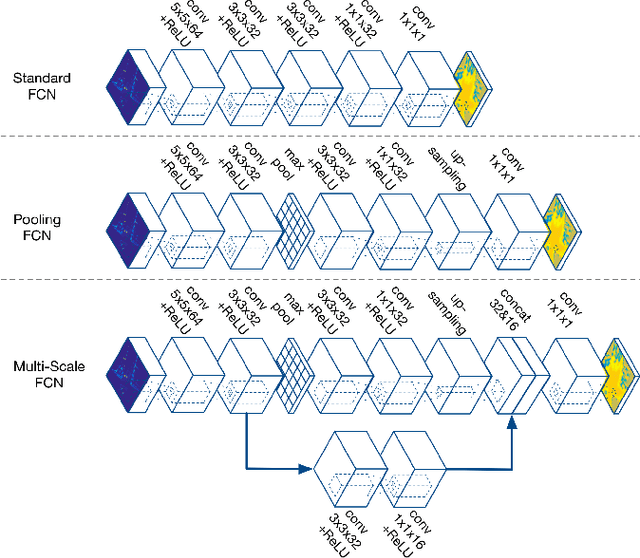

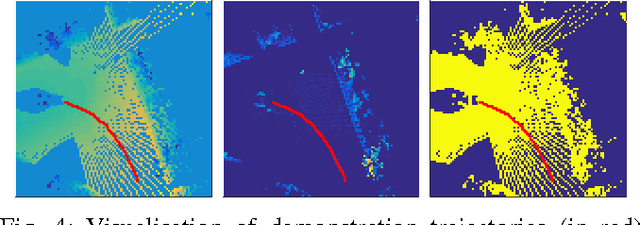
In this work, we present an approach to learn cost maps for driving in complex urban environments from a very large number of demonstrations of driving behaviour by human experts. The learned cost maps are constructed directly from raw sensor measurements, bypassing the effort of manually designing cost maps as well as features. When deploying the learned cost maps, the trajectories generated not only replicate human-like driving behaviour but are also demonstrably robust against systematic errors in putative robot configuration. To achieve this we deploy a Maximum Entropy based, non-linear IRL framework which uses Fully Convolutional Neural Networks (FCNs) to represent the cost model underlying expert driving behaviour. Using a deep, parametric approach enables us to scale efficiently to large datasets and complex behaviours by being run-time independent of dataset extent during deployment. We demonstrate the scalability and the performance of the proposed approach on an ambitious dataset collected over the course of one year including more than 25k demonstration trajectories extracted from over 120km of driving around pedestrianised areas in the city of Milton Keynes, UK. We evaluate the resulting cost representations by showing the advantages over a carefully manually designed cost map and, in addition, demonstrate its robustness to systematic errors by learning precise cost-maps even in the presence of system calibration perturbations.
End-to-End Tracking and Semantic Segmentation Using Recurrent Neural Networks
Apr 19, 2016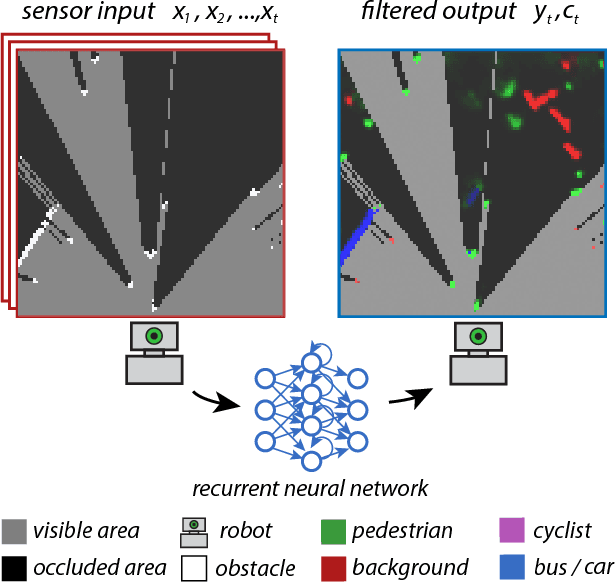
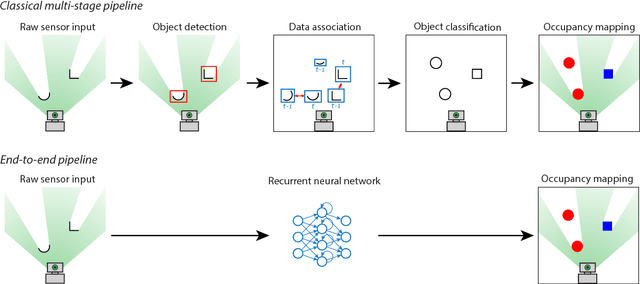
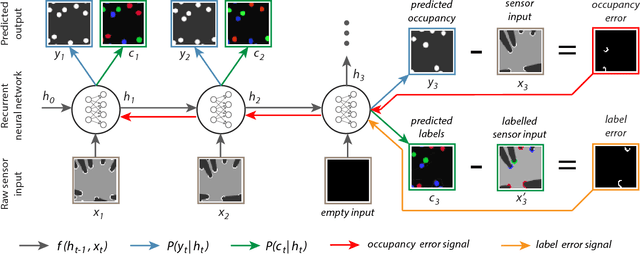
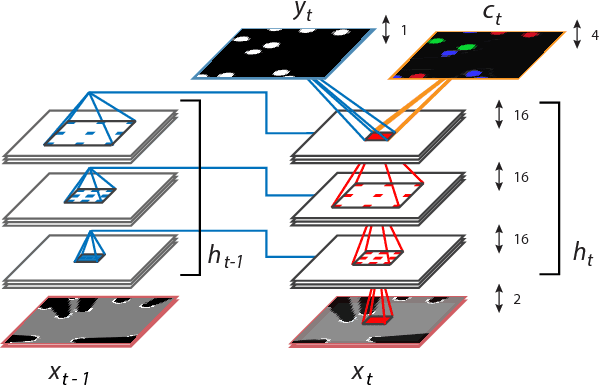
In this work we present a novel end-to-end framework for tracking and classifying a robot's surroundings in complex, dynamic and only partially observable real-world environments. The approach deploys a recurrent neural network to filter an input stream of raw laser measurements in order to directly infer object locations, along with their identity in both visible and occluded areas. To achieve this we first train the network using unsupervised Deep Tracking, a recently proposed theoretical framework for end-to-end space occupancy prediction. We show that by learning to track on a large amount of unsupervised data, the network creates a rich internal representation of its environment which we in turn exploit through the principle of inductive transfer of knowledge to perform the task of it's semantic classification. As a result, we show that only a small amount of labelled data suffices to steer the network towards mastering this additional task. Furthermore we propose a novel recurrent neural network architecture specifically tailored to tracking and semantic classification in real-world robotics applications. We demonstrate the tracking and classification performance of the method on real-world data collected at a busy road junction. Our evaluation shows that the proposed end-to-end framework compares favourably to a state-of-the-art, model-free tracking solution and that it outperforms a conventional one-shot training scheme for semantic classification.