 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiSight: Towards expert-AI co-assessment for improved immunohistochemistry staining interpretation
Feb 03, 2026Immunohistochemistry (IHC) provides information on protein expression in tissue sections and is commonly used to support pathology diagnosis and disease triage. While AI models for H\&E-stained slides show promise, their applicability to IHC is limited due to domain-specific variations. Here we introduce HPA10M, a dataset that contains 10,495,672 IHC images from the Human Protein Atlas with comprehensive metadata included, and encompasses 45 normal tissue types and 20 major cancer types. Based on HPA10M, we trained iSight, a multi-task learning framework for automated IHC staining assessment. iSight combines visual features from whole-slide images with tissue metadata through a token-level attention mechanism, simultaneously predicting staining intensity, location, quantity, tissue type, and malignancy status. On held-out data, iSight achieved 85.5\% accuracy for location, 76.6\% for intensity, and 75.7\% for quantity, outperforming fine-tuned foundation models (PLIP, CONCH) by 2.5--10.2\%. In addition, iSight demonstrates well-calibrated predictions with expected calibration errors of 0.0150-0.0408. Furthermore, in a user study with eight pathologists evaluating 200 images from two datasets, iSight outperformed initial pathologist assessments on the held-out HPA dataset (79\% vs 68\% for location, 70\% vs 57\% for intensity, 68\% vs 52\% for quantity). Inter-pathologist agreement also improved after AI assistance in both held-out HPA (Cohen's $κ$ increased from 0.63 to 0.70) and Stanford TMAD datasets (from 0.74 to 0.76), suggesting expert--AI co-assessment can improve IHC interpretation. This work establishes a foundation for AI systems that can improve IHC diagnostic accuracy and highlights the potential for integrating iSight into clinical workflows to enhance the consistency and reliability of IHC assessment.
Modeling Path Importance for Effective Alzheimer's Disease Drug Repurposing
Oct 27, 2023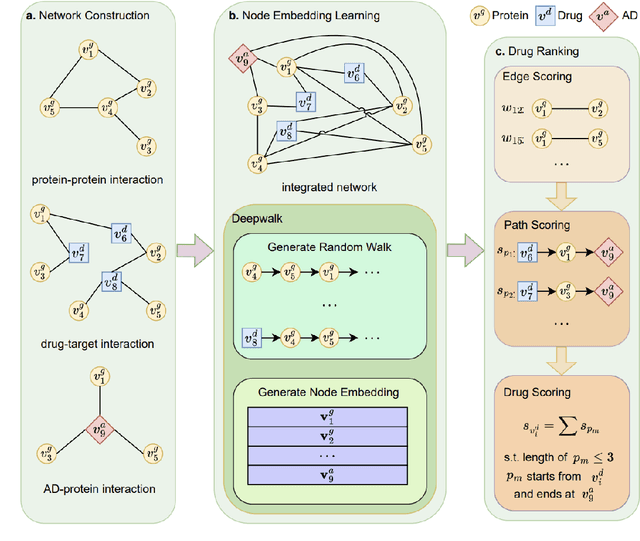

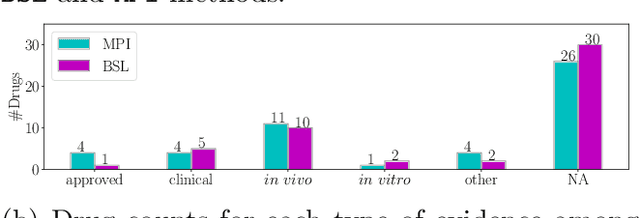

Recently, drug repurposing has emerged as an effective and resource-efficient paradigm for AD drug discovery. Among various methods for drug repurposing, network-based methods have shown promising results as they are capable of leveraging complex networks that integrate multiple interaction types, such as protein-protein interactions, to more effectively identify candidate drugs. However, existing approaches typically assume paths of the same length in the network have equal importance in identifying the therapeutic effect of drugs. Other domains have found that same length paths do not necessarily have the same importance. Thus, relying on this assumption may be deleterious to drug repurposing attempts. In this work, we propose MPI (Modeling Path Importance), a novel network-based method for AD drug repurposing. MPI is unique in that it prioritizes important paths via learned node embeddings, which can effectively capture a network's rich structural information. Thus, leveraging learned embeddings allows MPI to effectively differentiate the importance among paths. We evaluate MPI against a commonly used baseline method that identifies anti-AD drug candidates primarily based on the shortest paths between drugs and AD in the network. We observe that among the top-50 ranked drugs, MPI prioritizes 20.0% more drugs with anti-AD evidence compared to the baseline. Finally, Cox proportional-hazard models produced from insurance claims data aid us in identifying the use of etodolac, nicotine, and BBB-crossing ACE-INHs as having a reduced risk of AD, suggesting such drugs may be viable candidates for repurposing and should be explored further in future studies.