 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Path Importance for Effective Alzheimer's Disease Drug Repurposing
Oct 27, 2023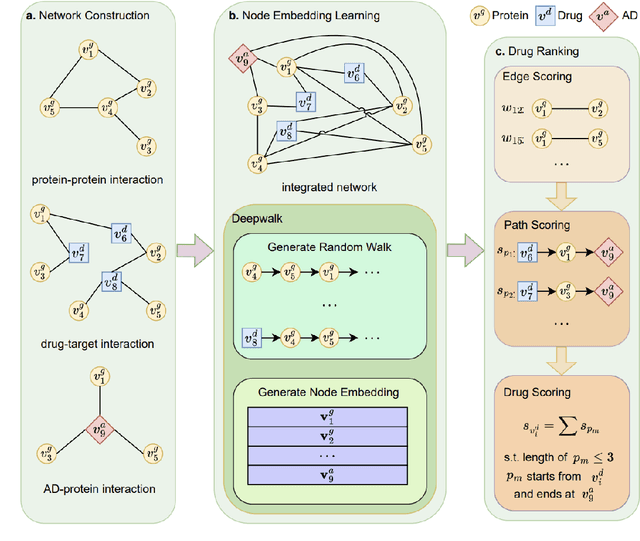

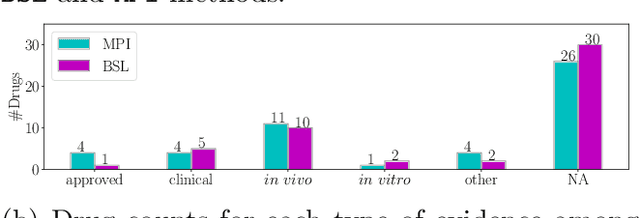

Recently, drug repurposing has emerged as an effective and resource-efficient paradigm for AD drug discovery. Among various methods for drug repurposing, network-based methods have shown promising results as they are capable of leveraging complex networks that integrate multiple interaction types, such as protein-protein interactions, to more effectively identify candidate drugs. However, existing approaches typically assume paths of the same length in the network have equal importance in identifying the therapeutic effect of drugs. Other domains have found that same length paths do not necessarily have the same importance. Thus, relying on this assumption may be deleterious to drug repurposing attempts. In this work, we propose MPI (Modeling Path Importance), a novel network-based method for AD drug repurposing. MPI is unique in that it prioritizes important paths via learned node embeddings, which can effectively capture a network's rich structural information. Thus, leveraging learned embeddings allows MPI to effectively differentiate the importance among paths. We evaluate MPI against a commonly used baseline method that identifies anti-AD drug candidates primarily based on the shortest paths between drugs and AD in the network. We observe that among the top-50 ranked drugs, MPI prioritizes 20.0% more drugs with anti-AD evidence compared to the baseline. Finally, Cox proportional-hazard models produced from insurance claims data aid us in identifying the use of etodolac, nicotine, and BBB-crossing ACE-INHs as having a reduced risk of AD, suggesting such drugs may be viable candidates for repurposing and should be explored further in future studies.
Enhancing drug and cell line representations via contrastive learning for improved anti-cancer drug prioritization
Oct 27, 2023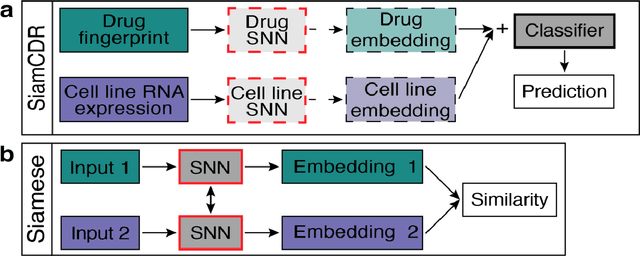

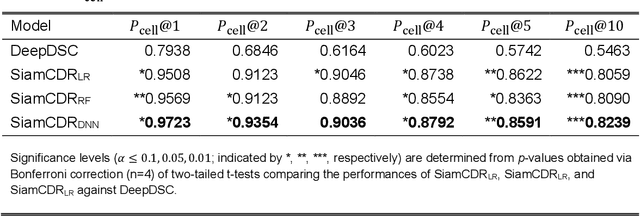
Due to cancer's complex nature and variable response to therapy, precision oncology informed by omics sequence analysis has become the current standard of care. However, the amount of data produced for each patients makes it difficult to quickly identify the best treatment regimen. Moreover, limited data availability has hindered computational methods' abilities to learn patterns associated with effective drug-cell line pairs. In this work, we propose the use of contrastive learning to improve learned drug and cell line representations by preserving relationship structures associated with drug mechanism of action and cell line cancer types. In addition to achieving enhanced performance relative to a state-of-the-art method, we find that classifiers using our learned representations exhibit a more balances reliance on drug- and cell line-derived features when making predictions. This facilitates more personalized drug prioritizations that are informed by signals related to drug resistance.