 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Ensemble for Offline RL: Don't Scale the Ensemble, Scale the Batch Size
Nov 20, 2022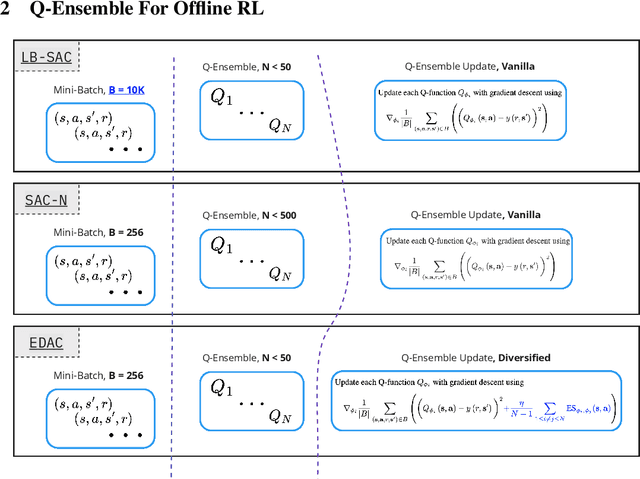
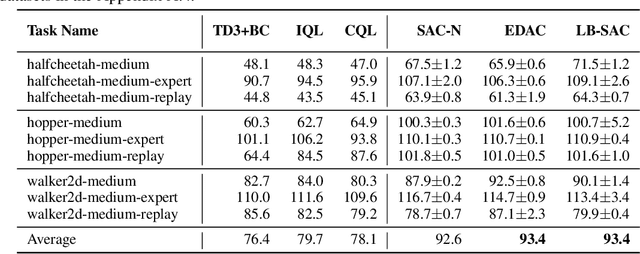
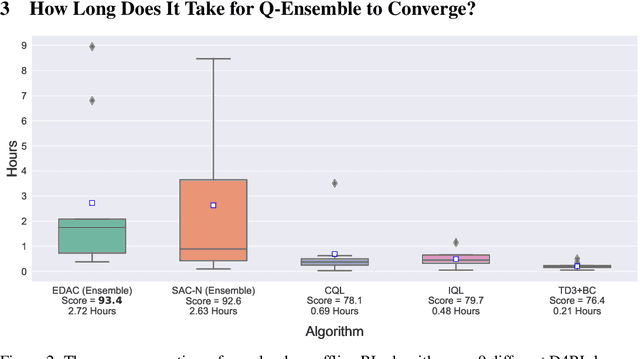
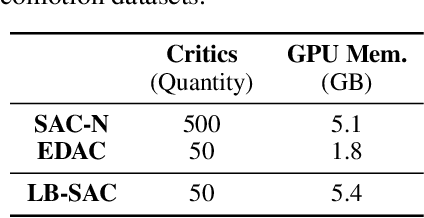
Training large neural networks is known to be time-consuming, with the learning duration taking days or even weeks. To address this problem, large-batch optimization was introduced. This approach demonstrated that scaling mini-batch sizes with appropriate learning rate adjustments can speed up the training process by orders of magnitude. While long training time was not typically a major issue for model-free deep offline RL algorithms, recently introduced Q-ensemble methods achieving state-of-the-art performance made this issue more relevant, notably extending the training duration. In this work, we demonstrate how this class of methods can benefit from large-batch optimization, which is commonly overlooked by the deep offline RL community. We show that scaling the mini-batch size and naively adjusting the learning rate allows for (1) a reduced size of the Q-ensemble, (2) stronger penalization of out-of-distribution actions, and (3) improved convergence time, effectively shortening training duration by 3-4x times on average.
CORL: Research-oriented Deep Offline Reinforcement Learning Library
Oct 13, 2022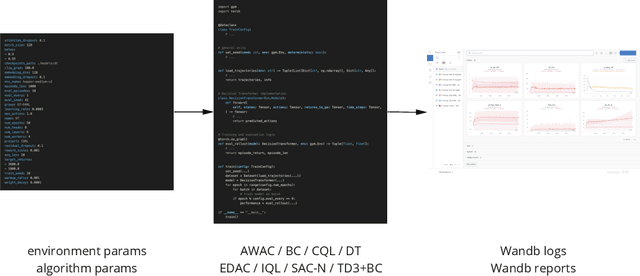
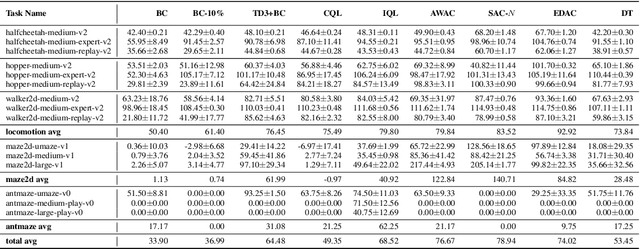
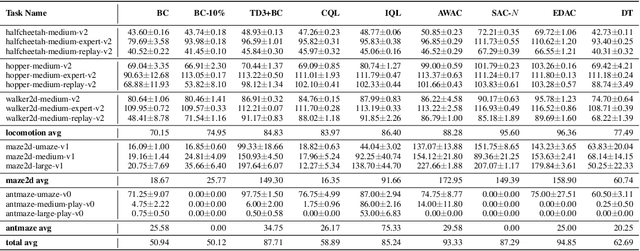
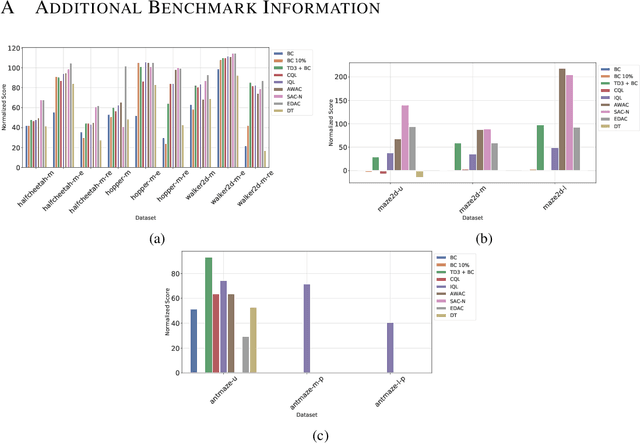
CORL is an open-source library that provides single-file implementations of Deep Offline Reinforcement Learning algorithms. It emphasizes a simple developing experience with a straightforward codebase and a modern analysis tracking tool. In CORL, we isolate methods implementation into distinct single files, making performance-relevant details easier to recognise. Additionally, an experiment tracking feature is available to help log metrics, hyperparameters, dependencies, and more to the cloud. Finally, we have ensured the reliability of the implementations by benchmarking a commonly employed D4RL benchmark. The source code can be found https://github.com/tinkoff-ai/CORL
Distributed Soft Actor-Critic with Multivariate Reward Representation and Knowledge Distillation
Nov 29, 2019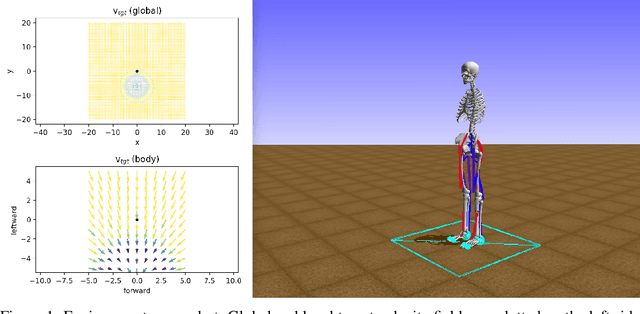
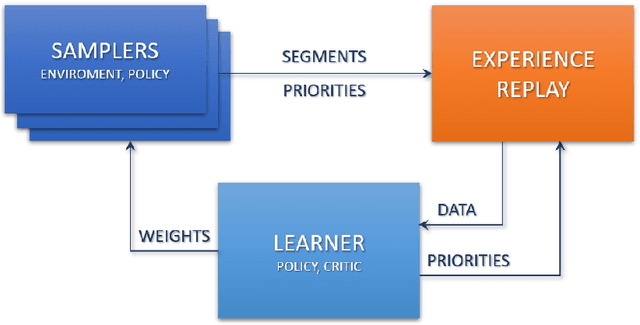
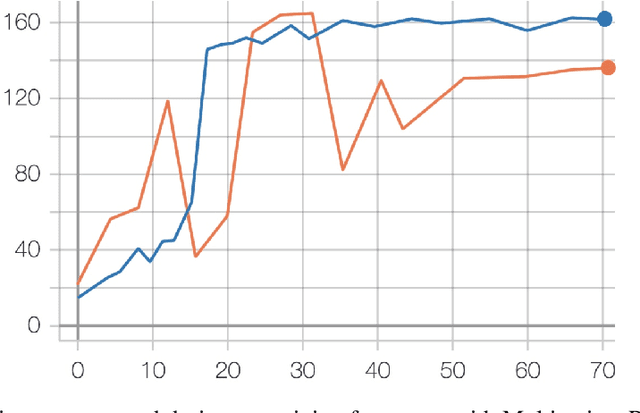
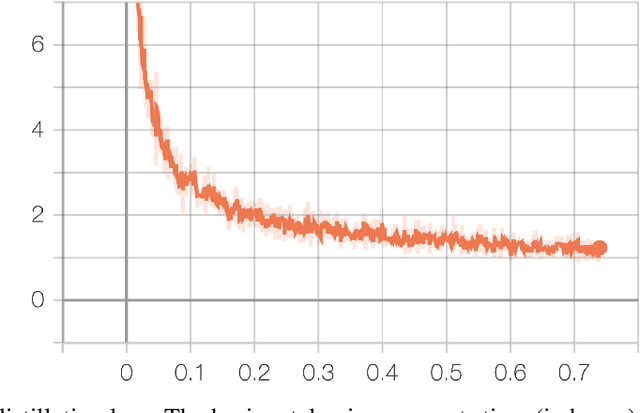
In this paper, we describe NeurIPS 2019 Learning to Move - Walk Around challenge physics-based environment and present our solution to this competition which scored 1303.727 mean reward points and took 3rd place. Our method combines recent advances from both continuous- and discrete-action space reinforcement learning, such as Soft Actor-Critic and Recurrent Experience Replay in Distributed Reinforcement Learning. We trained our agent in two stages: to move somewhere at the first stage and to follow the target velocity field at the second stage. We also introduce novel Q-function split technique, which we believe facilitates the task of training an agent, allows critic pretraining and reusing it for solving harder problems, and mitigate reward shaping design efforts.