 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Soft Actor-Critic with Multivariate Reward Representation and Knowledge Distillation
Paper and Code
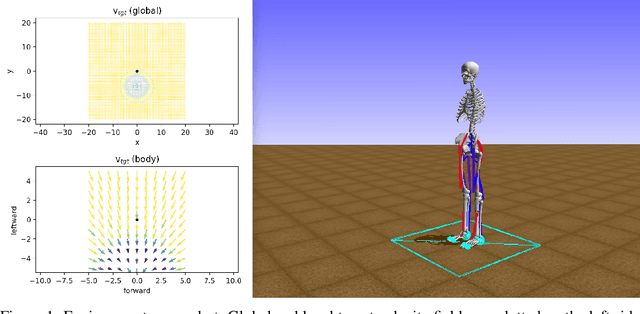
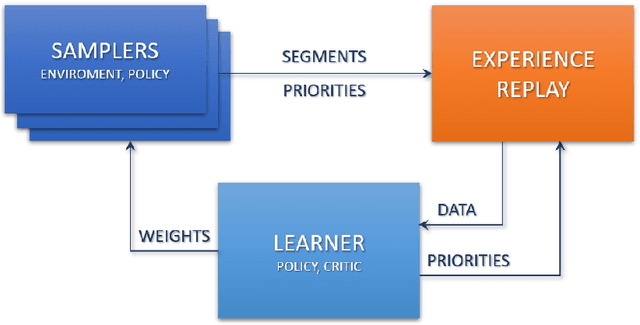
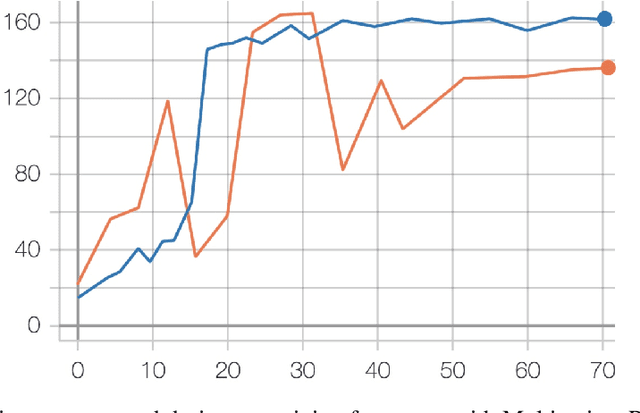
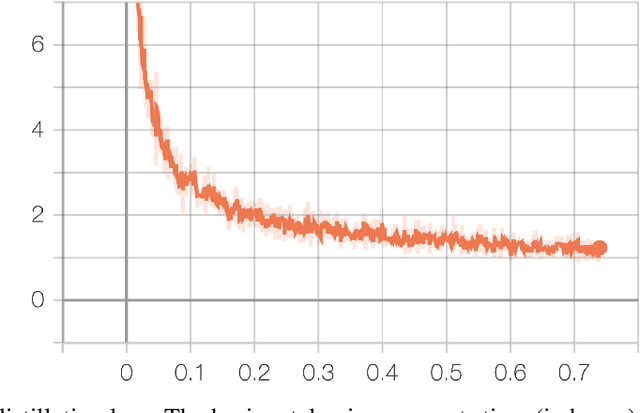
In this paper, we describe NeurIPS 2019 Learning to Move - Walk Around challenge physics-based environment and present our solution to this competition which scored 1303.727 mean reward points and took 3rd place. Our method combines recent advances from both continuous- and discrete-action space reinforcement learning, such as Soft Actor-Critic and Recurrent Experience Replay in Distributed Reinforcement Learning. We trained our agent in two stages: to move somewhere at the first stage and to follow the target velocity field at the second stage. We also introduce novel Q-function split technique, which we believe facilitates the task of training an agent, allows critic pretraining and reusing it for solving harder problems, and mitigate reward shaping design efforts.