 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntendre, a Social Bot Detection Tool for Niche, Fringe, and Extreme Social Media
Aug 13, 2024Social bots-automated accounts that generate and spread content on social media-are exploiting vulnerabilities in these platforms to manipulate public perception and disseminate disinformation. This has prompted the development of public bot detection services; however, most of these services focus primarily on Twitter, leaving niche platforms vulnerable. Fringe social media platforms such as Parler, Gab, and Gettr often have minimal moderation, which facilitates the spread of hate speech and misinformation. To address this gap, we introduce Entendre, an open-access, scalable, and platform-agnostic bot detection framework. Entendre can process a labeled dataset from any social platform to produce a tailored bot detection model using a random forest classification approach, ensuring robust social bot detection. We exploit the idea that most social platforms share a generic template, where users can post content, approve content, and provide a bio (common data features). By emphasizing general data features over platform-specific ones, Entendre offers rapid extensibility at the expense of some accuracy. To demonstrate Entendre's effectiveness, we used it to explore the presence of bots among accounts posting racist content on the now-defunct right-wing platform Parler. We examined 233,000 posts from 38,379 unique users and found that 1,916 unique users (4.99%) exhibited bot-like behavior. Visualization techniques further revealed that these bots significantly impacted the network, amplifying influential rhetoric and hashtags (e.g., #qanon, #trump, #antilgbt). These preliminary findings underscore the need for tools like Entendre to monitor and assess bot activity across diverse platforms.
Understanding Lexical Biases when Identifying Gang-related Social Media Communications
Apr 22, 2023

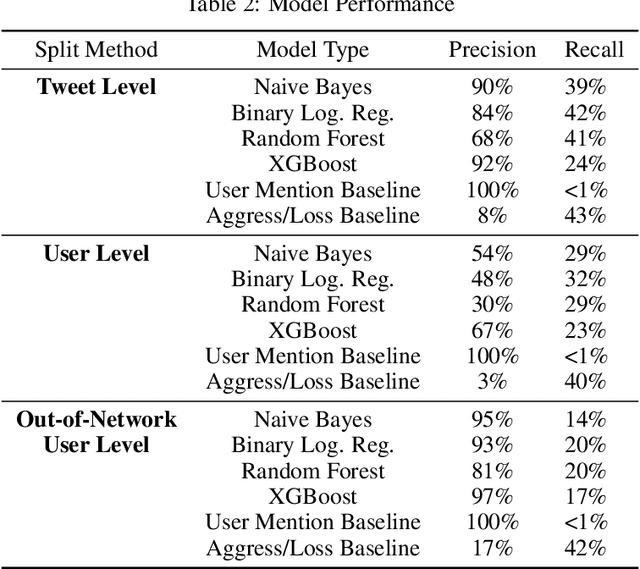
Individuals involved in gang-related activity use mainstream social media including Facebook and Twitter to express taunts and threats as well as grief and memorializing. However, identifying the impact of gang-related activity in order to serve community member needs through social media sources has a unique set of challenges. This includes the difficulty of ethically identifying training data of individuals impacted by gang activity and the need to account for a non-standard language style commonly used in the tweets from these individuals. Our study provides evidence of methods where natural language processing tools can be helpful in efficiently identifying individuals who may be in need of community care resources such as counselors, conflict mediators, or academic/professional training programs. We demonstrate that our binary logistic classifier outperforms baseline standards in identifying individuals impacted by gang-related violence using a sample of gang-related tweets associated with Chicago. We ultimately found that the language of a tweet is highly relevant and that uses of ``big data'' methods or machine learning models need to better understand how language impacts the model's performance and how it discriminates among populations.
Theme and Topic: How Qualitative Research and Topic Modeling Can Be Brought Together
Oct 03, 2022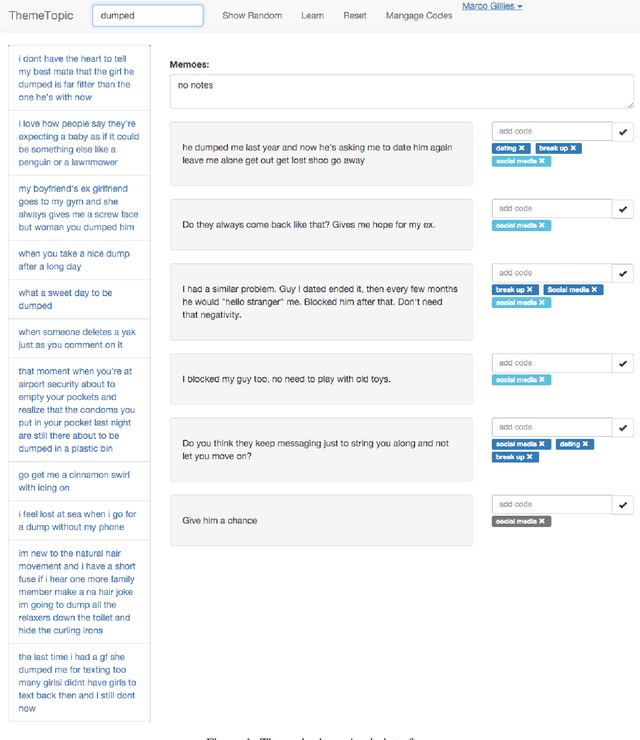
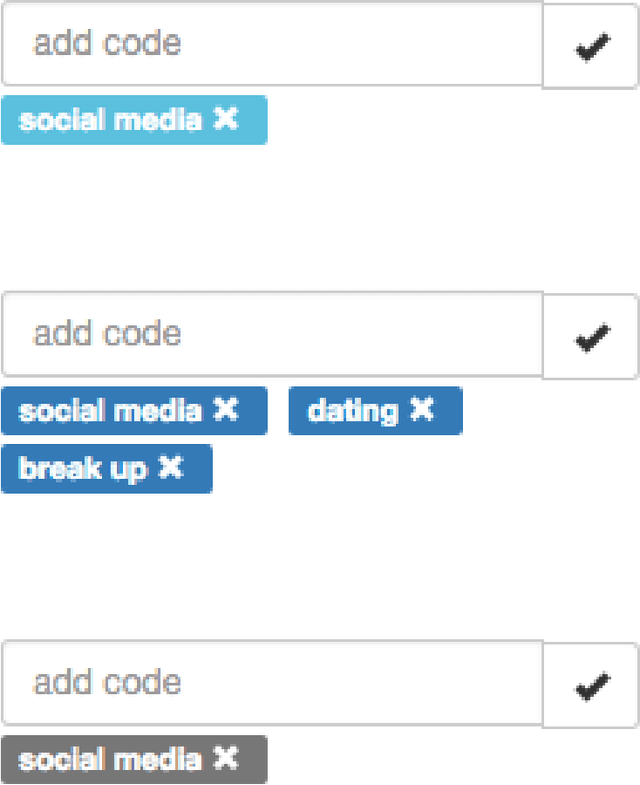
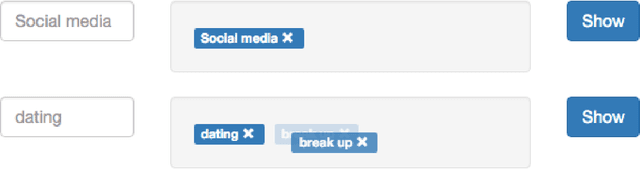
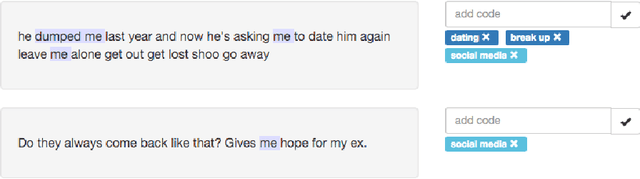
Qualitative research is an approach to understanding social phenomenon based around human interpretation of data, particularly text. Probabilistic topic modelling is a machine learning approach that is also based around the analysis of text and often is used to in order to understand social phenomena. Both of these approaches aim to extract important themes or topics in a textual corpus and therefore we may see them as analogous to each other. However there are also considerable differences in how the two approaches function. One is a highly human interpretive process, the other is automated and statistical. In this paper we use this analogy as the basis for our Theme and Topic system, a tool for qualitative researchers to conduct textual research that integrates topic modelling into an accessible interface. This is an example of a more general approach to the design of interactive machine learning systems in which existing human professional processes can be used as the model for processes involving machine learning. This has the particular benefit of providing a familiar approach to existing professionals, that may can make machine learning seem less alien and easier to learn. Our design approach has two elements. We first investigate the steps professionals go through when performing tasks and design a workflow for Theme and Topic that integrates machine learning. We then designed interfaces for topic modelling in which familiar concepts from qualitative research are mapped onto machine learning concepts. This makes these the machine learning concepts more familiar and easier to learn for qualitative researchers.
PoxVerifi: An Information Verification System to Combat Monkeypox Misinformation
Sep 09, 2022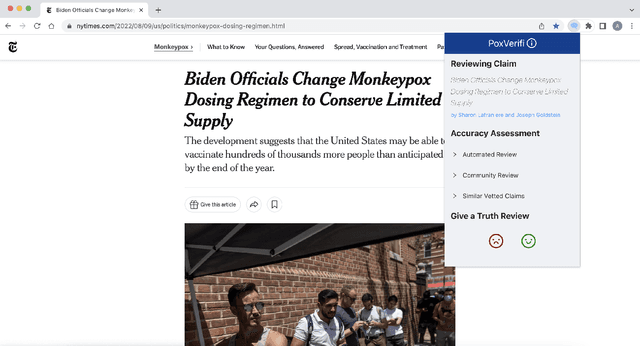
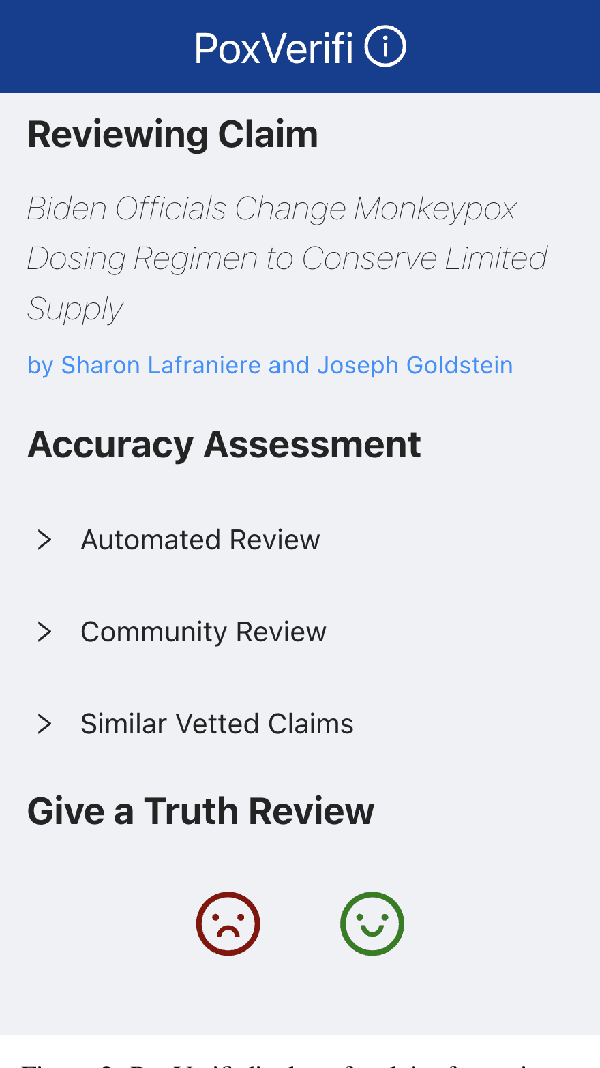

Following recent outbreaks, monkeypox-related misinformation continues to rapidly spread online. This negatively impacts response strategies and disproportionately harms LGBTQ+ communities in the short-term, and ultimately undermines the overall effectiveness of public health responses. In an attempt to combat monkeypox-related misinformation, we present PoxVerifi, an open-source, extensible tool that provides a comprehensive approach to assessing the accuracy of monkeypox related claims. Leveraging information from existing fact checking sources and published World Health Organization (WHO) information, we created an open-sourced corpus of 225 rated monkeypox claims. Additionally, we trained an open-sourced BERT-based machine learning model for specifically classifying monkeypox information, which achieved 96% cross-validation accuracy. PoxVerifi is a Google Chrome browser extension designed to empower users to navigate through monkeypox-related misinformation. Specifically, PoxVerifi provides users with a comprehensive toolkit to assess the veracity of headlines on any webpage across the Internet without having to visit an external site. Users can view an automated accuracy review from our trained machine learning model, a user-generated accuracy review based on community-member votes, and have the ability to see similar, vetted, claims. Besides PoxVerifi's comprehensive approach to claim-testing, our platform provides an efficient and accessible method to crowdsource accuracy ratings on monkeypox related-claims, which can be aggregated to create new labeled misinformation datasets.
An Information Retrieval Approach to Building Datasets for Hate Speech Detection
Jun 21, 2021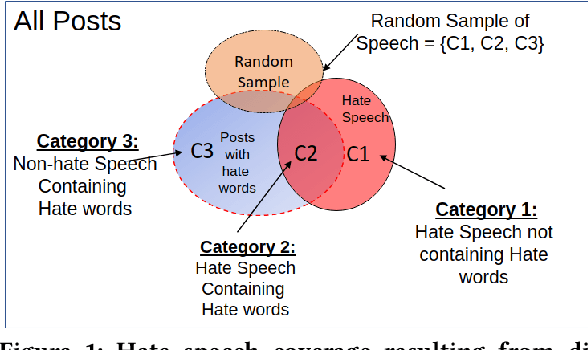

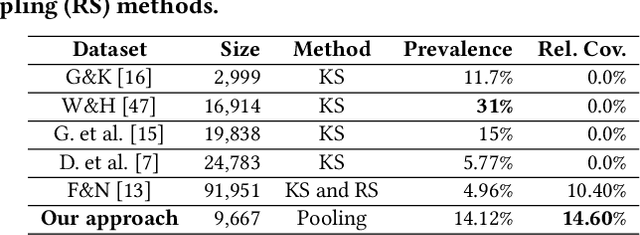
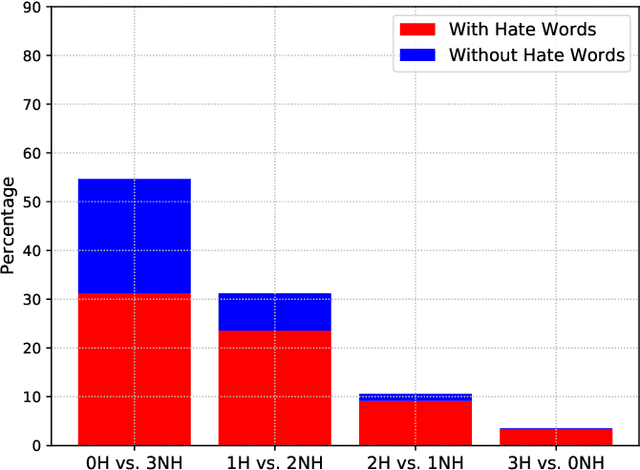
Building a benchmark dataset for hate speech detection presents several challenges. Firstly, because hate speech is relatively rare -- e.g., less than 3\% of Twitter posts are hateful \citep{founta2018large} -- random sampling of tweets to annotate is inefficient in capturing hate speech. A common practice is to only annotate tweets containing known ``hate words'', but this risks yielding a biased benchmark that only partially captures the real-world phenomenon of interest. A second challenge is that definitions of hate speech tend to be highly variable and subjective. Annotators having diverse prior notions of hate speech may not only disagree with one another but also struggle to conform to specified labeling guidelines. Our key insight is that the rarity and subjectivity of hate speech are akin to that of relevance in information retrieval (IR). This connection suggests that well-established methodologies for creating IR test collections might also be usefully applied to create better benchmark datasets for hate speech detection. Firstly, to intelligently and efficiently select which tweets to annotate, we apply established IR techniques of {\em pooling} and {\em active learning}. Secondly, to improve both consistency and value of annotations, we apply {\em task decomposition} \cite{Zhang-sigir14} and {\em annotator rationale} \cite{mcdonnell16-hcomp} techniques. Using the above techniques, we create and share a new benchmark dataset\footnote{We will release the dataset upon publication.} for hate speech detection with broader coverage than prior datasets. We also show a dramatic drop in accuracy of existing detection models when tested on these broader forms of hate. Collected annotator rationales not only provide documented support for labeling decisions but also create exciting future work opportunities for dual-supervision and/or explanation generation in modeling.