 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information Retrieval Approach to Building Datasets for Hate Speech Detection
Jun 21, 2021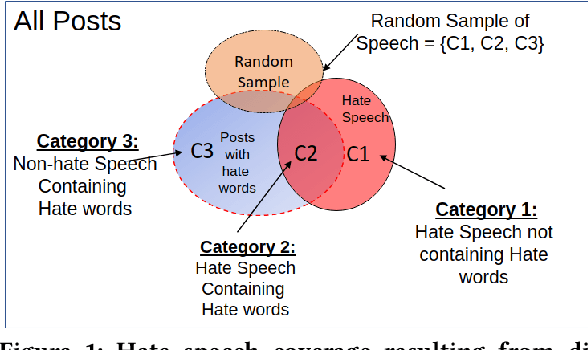

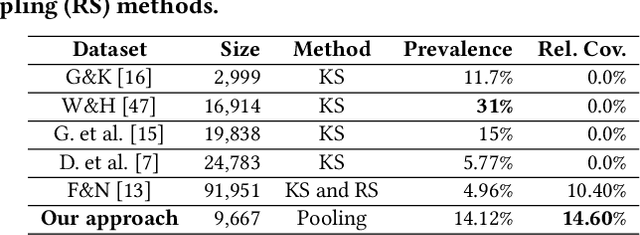
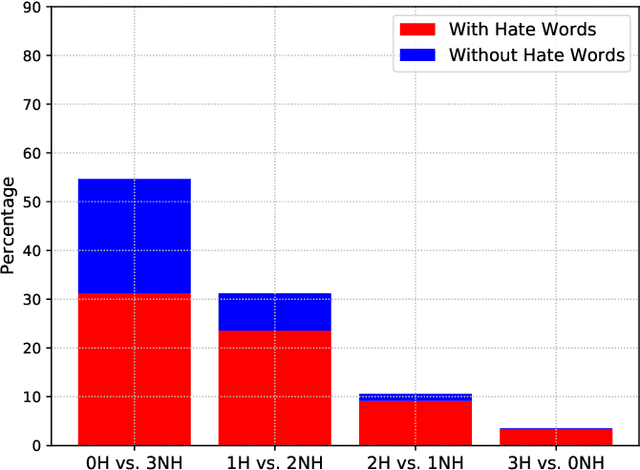
Building a benchmark dataset for hate speech detection presents several challenges. Firstly, because hate speech is relatively rare -- e.g., less than 3\% of Twitter posts are hateful \citep{founta2018large} -- random sampling of tweets to annotate is inefficient in capturing hate speech. A common practice is to only annotate tweets containing known ``hate words'', but this risks yielding a biased benchmark that only partially captures the real-world phenomenon of interest. A second challenge is that definitions of hate speech tend to be highly variable and subjective. Annotators having diverse prior notions of hate speech may not only disagree with one another but also struggle to conform to specified labeling guidelines. Our key insight is that the rarity and subjectivity of hate speech are akin to that of relevance in information retrieval (IR). This connection suggests that well-established methodologies for creating IR test collections might also be usefully applied to create better benchmark datasets for hate speech detection. Firstly, to intelligently and efficiently select which tweets to annotate, we apply established IR techniques of {\em pooling} and {\em active learning}. Secondly, to improve both consistency and value of annotations, we apply {\em task decomposition} \cite{Zhang-sigir14} and {\em annotator rationale} \cite{mcdonnell16-hcomp} techniques. Using the above techniques, we create and share a new benchmark dataset\footnote{We will release the dataset upon publication.} for hate speech detection with broader coverage than prior datasets. We also show a dramatic drop in accuracy of existing detection models when tested on these broader forms of hate. Collected annotator rationales not only provide documented support for labeling decisions but also create exciting future work opportunities for dual-supervision and/or explanation generation in modeling.
Understanding and Predicting the Characteristics of Test Collections
Dec 24, 2020
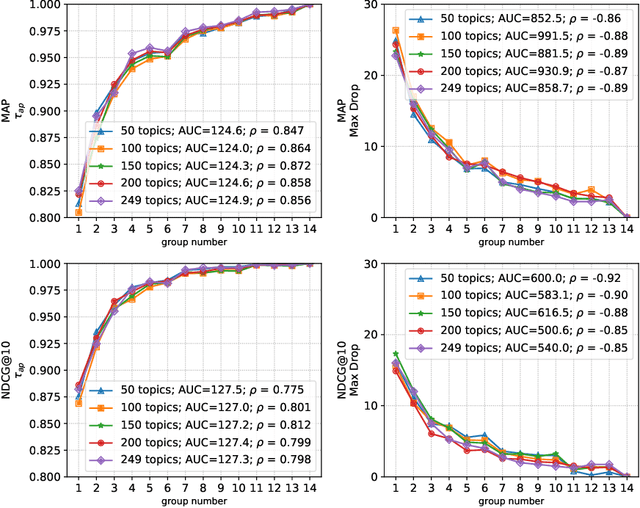
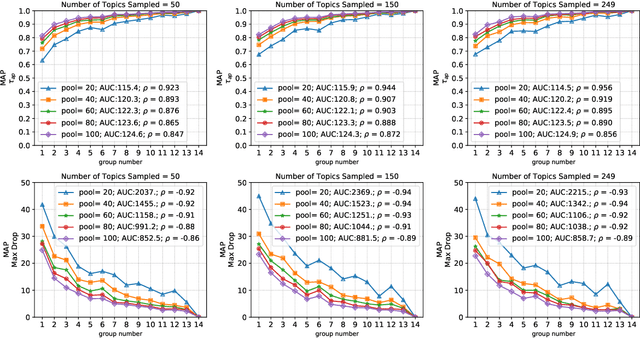
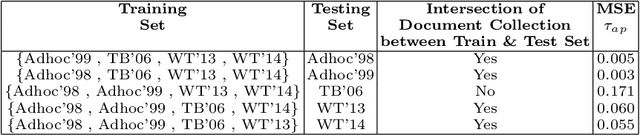
Shared-task campaigns such as NIST TREC select documents to judge by pooling rankings from many participant systems. Therefore, the quality of the test collection greatly depends on the number of participants and the quality of submitted runs. In this work, we investigate i) how the number of participants, coupled with other factors, affects the quality of a test collection; and ii) whether the quality of a test collection can be inferred prior to collecting relevance judgments. Experiments on six TREC collections demonstrate that the required number of participants to construct a high-quality test collection varies significantly across different test collections due to a variety of factors. Furthermore, results suggest that the quality of test collections can be predicted.