 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Analytic Classifiers with Associative Drift Compensation for Class-Incremental Learning of Vision Transformers
Jan 29, 2026Class-incremental learning (CIL) with Vision Transformers (ViTs) faces a major computational bottleneck during the classifier reconstruction phase, where most existing methods rely on costly iterative stochastic gradient descent (SGD). We observe that analytic Regularized Gaussian Discriminant Analysis (RGDA) provides a Bayes-optimal alternative with accuracy comparable to SGD-based classifiers; however, its quadratic inference complexity limits its use in large-scale CIL scenarios. To overcome this, we propose Low-Rank Factorized RGDA (LR-RGDA), a scalable classifier that combines RGDA's expressivity with the efficiency of linear classifiers. By exploiting the low-rank structure of the covariance via the Woodbury matrix identity, LR-RGDA decomposes the discriminant function into a global affine term refined by a low-rank quadratic perturbation, reducing the inference complexity from $\mathcal{O}(Cd^2)$ to $\mathcal{O}(d^2 + Crd^2)$, where $C$ is the class number, $d$ the feature dimension, and $r \ll d$ the subspace rank. To mitigate representation drift caused by backbone updates, we further introduce Hopfield-based Distribution Compensator (HopDC), a training-free mechanism that uses modern continuous Hopfield Networks to recalibrate historical class statistics through associative memory dynamics on unlabeled anchors, accompanied by a theoretical bound on the estimation error. Extensive experiments on diverse CIL benchmarks demonstrate that our framework achieves state-of-the-art performance, providing a scalable solution for large-scale class-incremental learning with ViTs. Code: https://github.com/raoxuan98-hash/lr_rgda_hopdc.
Compensating Distribution Drifts in Class-incremental Learning of Pre-trained Vision Transformers
Nov 13, 2025



Recent advances have shown that sequential fine-tuning (SeqFT) of pre-trained vision transformers (ViTs), followed by classifier refinement using approximate distributions of class features, can be an effective strategy for class-incremental learning (CIL). However, this approach is susceptible to distribution drift, caused by the sequential optimization of shared backbone parameters. This results in a mismatch between the distributions of the previously learned classes and that of the updater model, ultimately degrading the effectiveness of classifier performance over time. To address this issue, we introduce a latent space transition operator and propose Sequential Learning with Drift Compensation (SLDC). SLDC aims to align feature distributions across tasks to mitigate the impact of drift. First, we present a linear variant of SLDC, which learns a linear operator by solving a regularized least-squares problem that maps features before and after fine-tuning. Next, we extend this with a weakly nonlinear SLDC variant, which assumes that the ideal transition operator lies between purely linear and fully nonlinear transformations. This is implemented using learnable, weakly nonlinear mappings that balance flexibility and generalization. To further reduce representation drift, we apply knowledge distillation (KD) in both algorithmic variants. Extensive experiments on standard CIL benchmarks demonstrate that SLDC significantly improves the performance of SeqFT. Notably, by combining KD to address representation drift with SLDC to compensate distribution drift, SeqFT achieves performance comparable to joint training across all evaluated datasets. Code: https://github.com/raoxuan98-hash/sldc.git.
FX-DARTS: Designing Topology-unconstrained Architectures with Differentiable Architecture Search and Entropy-based Super-network Shrinking
Apr 25, 2025Strong priors are imposed on the search space of Differentiable Architecture Search (DARTS), such that cells of the same type share the same topological structure and each intermediate node retains two operators from distinct nodes. While these priors reduce optimization difficulties and improve the applicability of searched architectures, they hinder the subsequent development of automated machine learning (Auto-ML) and prevent the optimization algorithm from exploring more powerful neural networks through improved architectural flexibility. This paper aims to reduce these prior constraints by eliminating restrictions on cell topology and modifying the discretization mechanism for super-networks. Specifically, the Flexible DARTS (FX-DARTS) method, which leverages an Entropy-based Super-Network Shrinking (ESS) framework, is presented to address the challenges arising from the elimination of prior constraints. Notably, FX-DARTS enables the derivation of neural architectures without strict prior rules while maintaining the stability in the enlarged search space. Experimental results on image classification benchmarks demonstrate that FX-DARTS is capable of exploring a set of neural architectures with competitive trade-offs between performance and computational complexity within a single search procedure.
DNAD: Differentiable Neural Architecture Distillation
Apr 25, 2025To meet the demand for designing efficient neural networks with appropriate trade-offs between model performance (e.g., classification accuracy) and computational complexity, the differentiable neural architecture distillation (DNAD) algorithm is developed based on two cores, namely search by deleting and search by imitating. Primarily, to derive neural architectures in a space where cells of the same type no longer share the same topology, the super-network progressive shrinking (SNPS) algorithm is developed based on the framework of differentiable architecture search (DARTS), i.e., search by deleting. Unlike conventional DARTS-based approaches which yield neural architectures with simple structures and derive only one architecture during the search procedure, SNPS is able to derive a Pareto-optimal set of architectures with flexible structures by forcing the dynamic super-network shrink from a dense structure to a sparse one progressively. Furthermore, since knowledge distillation (KD) has shown great effectiveness to train a compact network with the assistance of an over-parameterized model, we integrate SNPS with KD to formulate the DNAD algorithm, i.e., search by imitating. By minimizing behavioral differences between the super-network and teacher network, the over-fitting of one-level DARTS is avoided and well-performed neural architectures are derived. Experiments on CIFAR-10 and ImageNet classification tasks demonstrate that both SNPS and DNAD are able to derive a set of architectures which achieve similar or lower error rates with fewer parameters and FLOPs. Particularly, DNAD achieves the top-1 error rate of 23.7% on ImageNet classification with a model of 6.0M parameters and 598M FLOPs, which outperforms most DARTS-based methods.
CR-LSO: Convex Neural Architecture Optimization in the Latent Space of Graph Variational Autoencoder with Input Convex Neural Networks
Nov 11, 2022



In neural architecture search (NAS) methods based on latent space optimization (LSO), a deep generative model is trained to embed discrete neural architectures into a continuous latent space. In this case, different optimization algorithms that operate in the continuous space can be implemented to search neural architectures. However, the optimization of latent variables is challenging for gradient-based LSO since the mapping from the latent space to the architecture performance is generally non-convex. To tackle this problem, this paper develops a convexity regularized latent space optimization (CR-LSO) method, which aims to regularize the learning process of latent space in order to obtain a convex architecture performance mapping. Specifically, CR-LSO trains a graph variational autoencoder (G-VAE) to learn the continuous representations of discrete architectures. Simultaneously, the learning process of latent space is regularized by the guaranteed convexity of input convex neural networks (ICNNs). In this way, the G-VAE is forced to learn a convex mapping from the architecture representation to the architecture performance. Hereafter, the CR-LSO approximates the performance mapping using the ICNN and leverages the estimated gradient to optimize neural architecture representations. Experimental results on three popular NAS benchmarks show that CR-LSO achieves competitive evaluation results in terms of both computational complexity and architecture performance.
Q-learning for Optimal Control of Continuous-time Systems
Oct 11, 2014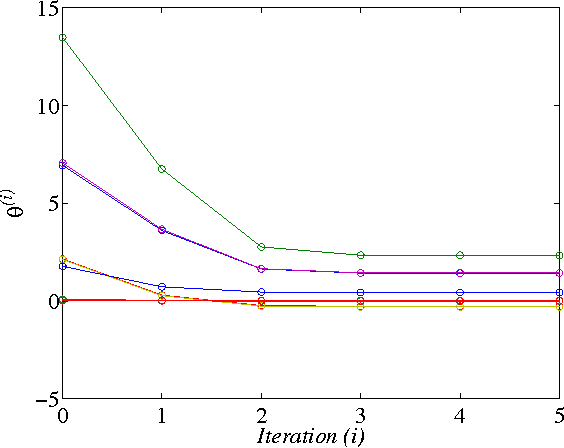
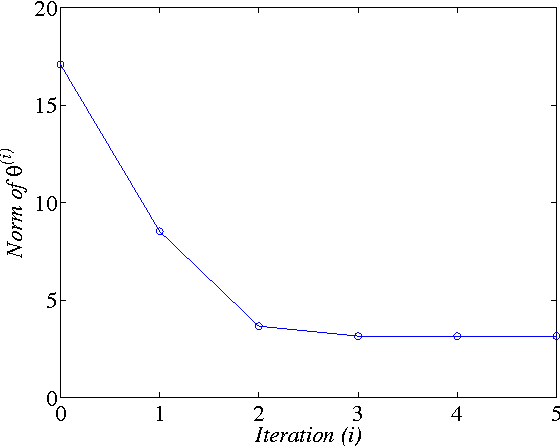
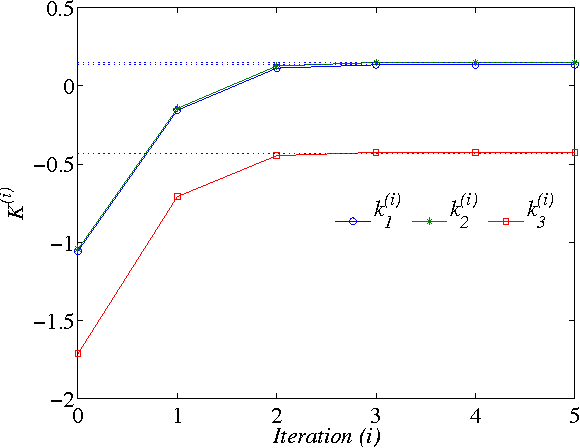
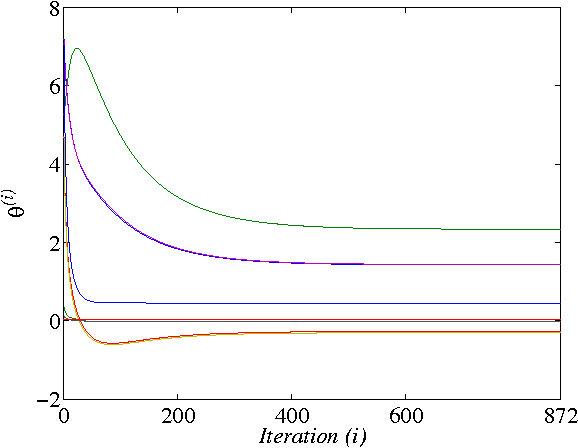
In this paper, two Q-learning (QL) methods are proposed and their convergence theories are established for addressing the model-free optimal control problem of general nonlinear continuous-time systems. By introducing the Q-function for continuous-time systems, policy iteration based QL (PIQL) and value iteration based QL (VIQL) algorithms are proposed for learning the optimal control policy from real system data rather than using mathematical system model. It is proved that both PIQL and VIQL methods generate a nonincreasing Q-function sequence, which converges to the optimal Q-function. For implementation of the QL algorithms, the method of weighted residuals is applied to derived the parameters update rule. The developed PIQL and VIQL algorithms are essentially off-policy reinforcement learning approachs, where the system data can be collected arbitrary and thus the exploration ability is increased. With the data collected from the real system, the QL methods learn the optimal control policy offline, and then the convergent control policy will be employed to real system. The effectiveness of the developed QL algorithms are verified through computer simulation.
Data-based approximate policy iteration for nonlinear continuous-time optimal control design
Nov 02, 2013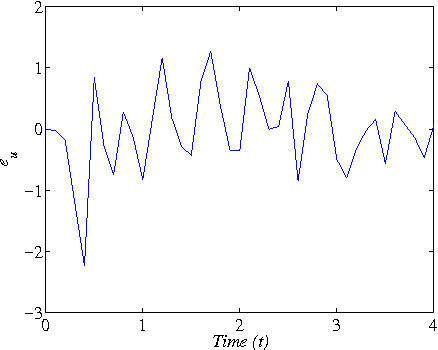
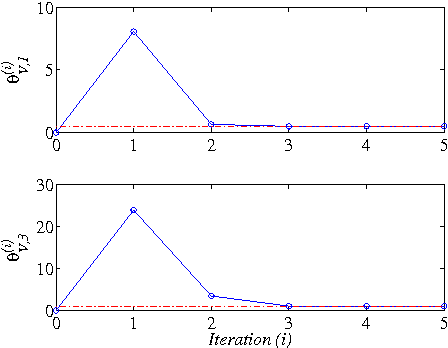
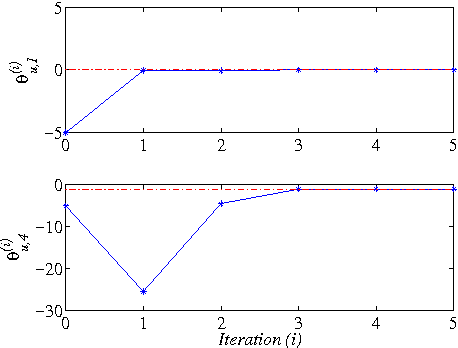
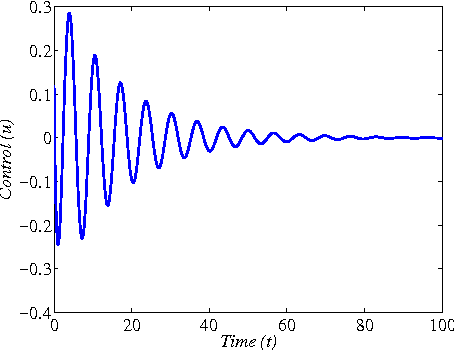
This paper addresses the model-free nonlinear optimal problem with generalized cost functional, and a data-based reinforcement learning technique is developed. It is known that the nonlinear optimal control problem relies on the solution of the Hamilton-Jacobi-Bellman (HJB) equation, which is a nonlinear partial differential equation that is generally impossible to be solved analytically. Even worse, most of practical systems are too complicated to establish their accurate mathematical model. To overcome these difficulties, we propose a data-based approximate policy iteration (API) method by using real system data rather than system model. Firstly, a model-free policy iteration algorithm is derived for constrained optimal control problem and its convergence is proved, which can learn the solution of HJB equation and optimal control policy without requiring any knowledge of system mathematical model. The implementation of the algorithm is based on the thought of actor-critic structure, where actor and critic neural networks (NNs) are employed to approximate the control policy and cost function, respectively. To update the weights of actor and critic NNs, a least-square approach is developed based on the method of weighted residuals. The whole data-based API method includes two parts, where the first part is implemented online to collect real system information, and the second part is conducting offline policy iteration to learn the solution of HJB equation and the control policy. Then, the data-based API algorithm is simplified for solving unconstrained optimal control problem of nonlinear and linear systems. Finally, we test the efficiency of the data-based API control design method on a simple nonlinear system, and further apply it to a rotational/translational actuator system. The simulation results demonstrate the effectiveness of the proposed method.