 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecc-DRL: a Convex Combined Deep Reinforcement Learning Flight Control Design for a Morphing Quadrotor
Aug 23, 2024
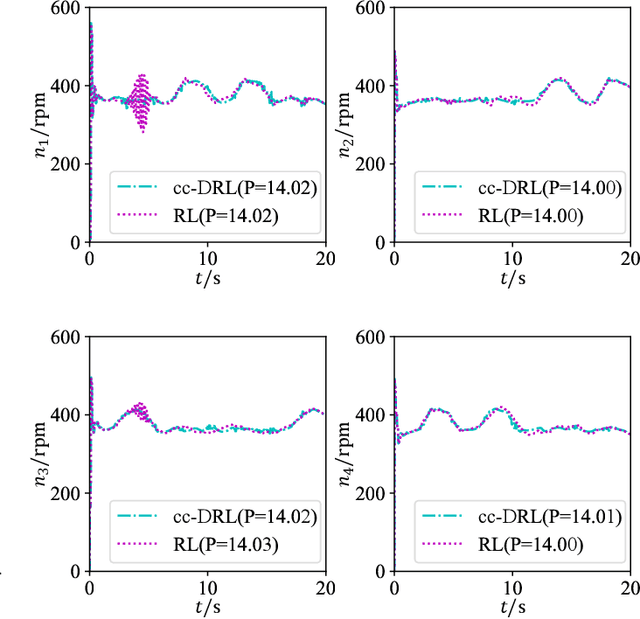


In comparison to common quadrotors, the shape change of morphing quadrotors endows it with a more better flight performance but also results in more complex flight dynamics. Generally, it is extremely difficult or even impossible for morphing quadrotors to establish an accurate mathematical model describing their complex flight dynamics. To figure out the issue of flight control design for morphing quadrotors, this paper resorts to a combination of model-free control techniques (e.g., deep reinforcement learning, DRL) and convex combination (CC) technique, and proposes a convex-combined-DRL (cc-DRL) flight control algorithm for position and attitude of a class of morphing quadrotors, where the shape change is realized by the length variation of four arm rods. In the proposed cc-DRL flight control algorithm, proximal policy optimization algorithm that is a model-free DRL algorithm is utilized to off-line train the corresponding optimal flight control laws for some selected representative arm length modes and hereby a cc-DRL flight control scheme is constructed by the convex combination technique. Finally, simulation results are presented to show the effectiveness and merit of the proposed flight control algorithm.
Off-policy reinforcement learning for $ H_\infty $ control design
May 11, 2014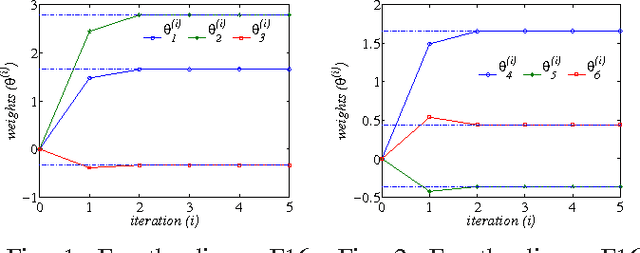
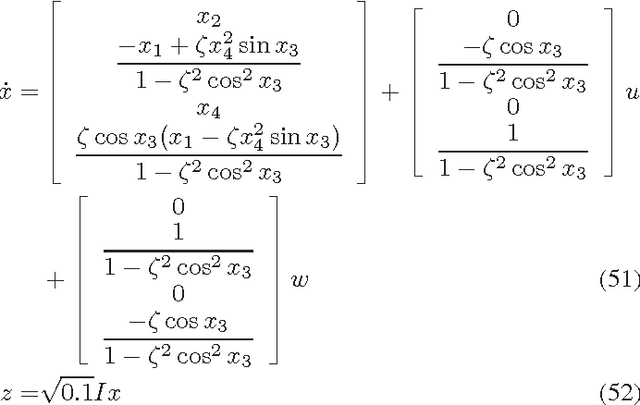
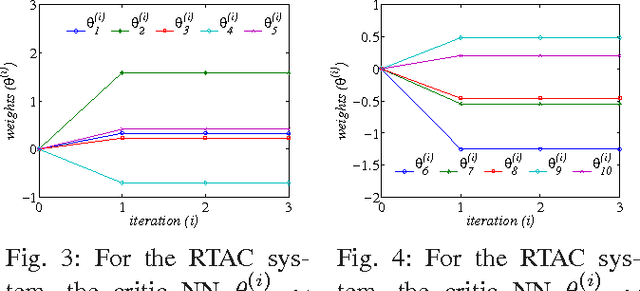
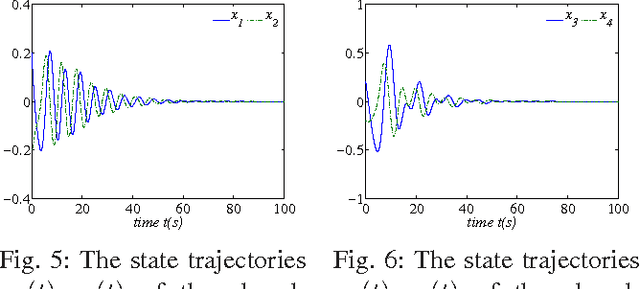
The $H_\infty$ control design problem is considered for nonlinear systems with unknown internal system model. It is known that the nonlinear $ H_\infty $ control problem can be transformed into solving the so-called Hamilton-Jacobi-Isaacs (HJI) equation, which is a nonlinear partial differential equation that is generally impossible to be solved analytically. Even worse, model-based approaches cannot be used for approximately solving HJI equation, when the accurate system model is unavailable or costly to obtain in practice. To overcome these difficulties, an off-policy reinforcement leaning (RL) method is introduced to learn the solution of HJI equation from real system data instead of mathematical system model, and its convergence is proved. In the off-policy RL method, the system data can be generated with arbitrary policies rather than the evaluating policy, which is extremely important and promising for practical systems. For implementation purpose, a neural network (NN) based actor-critic structure is employed and a least-square NN weight update algorithm is derived based on the method of weighted residuals. Finally, the developed NN-based off-policy RL method is tested on a linear F16 aircraft plant, and further applied to a rotational/translational actuator system.
Data-based approximate policy iteration for nonlinear continuous-time optimal control design
Nov 02, 2013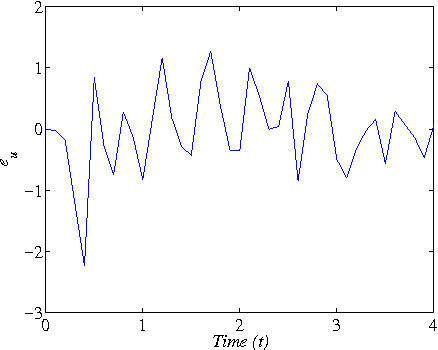
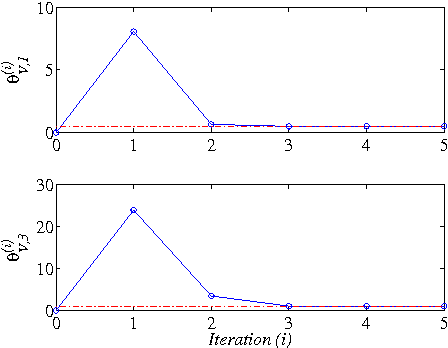
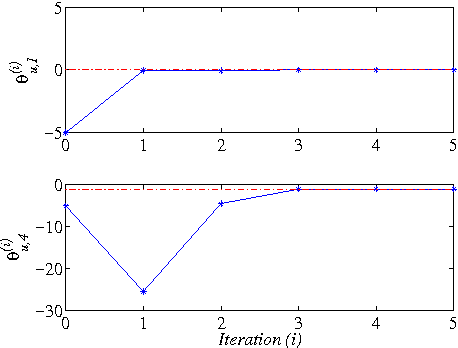
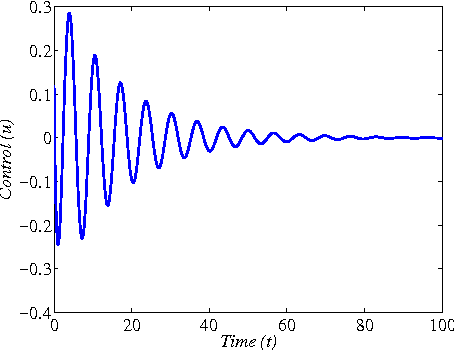
This paper addresses the model-free nonlinear optimal problem with generalized cost functional, and a data-based reinforcement learning technique is developed. It is known that the nonlinear optimal control problem relies on the solution of the Hamilton-Jacobi-Bellman (HJB) equation, which is a nonlinear partial differential equation that is generally impossible to be solved analytically. Even worse, most of practical systems are too complicated to establish their accurate mathematical model. To overcome these difficulties, we propose a data-based approximate policy iteration (API) method by using real system data rather than system model. Firstly, a model-free policy iteration algorithm is derived for constrained optimal control problem and its convergence is proved, which can learn the solution of HJB equation and optimal control policy without requiring any knowledge of system mathematical model. The implementation of the algorithm is based on the thought of actor-critic structure, where actor and critic neural networks (NNs) are employed to approximate the control policy and cost function, respectively. To update the weights of actor and critic NNs, a least-square approach is developed based on the method of weighted residuals. The whole data-based API method includes two parts, where the first part is implemented online to collect real system information, and the second part is conducting offline policy iteration to learn the solution of HJB equation and the control policy. Then, the data-based API algorithm is simplified for solving unconstrained optimal control problem of nonlinear and linear systems. Finally, we test the efficiency of the data-based API control design method on a simple nonlinear system, and further apply it to a rotational/translational actuator system. The simulation results demonstrate the effectiveness of the proposed method.