 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Estimation of Anatomical Risk Metrics for Endoscopic Sinus Surgery Using Deep Learning
Nov 10, 2025Endoscopic sinus surgery requires careful preoperative assessment of the skull base anatomy to minimize risks such as cerebrospinal fluid leakage. Anatomical risk scores like the Keros, Gera and Thailand-Malaysia-Singapore score offer a standardized approach but require time-consuming manual measurements on coronal CT or CBCT scans. We propose an automated deep learning pipeline that estimates these risk scores by localizing key anatomical landmarks via heatmap regression. We compare a direct approach to a specialized global-to-local learning strategy and find mean absolute errors on the relevant anatomical measurements of 0.506mm for the Keros, 4.516° for the Gera and 0.802mm / 0.777mm for the TMS classification.
Self-supervised learning for classifying paranasal anomalies in the maxillary sinus
Apr 29, 2024Purpose: Paranasal anomalies, frequently identified in routine radiological screenings, exhibit diverse morphological characteristics. Due to the diversity of anomalies, supervised learning methods require large labelled dataset exhibiting diverse anomaly morphology. Self-supervised learning (SSL) can be used to learn representations from unlabelled data. However, there are no SSL methods designed for the downstream task of classifying paranasal anomalies in the maxillary sinus (MS). Methods: Our approach uses a 3D Convolutional Autoencoder (CAE) trained in an unsupervised anomaly detection (UAD) framework. Initially, we train the 3D CAE to reduce reconstruction errors when reconstructing normal maxillary sinus (MS) image. Then, this CAE is applied to an unlabelled dataset to generate coarse anomaly locations by creating residual MS images. Following this, a 3D Convolutional Neural Network (CNN) reconstructs these residual images, which forms our SSL task. Lastly, we fine-tune the encoder part of the 3D CNN on a labelled dataset of normal and anomalous MS images. Results: The proposed SSL technique exhibits superior performance compared to existing generic self-supervised methods, especially in scenarios with limited annotated data. When trained on just 10% of the annotated dataset, our method achieves an Area Under the Precision-Recall Curve (AUPRC) of 0.79 for the downstream classification task. This performance surpasses other methods, with BYOL attaining an AUPRC of 0.75, SimSiam at 0.74, SimCLR at 0.73 and Masked Autoencoding using SparK at 0.75. Conclusion: A self-supervised learning approach that inherently focuses on localizing paranasal anomalies proves to be advantageous, particularly when the subsequent task involves differentiating normal from anomalous maxillary sinuses. Access our code at https://github.com/mtec-tuhh/self-supervised-paranasal-anomaly
Tissue Classification During Needle Insertion Using Self-Supervised Contrastive Learning and Optical Coherence Tomography
Apr 26, 2023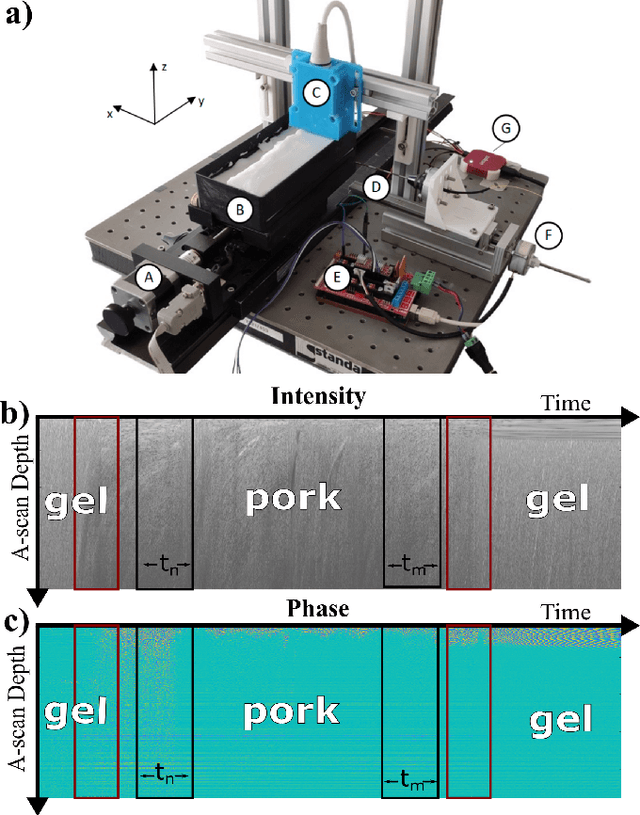
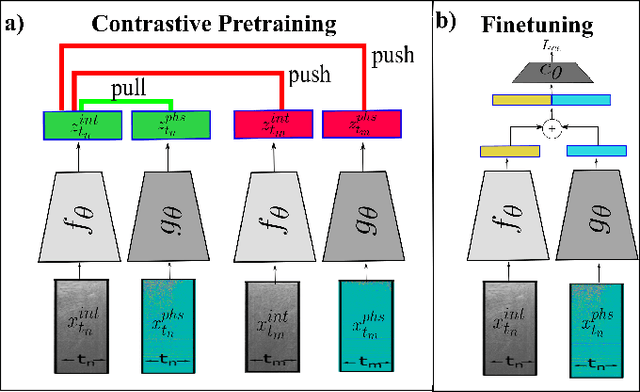
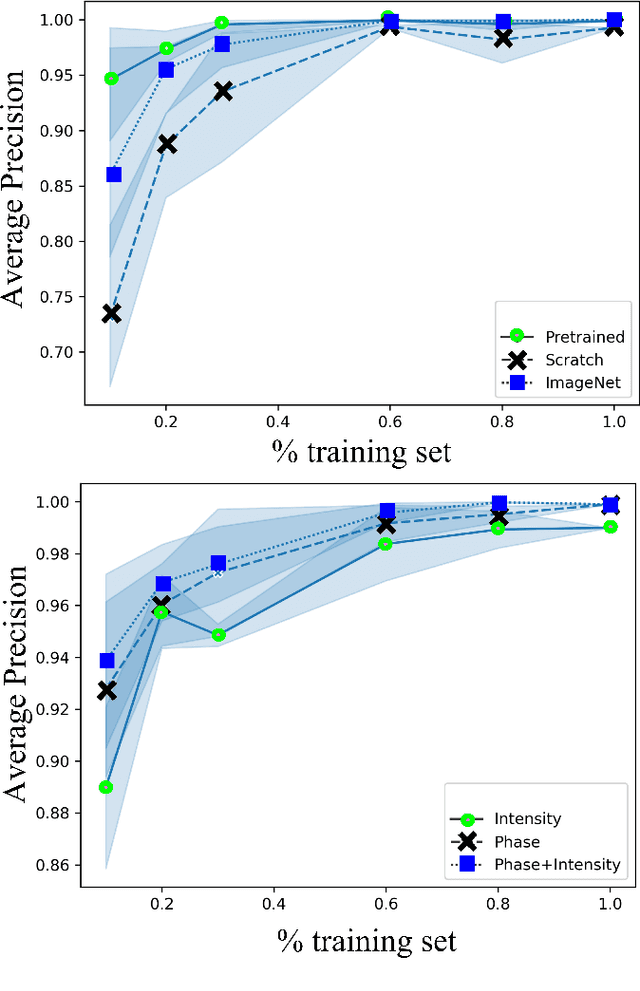
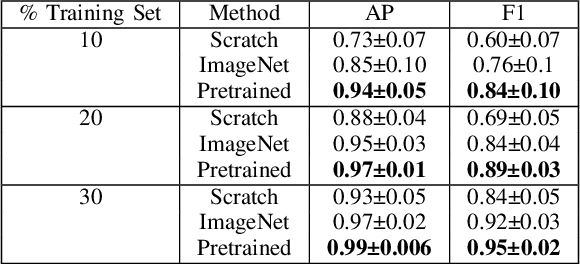
Needle positioning is essential for various medical applications such as epidural anaesthesia. Physicians rely on their instincts while navigating the needle in epidural spaces. Thereby, identifying the tissue structures may be helpful to the physician as they can provide additional feedback in the needle insertion process. To this end, we propose a deep neural network that classifies the tissues from the phase and intensity data of complex OCT signals acquired at the needle tip. We investigate the performance of the deep neural network in a limited labelled dataset scenario and propose a novel contrastive pretraining strategy that learns invariant representation for phase and intensity data. We show that with 10% of the training set, our proposed pretraining strategy helps the model achieve an F1 score of 0.84 whereas the model achieves an F1 score of 0.60 without it. Further, we analyse the importance of phase and intensity individually towards tissue classification.
Multiple Instance Ensembling For Paranasal Anomaly Classification In The Maxillary Sinus
Mar 31, 2023Paranasal anomalies are commonly discovered during routine radiological screenings and can present with a wide range of morphological features. This diversity can make it difficult for convolutional neural networks (CNNs) to accurately classify these anomalies, especially when working with limited datasets. Additionally, current approaches to paranasal anomaly classification are constrained to identifying a single anomaly at a time. These challenges necessitate the need for further research and development in this area. In this study, we investigate the feasibility of using a 3D convolutional neural network (CNN) to classify healthy maxillary sinuses (MS) and MS with polyps or cysts. The task of accurately identifying the relevant MS volume within larger head and neck Magnetic Resonance Imaging (MRI) scans can be difficult, but we develop a straightforward strategy to tackle this challenge. Our end-to-end solution includes the use of a novel sampling technique that not only effectively localizes the relevant MS volume, but also increases the size of the training dataset and improves classification results. Additionally, we employ a multiple instance ensemble prediction method to further boost classification performance. Finally, we identify the optimal size of MS volumes to achieve the highest possible classification performance on our dataset. With our multiple instance ensemble prediction strategy and sampling strategy, our 3D CNNs achieve an F1 of 0.85 whereas without it, they achieve an F1 of 0.70. We demonstrate the feasibility of classifying anomalies in the MS. We propose a data enlarging strategy alongside a novel ensembling strategy that proves to be beneficial for paranasal anomaly classification in the MS.
Unsupervised Anomaly Detection of Paranasal Anomalies in the Maxillary Sinus
Nov 01, 2022Deep learning (DL) algorithms can be used to automate paranasal anomaly detection from Magnetic Resonance Imaging (MRI). However, previous works relied on supervised learning techniques to distinguish between normal and abnormal samples. This method limits the type of anomalies that can be classified as the anomalies need to be present in the training data. Further, many data points from normal and anomaly class are needed for the model to achieve satisfactory classification performance. However, experienced clinicians can segregate between normal samples (healthy maxillary sinus) and anomalous samples (anomalous maxillary sinus) after looking at a few normal samples. We mimic the clinicians ability by learning the distribution of healthy maxillary sinuses using a 3D convolutional auto-encoder (cAE) and its variant, a 3D variational autoencoder (VAE) architecture and evaluate cAE and VAE for this task. Concretely, we pose the paranasal anomaly detection as an unsupervised anomaly detection problem. Thereby, we are able to reduce the labelling effort of the clinicians as we only use healthy samples during training. Additionally, we can classify any type of anomaly that differs from the training distribution. We train our 3D cAE and VAE to learn a latent representation of healthy maxillary sinus volumes using L1 reconstruction loss. During inference, we use the reconstruction error to classify between normal and anomalous maxillary sinuses. We extract sub-volumes from larger head and neck MRIs and analyse the effect of different fields of view on the detection performance. Finally, we report which anomalies are easiest and hardest to classify using our approach. Our results demonstrate the feasibility of unsupervised detection of paranasal anomalies from MRIs with an AUPRC of 85% and 80% for cAE and VAE, respectively.
Supervised Contrastive Learning to Classify Paranasal Anomalies in the Maxillary Sinus
Sep 05, 2022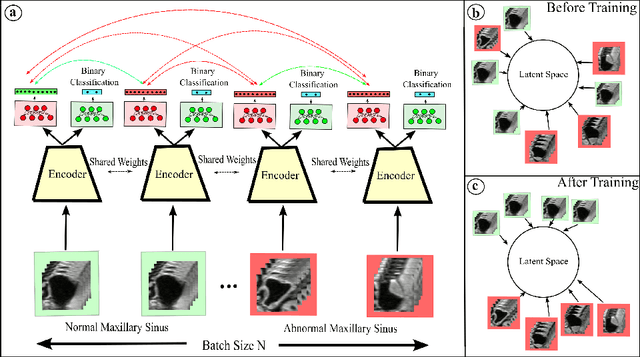
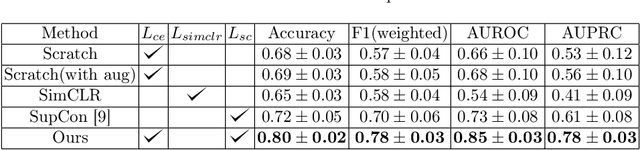
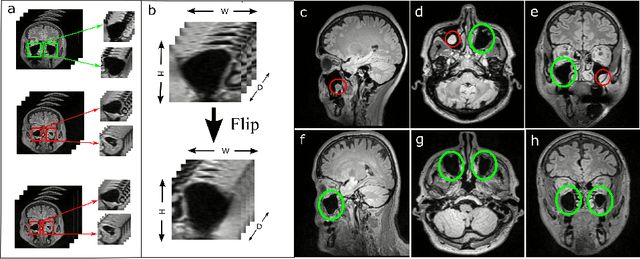
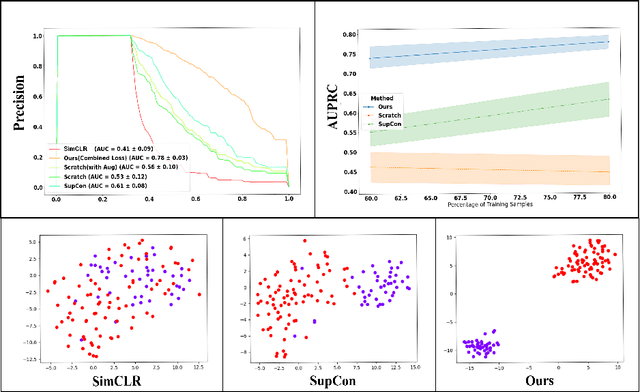
Using deep learning techniques, anomalies in the paranasal sinus system can be detected automatically in MRI images and can be further analyzed and classified based on their volume, shape and other parameters like local contrast. However due to limited training data, traditional supervised learning methods often fail to generalize. Existing deep learning methods in paranasal anomaly classification have been used to diagnose at most one anomaly. In our work, we consider three anomalies. Specifically, we employ a 3D CNN to separate maxillary sinus volumes without anomalies from maxillary sinus volumes with anomalies. To learn robust representations from a small labelled dataset, we propose a novel learning paradigm that combines contrastive loss and cross-entropy loss. Particularly, we use a supervised contrastive loss that encourages embeddings of maxillary sinus volumes with and without anomaly to form two distinct clusters while the cross-entropy loss encourages the 3D CNN to maintain its discriminative ability. We report that optimising with both losses is advantageous over optimising with only one loss. We also find that our training strategy leads to label efficiency. With our method, a 3D CNN classifier achieves an AUROC of 0.85 while a 3D CNN classifier optimised with cross-entropy loss achieves an AUROC of 0.66.
Self-Supervised U-Net for Segmenting Flat and Sessile Polyps
Oct 17, 2021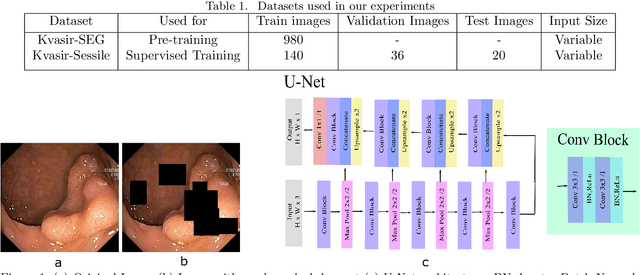
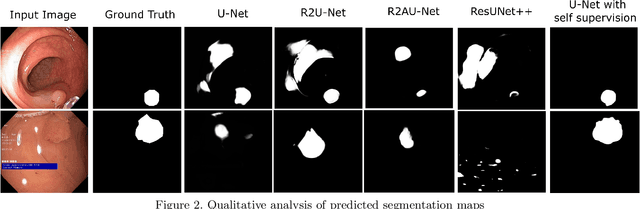
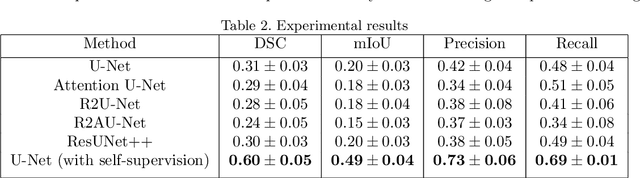
Colorectal Cancer(CRC) poses a great risk to public health. It is the third most common cause of cancer in the US. Development of colorectal polyps is one of the earliest signs of cancer. Early detection and resection of polyps can greatly increase survival rate to 90%. Manual inspection can cause misdetections because polyps vary in color, shape, size and appearance. To this end, Computer-Aided Diagnosis systems(CADx) has been proposed that detect polyps by processing the colonoscopic videos. The system acts a secondary check to help clinicians reduce misdetections so that polyps may be resected before they transform to cancer. Polyps vary in color, shape, size, texture and appearance. As a result, the miss rate of polyps is between 6% and 27% despite the prominence of CADx solutions. Furthermore, sessile and flat polyps which have diameter less than 10 mm are more likely to be undetected. Convolutional Neural Networks(CNN) have shown promising results in polyp segmentation. However, all of these works have a supervised approach and are limited by the size of the dataset. It was observed that smaller datasets reduce the segmentation accuracy of ResUNet++. We train a U-Net to inpaint randomly dropped out pixels in the image as a proxy task. The dataset we use for pre-training is Kvasir-SEG dataset. This is followed by a supervised training on the limited Kvasir-Sessile dataset. Our experimental results demonstrate that with limited annotated dataset and a larger unlabeled dataset, self-supervised approach is a better alternative than fully supervised approach. Specifically, our self-supervised U-Net performs better than five segmentation models which were trained in supervised manner on the Kvasir-Sessile dataset.
Spectral-Spatial Recurrent-Convolutional Networks for In-Vivo Hyperspectral Tumor Type Classification
Jul 02, 2020
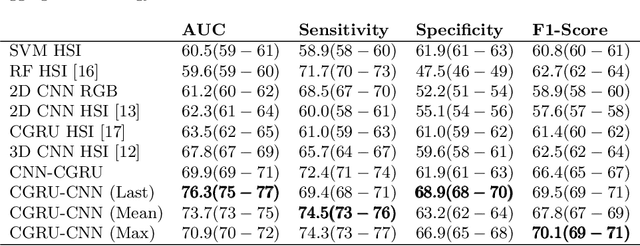
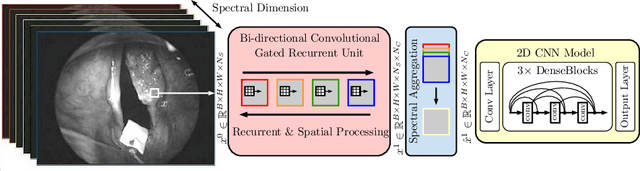
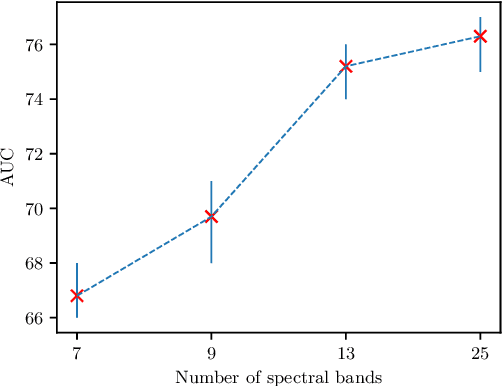
Early detection of cancerous tissue is crucial for long-term patient survival. In the head and neck region, a typical diagnostic procedure is an endoscopic intervention where a medical expert manually assesses tissue using RGB camera images. While healthy and tumor regions are generally easier to distinguish, differentiating benign and malignant tumors is very challenging. This requires an invasive biopsy, followed by histological evaluation for diagnosis. Also, during tumor resection, tumor margins need to be verified by histological analysis. To avoid unnecessary tissue resection, a non-invasive, image-based diagnostic tool would be very valuable. Recently, hyperspectral imaging paired with deep learning has been proposed for this task, demonstrating promising results on ex-vivo specimens. In this work, we demonstrate the feasibility of in-vivo tumor type classification using hyperspectral imaging and deep learning. We analyze the value of using multiple hyperspectral bands compared to conventional RGB images and we study several machine learning models' ability to make use of the additional spectral information. Based on our insights, we address spectral and spatial processing using recurrent-convolutional models for effective spectral aggregating and spatial feature learning. Our best model achieves an AUC of 76.3%, significantly outperforming previous conventional and deep learning methods.
Spatio-spectral deep learning methods for in-vivo hyperspectral laryngeal cancer detection
Apr 21, 2020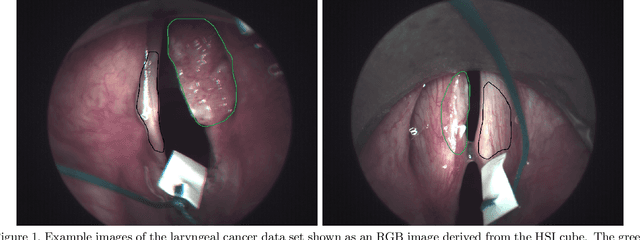

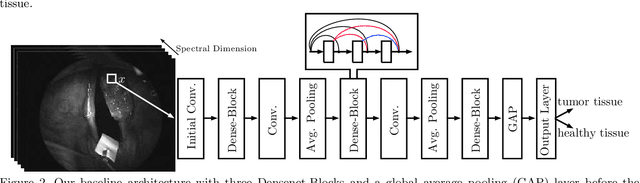
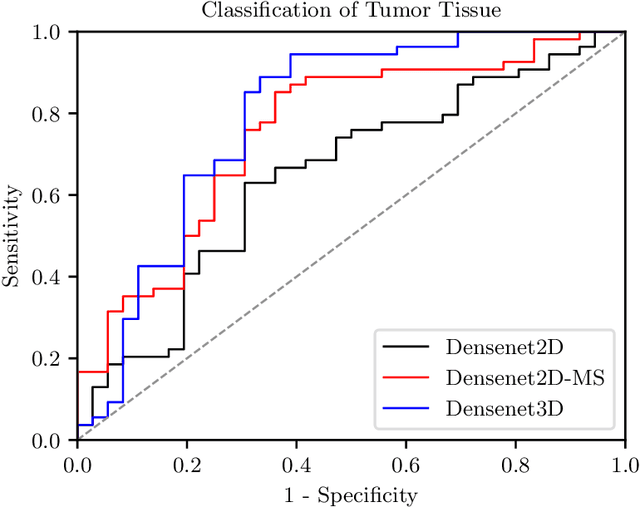
Early detection of head and neck tumors is crucial for patient survival. Often, diagnoses are made based on endoscopic examination of the larynx followed by biopsy and histological analysis, leading to a high inter-observer variability due to subjective assessment. In this regard, early non-invasive diagnostics independent of the clinician would be a valuable tool. A recent study has shown that hyperspectral imaging (HSI) can be used for non-invasive detection of head and neck tumors, as precancerous or cancerous lesions show specific spectral signatures that distinguish them from healthy tissue. However, HSI data processing is challenging due to high spectral variations, various image interferences, and the high dimensionality of the data. Therefore, performance of automatic HSI analysis has been limited and so far, mostly ex-vivo studies have been presented with deep learning. In this work, we analyze deep learning techniques for in-vivo hyperspectral laryngeal cancer detection. For this purpose we design and evaluate convolutional neural networks (CNNs) with 2D spatial or 3D spatio-spectral convolutions combined with a state-of-the-art Densenet architecture. For evaluation, we use an in-vivo data set with HSI of the oral cavity or oropharynx. Overall, we present multiple deep learning techniques for in-vivo laryngeal cancer detection based on HSI and we show that jointly learning from the spatial and spectral domain improves classification accuracy notably. Our 3D spatio-spectral Densenet achieves an average accuracy of 81%.