Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021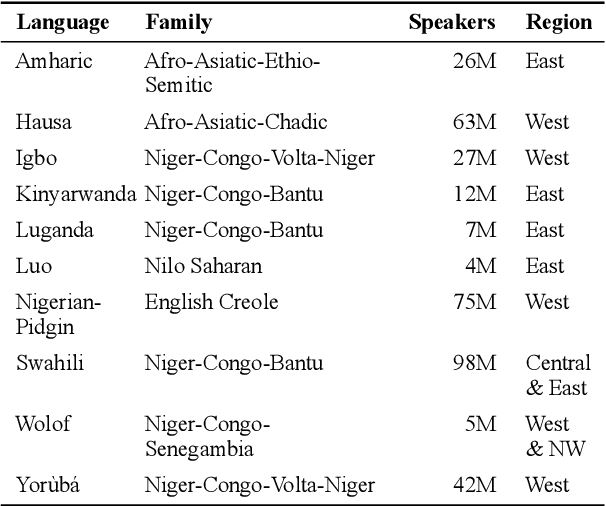

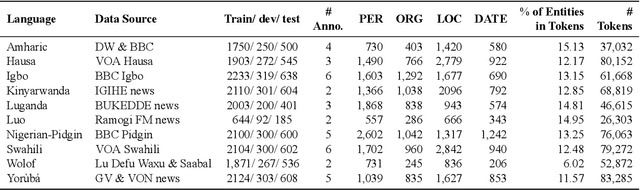
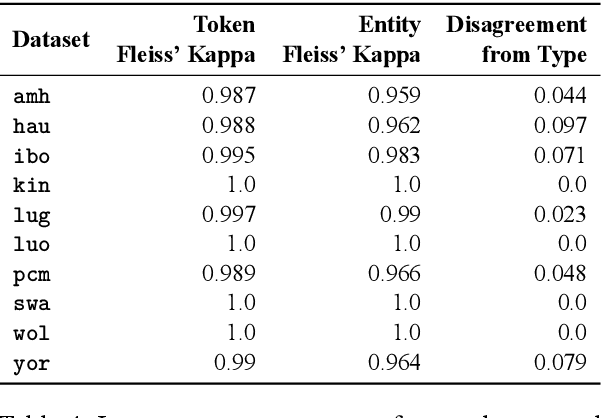
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
* Accepted at the AfricaNLP Workshop @EACL 2021
Via